Hive之窗口函数
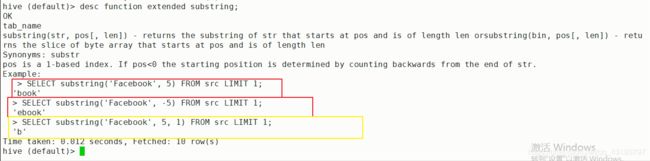
1.substring的用法:
2.数据准备:name,orderdate,cost
jack,2017-01-01,10
tony,2017-01-02,15
jack,2017-02-03,23
tony,2017-01-04,29
jack,2017-01-05,46
jack,2017-04-06,42
tony,2017-01-07,50
jack,2017-01-08,55
mart,2017-04-08,62
mart,2017-04-09,68
neil,2017-05-10,12
mart,2017-04-11,75
neil,2017-06-12,80
mart,2017-04-13,94
3.需求
- ) 查询在2017年4月份购买过的顾客及总人数
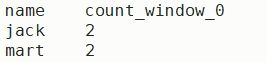
相当于扩大窗口,分组后,统计分组总组数
select name,count(name) over()
from business
where substring(orderdate,6,2)='04'
group by name
count这种聚集函数,统计数据的范围是整个组!
需要使用窗口函数!
窗口函数,是辅助聚合函数工作!窗口函数的作用就是,指定当前的聚合函数,工作的范围大小!
窗口函数通过over()定义: ()中,可以通过参数,来指定窗口的大小!,如果没有指定,那么窗口大小默认为整个数据集!
over(partition by 字段 order by 字段 )
name,orderdate,cost: 直接扫描一行获取即可!
sum(cost) : 需要计算的是同一个人,同一个月,消费的cost总额! sum(cost)在计算时的窗口至少是多个行!
(2)查询顾客的购买明细及月购买总额
要求结果如下:
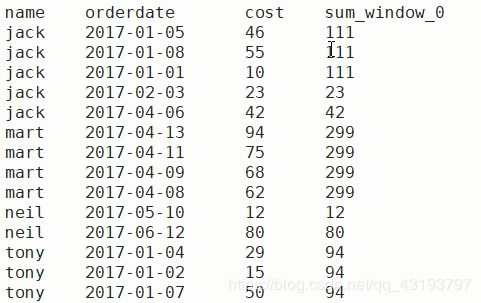
只有over(partition by xxx)时,窗口的大小默认是整个区!
select name,orderdate,cost,sum(cost) over(partition by name,month(orderdate) order by orderdate rows between UNBOUNDED PRECEDING and UNBOUNDED FOLLOWING)
from business
有order by 没有指定windows子句(少rows...)默认窗口是上无边界到当前行!
也就是当查询语句为 select name,orderdate,cost,sum(cost) over(partition by name,month(orderdate) order by orderdate )时的结果如下
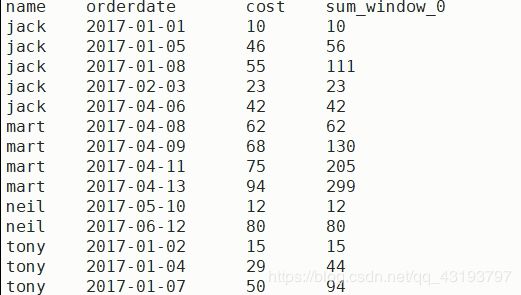
需要指定边界 rows between UNBOUNDED PRECEDING and UNBOUNDED FOLLOWING
(3)查询顾客的购买明细,将cost按照日期进行累加
select name,orderdate,cost,sum(cost) over(partition by name,month(orderdate) order by orderdate )
from business
(4)查询顾客上次的购买时间
要求结果如下:
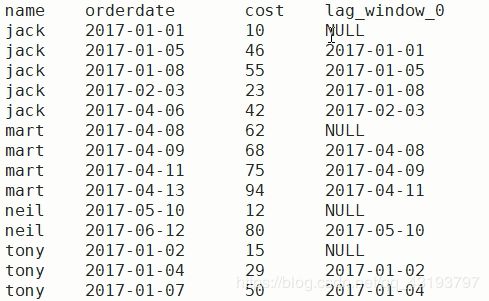
函数介绍:
LAG(col,n):往前第n行数据
LEAD(col,n):往后第n行数据
思路:先按照用户和购买时间排序,接着求拼接上次购买日期
select name,orderdate,cost, lag(orderdate,1,'无上条订单') over(partition by name order by orderdate) prevdate,
lead(orderdate,1,'无下条订单') over(partition by name order by orderdate) behinddate
from business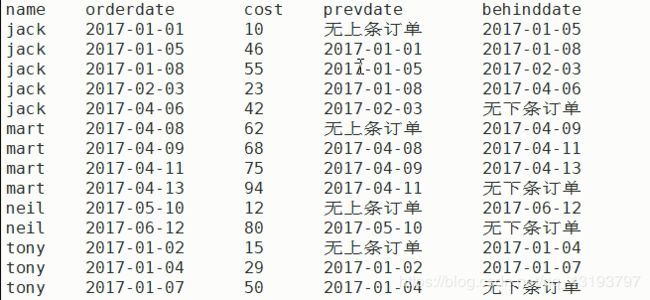
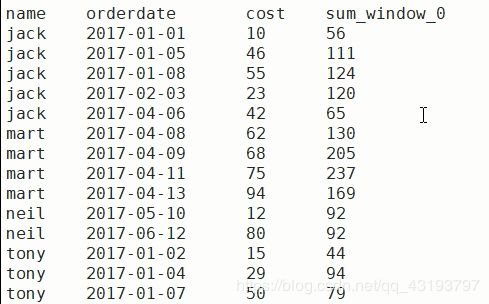
(5) 查询顾客的购买明细,计算顾客当前次和上一次和下一次的消费总和
select name,orderdate,cost,sum(cost) over(partition by name order by orderdate rows between 1 PRECEDING and 1 FOLLOWING)
from business
使用lag实现:
select name,orderdate,cost,lag(cost,1,0) over(partition by name order by orderdate) +
lead(cost,1,0) over(partition by name order by orderdate)+sum(cost) over(partition by name order by orderdate rows between CURRENT ROW and CURRENT ROW)
from business;
结果如下:
(5)查询前20%时间的订单信息
相关函数介绍:
NTILE(n):把有序分区中的行分发到指定数据的组中,各个组有编号,编号从1开始,对于每一行,NTILE返回此行所属的组的编号。注意:n必须为int类型。
执行 select name,orderdate,cost, ntile(5) over(order by orderdate) sorted from business 的结果
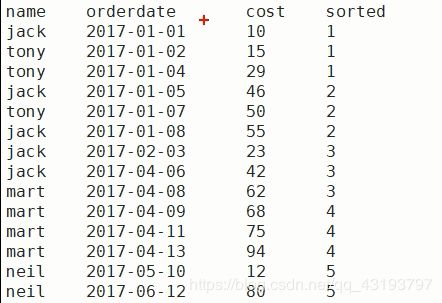
sorted字段说明:首先计算 总行数, 再计算 总行数/需要分组的个数 得到每条记录的分组号
最终答案如下:
查询语句
select * from (
select name,orderdate,cost, ntile(5) over(order by orderdate) sorted
from business
) t
where sorted = 1;

窗口函数的说明:
https://cwiki.apache.org/confluence/display/Hive/LanguageManual+WindowingAndAnalytics#LanguageManualWindowingAndAnalytics-PARTITIONBYwithonepartitioningcolumn,noORDERBYorwindowspecification
总结:
解决普通的函数无法针对某一区域的数据做统计分析。
普通的函数统计数据的区域,要么是全表。要么就是整个组,组内分析。
引入窗口函数。 窗口,为了指定当前函数统计的数据的范围! 不是单独使用,需要结合聚集函数或分析函数一起使用。
声明: over()
窗口的大小: over(使使用窗口子句进行指定)
rows|range between xx and xx
xx: unbounded|num preceeding
xx: unbounded|num following
current row
支持分区和排序: over(partition by 字段,字段 order by 字段 desc)
窗口函数两种特殊情况: ①没有order by 也没有rows ,窗口的大小就是整个数据集。
②有order by 也没有rows,窗口的大小,从窗口的第一行到当前行。
窗口的大小不能超过要分析的数据集的范围。
如果没有group by,过滤后的整个数据。
如果有group by ,窗口最大不超过分组后数据集的大小。
函数: lag(字段,n,默认值): 向上n行,取指定的字段值,如果是null,就使用默认值。
lead(字段,n,默认值): 向下n行,取指定的字段值,如果是null,就使用默认值。
ntile(n): 作用是将数据集,平均分到n个组中。对每个记录指定ntile()函数时,返回当前记录所在的组号。