Mybatis源码详解系列(四)--你不知道的Mybatis用法和细节
简介
这是 Mybatis 系列博客的第四篇,我本来打算详细讲解 mybatis 的配置、映射器、动态 sql 等,但Mybatis官方中文文档对这部分内容的介绍已经足够详细了,有需要的可以直接参考。所以,我将扩展一些其他特性或使用细节,掌握它们可以更优雅、高效地使用 mybatis。
这里补充一点,本文的所有测试例子都是基于本系列 Mybatis 第一篇文章的项目,其他相关博客如下:
Mybatis源码详解系列(一)–持久层框架解决了什么及如何使用Mybatis
Mybatis源码详解系列(二)–Mybatis如何加载配置及初始化
Mybatis源码详解系列(三)–从Mapper接口开始看Mybatis的执行逻辑
强大的结果处理器–ResultHandler
DO转VO–常用方式
通常情况下,我们的持久层的对象不会(不应该)直接响应给调用者,需要转换为 VO 对象再响应出去。基于本系列博客的使用例子,这里假设我需要在 web 层返回下面的 VO 对象,如下。在这个类中,除了员工表的字段外,还包括了部门表的字段。
public class EmployeeVO implements Converter<Employee, EmployeeVO>, Serializable {
private static final long serialVersionUID = 1L;
private String id;
private String name;
private String genderStr;
private String no;
private String password;
private String phone;
private String address;
private Byte status;
private String departmentId;
private String departmentName;
private String departmentNo;
@Override
public EmployeeVO convert(Employee value) {
EmployeeVO employeeVO = new EmployeeVO();
BeanUtils.copyProperties(employeeVO, value);
employeeVO.setGenderStr(value.getGender()?"男":"女");
Department department = value.getDepartment();
if(department != null) {
employeeVO.setDepartmentName(department.getName());
employeeVO.setDepartmentNo(department.getNo());
}
return employeeVO;
}
// 省略其他方法
}
web 层的操作大致是这样的,我先查询出Employee的集合,然后再进行对象转换。
@RequestMapping("/getList")
public ResponseData testResultHandler(@RequestBody EmployeeCondition con) {
List<Employee> list = employeeService.list(con);
return ResultDataUtil.getResultSucess(ConvertUtil.convertList(list, new EmployeeVO()));
}
DO转VO–ResultHandler方式
使用 Mybatis 的话,其实还有另外一种方案来处理 DO 转 VO 的问题,就是采用结果处理器–ResultHandler,如下。
public interface ResultHandler<T> {
void handleResult(ResultContext<? extends T> resultContext);
}
这是一个接口,实现类需要我们自己定义。作为测试例子,这里我简单定义了一个。
public class MyResultHandler<T, R> implements ResultHandler<T> {
private List<R> list = new ArrayList<R>();
private Converter<T, R> converter;
public MyResultHandler(Converter<T, R> converter) {
this.converter = converter;
}
@Override
public void handleResult(ResultContext<? extends T> resultContext) {
list.add(ConvertUtils.convertObject(resultContext.getResultObject(), converter));
}
public List<R> getList(){
return list;
}
}
使用ResultHandler时,Mapper 接口的方法定义需要调整,入参需传入ResultHandler,且返回值必须为 void。至于 xml 对应的方法内容,还是和常用方式一样,不需要更改。下面两个方法共用一个 xml 的 select 节点不会出问题的,这一点不用担心。
// 常用的方式
List<Employee> selectByCondition(@Param("con") EmployeeCondition con);
// ResultHandler的方式
void selectByCondition(@Param("con") EmployeeCondition con, ResultHandler<Employee> resultHandler);
最后回到我们的 web 层,至于 service 层的代码就忽略不看了。当调用 service 层时,我已经拿到了转换好的 VO 对象,我不需要再做处理。
@RequestMapping("/getList")
public ResponseData testResultHandler(@RequestBody EmployeeCondition con) {
MyResultHandler<Employee, EmployeeVO> resultHandler = new MyResultHandler<>(new EmployeeVO());
employeeService.list(con, resultHandler);
return ResultDataUtil.getResultSucess(resultHandler.getList());
}
上一篇博客在分析源码过程中有提到过这个接口,当 Mapper 接口的方法入参包含ResultHandler且返回类型为 void,Mybatis 会对这种情况特殊处理:当遍历结果集进行映射时,每映射完一个对象都会调用一次ResultHandler并将映射好的对象传入,这时,我们可以随意地对对象进行处理,包括我们常见的 DO 转 VO,当然,它的功能并不局限于此。
分页不需要插件–RowBounds
本系列使用篇中提到使用 pagehelper 来支持分页功能,本质上是使用了插件对 sql 植入分页参数。其实,Mybatis 已经提供了RowBounds这类来支持分页功能,这种方式不需要安装插件,MybatisPlus 本质上就是使用了这种方式。
和ResultHandler一样,我们只需要改造下 Mapper 接口的方法,如下。
List<Employee> selectByCondition(@Param("con") EmployeeCondition con, RowBounds rowBounds);
这里我简单编写个测试类,直接使用RowBounds对象,实际上最好对RowBounds进行更多的包装。
/**
* 测试RowBounds
*/
@Test
public void testRowBounds() {
EmployeeCondition con = new EmployeeCondition();
// 设置条件
con.setAddress("北京");
// 执行,获取员工对象
RowBounds rowBounds = new RowBounds(1, 4);
List<Employee> list = employeeRepository.list(con, rowBounds);
// 打印
list.forEach(System.out::println);
}
测试以上代码,可看到打出的语句植入了分页参数:
SELECT e.id, e.`name`, e.gender, e.no, e.password
, e.phone, e.address, e.status, e.deleted, e.department_id
, e.gmt_create, e.gmt_modified
FROM demo_employee e
WHERE 1 = 1
AND e.address = ?
LIMIT ?, ?
相比使用插件,这种方式是否更加简单呢?但是,上一篇博客的源码分析中,我们发现Mybatis 使用 RowBounds进行分页,发送 sql 时不会植入分页参数,而是将结果查出,然后在内存中进行分页,所以,这种方式不建议单独使用。MybatisPlus 使用RowBounds参数时,配合了插件来解决这个问题。后面将 MybatisPlus 时再做补充吧。
延迟加载
回顾使用篇的内容
我们知道,在 resultMap 中使用嵌套 select 查询,并且全局声明使用懒加载,可以实现按需加载嵌套属性。
<settings>
<setting name="lazyLoadingEnabled" value="true" />
settings>
还是回到使用篇中例子,mapper 的配置如下,员工对象关联了部门(一对一)、角色(一对多)、菜单(一对多):
<resultMap id="BaseResultMap" type="Employee">
<id column="id" property="id" javaType="string" jdbcType="VARCHAR" />
<result column="department_id" property="departmentId" javaType="string" jdbcType="VARCHAR" />
<result column="gmt_create" property="create" javaType="date" jdbcType="TIMESTAMP" />
<result column="gmt_modified" property="modified" javaType="date" jdbcType="TIMESTAMP" />
<association property="department"
column="department_id"
select="cn.zzs.mybatis.mapper.DepartmentMapper.selectByPrimaryKey" />
<collection property="roles"
column="id"
select="cn.zzs.mybatis.mapper.RoleMapper.selectByEmployeeId" />
<collection property="menus"
column="id"
select="cn.zzs.mybatis.mapper.MenuMapper.selectByEmployeeId" />
resultMap>
<select id="selectByPrimaryKey" parameterType="java.lang.String" resultMap="BaseResultMap">
select
<include refid="Base_Column_List">include>
from
demo_employee e
where
e.id = #{id,jdbcType=VARCHAR}
select>
测试代码中,我们注释掉第1、3 和 4 点的代码,即只调用getDepartment()方法。
/**
* 测试懒加载触发
*/
@Test
public void testGetLazy() {
// 设置输出代理类到指定路径
// -Dcglib.debugLocation=D:/growUp/test
String id = "cc6b08506cdb11ea802000fffc35d9fe";
// 执行,获取员工对象
Employee employee = employeeRepository.get(id);
// 1.打印员工
// System.out.println(employee);
// 2.打印部门
System.out.println(employee.getDepartment());
// 3.打印角色
// employee.getRoles().forEach(System.out::println);
// 4.打印菜单
// employee.getMenus().forEach(System.out::println);
}
测试以上代码,可以看到,只有部门被加载出来,而角色和菜单没有,很好地实现了按需加载。
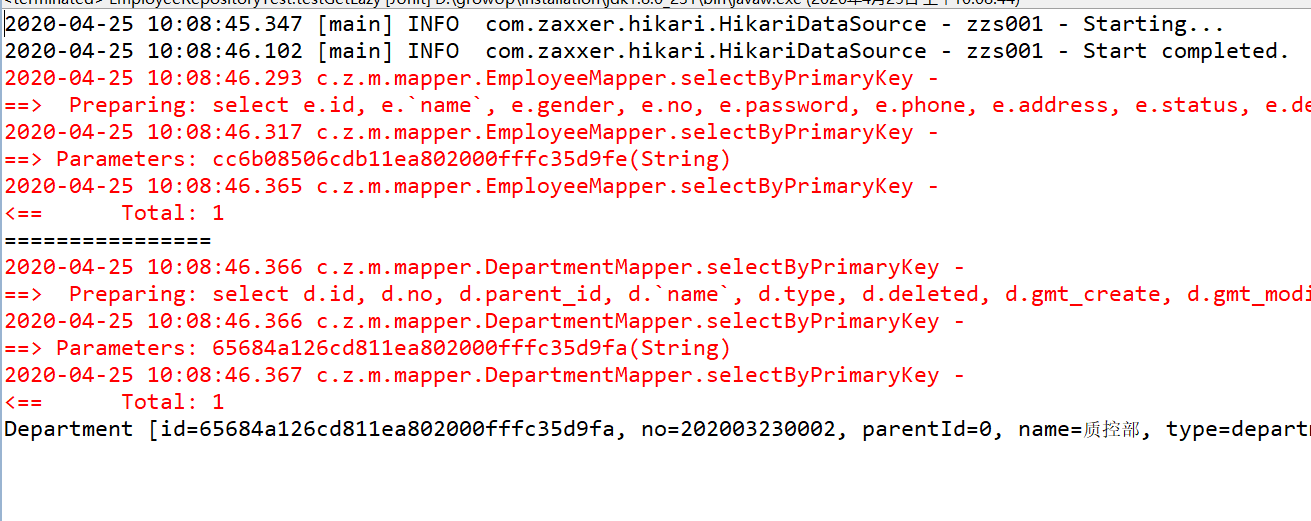
接着我们放开第 1 点,即增加打印员工,注意,使用例子中我并没有重写toString()方法,所以方法中也不会用到关联对象。
@Test
public void testGetLazy() {
// 设置输出代理类到指定路径
// -Dcglib.debugLocation=D:/growUp/test
String id = "cc6b08506cdb11ea802000fffc35d9fe";
// 执行,获取员工对象
Employee employee = employeeRepository.get(id);
System.out.println("================");
// 1.打印员工
System.out.println(employee);
// 2.打印部门
// System.out.println(employee.getDepartment());
// 3.打印角色
// employee.getRoles().forEach(System.out::println);
// 4.打印菜单
// employee.getMenus().forEach(System.out::println);
}
测试以上代码,我们惊讶地发现,这时部门、角色和菜单都被打印出来了,说好的按需加载呢?
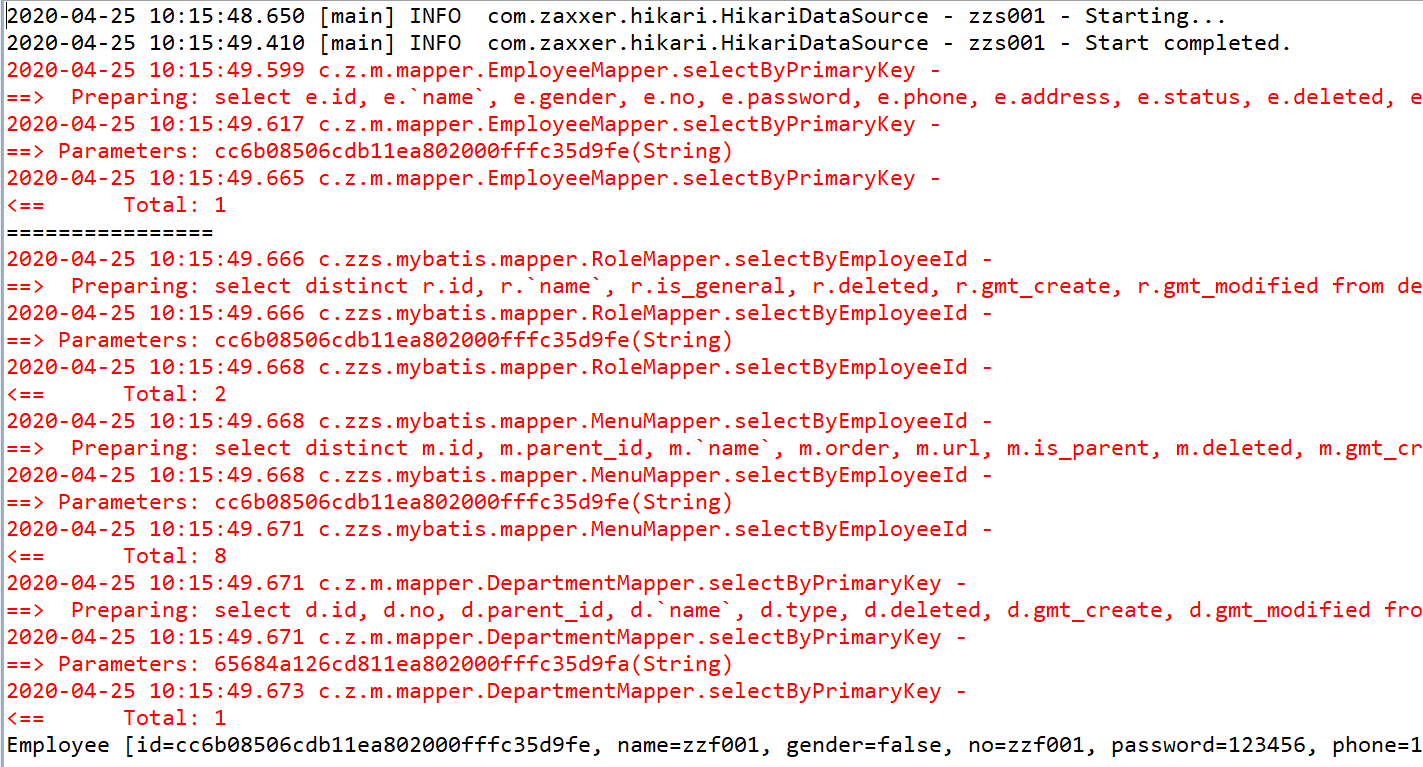
这就很奇怪了,我调用的方法并没用到关联对象啊,为什么它们会被加载出来?
什么时候触发延迟加载
在上面的例子中,我们的按需加载失效了吗?
其实并没有,对于 Mybatis 而言,它可以知道getDepartment()这样的方法会使用到关联对象,但是toString()这样的方法,它就没办法知道了。考虑我们会在重写toString方法时使用到嵌套对象,所以,Mybatis 默认这个方法会触发延迟加载。同样道理,equals(),clone(),hashCode()等方法也是一样的,项目中要重点关注equals()和hashCode()。
那么,我们如何控制这种行为呢?Mybatis 提供了 lazyLoadTriggerMethods 配置项指定对象的哪些方法触发延迟加载:
| 设置名 | 描述 | 有效值 | 默认值 |
|---|---|---|---|
| lazyLoadTriggerMethods | 指定哪些方法触发加载该对象的所有延迟加载属性。 | 用逗号分隔的方法列表。 | equals,clone,hashCode,toString |
我们将配置修改如下:
<setting name="lazyLoadingEnabled" value="true" />
<setting name="lazyLoadTriggerMethods" value="equals,clone,hashCode" />
再次测试上面的例子。这时,嵌套对象都没有被加载出来。
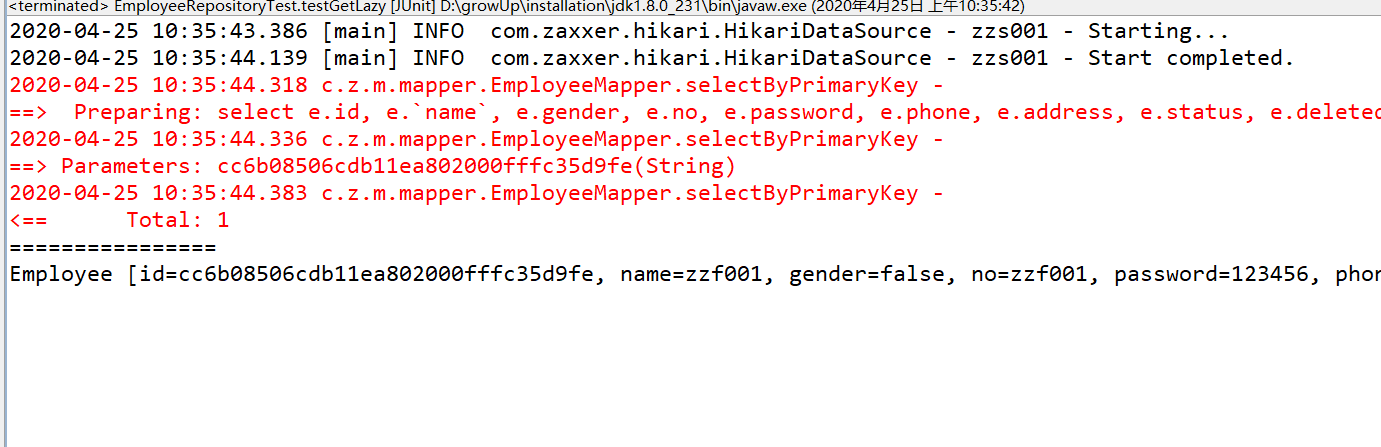
这里再补充下,还有另一个配置项 aggressiveLazyLoading 也会影响延迟加载的触发,这个配置项在 3.4.1 之后我们保持默认就行,如果不是必须,强烈建议不要配置成 true。如果你将 aggressiveLazyLoading 配置为 true,即使你只是 getId() 也会将所有嵌套对象加载出来。
| 设置名 | 描述 | 有效值 | 默认值 |
|---|---|---|---|
| aggressiveLazyLoading | 开启时,几乎任一方法的调用都会加载该对象的所有延迟加载属性。 否则,每个延迟加载属性会按需加载。 |
true | false | false (在 3.4.1 及之前的版本中默认为 true) |
作为延迟加载部分的总结,这里对比下不同配置项组合的效果:
| aggressiveLazyLoading | lazyLoadTriggerMethods | 效果 |
|---|---|---|
| true | / | 员工类中任一方法、equals、clone、hashCode、toString被调用,会触发延迟加 |
| false | equals,clone,hashCode,toString | 员工类中关联对象的getter方法、equals、clone、hashCode、toString被调用,会触发延迟加载 |
| false | equals | 员工类中关联对象的getter方法、equals被调用,会触发延迟加载 |
有的延迟?有的不延迟
如果我希望部分关联对象不用延迟加载,部分关联对象又需要,例如,查询员工对象时,部门跟着查出来,而角色等到需要用的时候再加载。针对这种情况,可以在映射关系中使用 fetchType来覆盖延迟加载的开关状态:
<association property="department"
column="department_id"
fetchType="eager"
select="cn.zzs.mybatis.mapper.DepartmentMapper.selectByPrimaryKey" />
<collection property="roles"
column="id"
select="cn.zzs.mybatis.mapper.RoleMapper.selectByEmployeeId" />
<collection property="menus"
column="id"
select="cn.zzs.mybatis.mapper.MenuMapper.selectByEmployeeId" />
嵌套结果映射的一个大坑
在使用篇里我说过这么一句话:嵌套结果里如果是collection的话,分页总数会存在问题,所以,嵌套结果映射的方式最好仅针对 association 使用。
当时我没有解释具体原因,这里我补充下吧。
错误的总数
还是回到使用篇的例子,mapper 的 resultMap 是这样配置的:
<resultMap id="BaseResultMap2" type="Employee" autoMapping="true">
<id column="id" property="id" javaType="string" jdbcType="VARCHAR" />
<result column="department_id" property="departmentId" javaType="string" jdbcType="VARCHAR" />
<result column="gmt_create" property="create" javaType="date" jdbcType="TIMESTAMP" />
<result column="gmt_modified" property="modified" javaType="date" jdbcType="TIMESTAMP" />
<association property="department"
columnPrefix="d_"
resultMap="cn.zzs.mybatis.mapper.DepartmentMapper.BaseResultMap" />
resultMap>
编写测试方法如下。这里会采用分页插件 pagehelper 来统计查询总数,及进行分页。如果使用RowBounds,也不影响测试结果。注意,数据库中的“zzs001”只有一条记录,所查询到的总数和映射对象都会是一条。
@Test
public void testlistPage() {
EmployeeCondition con = new EmployeeCondition();
// 设置条件
con.setName("zzs001");
con.setJoinDepartment(true);
// con.setJoinRole(true);// 这个注释待会放开
// 设置分页信息
PageHelper.startPage(0, 3);
// 执行查询
List<Employee> list = employeeRepository.list2(con);
// 遍历结果
list.forEach(System.out::println);
// 封装分页模型
PageInfo<Employee> pageInfo = new PageInfo<>(list);
// 取分页模型的数据
System.out.println(Long.valueOf(pageInfo.getTotal()).intValue() == list.size());
}
测试代码,可以看到分页统计的总数和实际数量都会是一条,完全没问题。
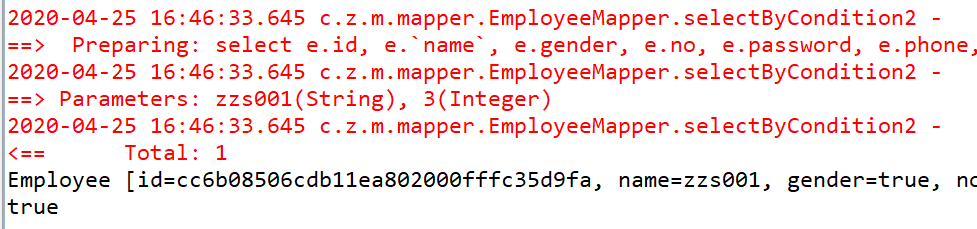
接下来我再 resultMap 中增加一个 collection 类型的嵌套对象。
<resultMap id="BaseResultMap2" type="Employee" autoMapping="true">
<id column="id" property="id" javaType="string" jdbcType="VARCHAR" />
<result column="department_id" property="departmentId" javaType="string" jdbcType="VARCHAR" />
<result column="gmt_create" property="create" javaType="date" jdbcType="TIMESTAMP" />
<result column="gmt_modified" property="modified" javaType="date" jdbcType="TIMESTAMP" />
<association property="department"
columnPrefix="d_"
resultMap="cn.zzs.mybatis.mapper.DepartmentMapper.BaseResultMap" />
<collection property="roles"
columnPrefix="r_"
resultMap="cn.zzs.mybatis.mapper.RoleMapper.BaseResultMap" />
resultMap>
放开测试代码中的注释,测试如下。映射对象一条,没错,但是查询总数,竟然是 2 条???
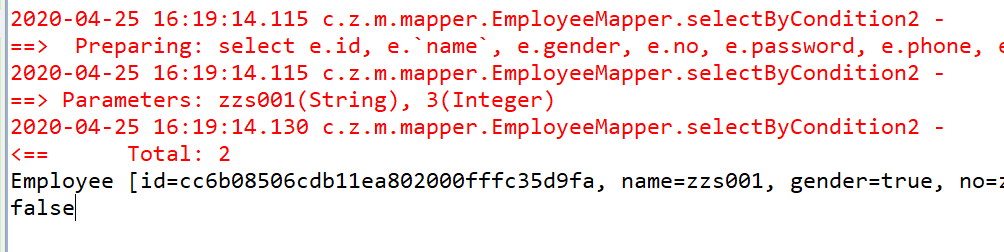
这就是我提到的嵌套结果映射的一个大坑。
原因分析
难道是统计错了?让我们执行下控制台的 sql,记录竟然也是 2 条,哪里冒出来的???
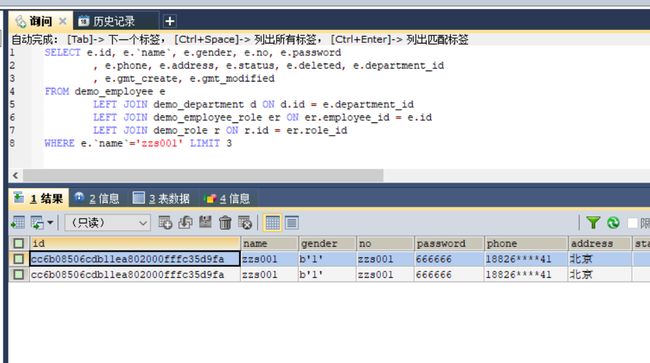
其实,根本原因确实出在我们的使用方法上,collection 的嵌套结果映射就不应该被用在涉及到统计的场景。我们的 sql 查出来有两条,仔细观察就会发现,这两条记录的 id 是一模一样的,我们再查询出 1 个字段:
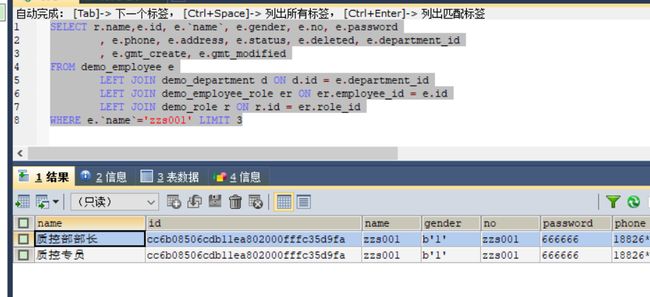
看到这里应该就明白了吧,统计出错主要是联表造成的。员工和角色是一对多的关系,当员工拥有多个角色时联表查询将出现比员工数量更多的记录,而这些记录,在 Mybatis 映射对象时会将其合并起来。
这就造成了所谓的错误总数问题。所以,collection 的嵌套结果映射并不适合统计场景。
自动映射
开启自动映射
mybatis 的结果自动映射默认是开启的,可以在使用 setting 配置项进行修改,它有三种自动映射等级:
NONE- 禁用自动映射。仅对手动映射的属性进行映射。PARTIAL- 对除在内部定义了嵌套结果映射(也就是连接的属性)以外的属性进行映射。默认配置。FULL- 自动映射所有属性。
默认使用 PARTIAL,另外, 无论设置的自动映射等级是哪种,你都可以通过在映射文件中设置 resultMap 的 autoMapping 属性来为指定的结果映射设置启用/禁用自动映射。
<resultMap id="BaseResultMap2" type="Employee" autoMapping="true">
<id column="id" property="id" javaType="string" jdbcType="VARCHAR" />
resultMap>
自动映射驼峰命名的属性
当自动映射查询结果时,MyBatis 会获取结果中返回的列名并在 Java 类中查找相同名字的属性(忽略大小写)。如果列名和实体中的属性名对不上,则需要显式地配置。在使用例子中,我们使用resultMap来映射表和对象,如下:
<resultMap id="BaseResultMap" type="cn.zzs.mybatis.entity.Employee">
<id column="id" property="id" javaType="string" jdbcType="VARCHAR" />
<result column="department_id" property="departmentId" javaType="string" jdbcType="VARCHAR" />
<result column="gmt_create" property="create" javaType="date" jdbcType="TIMESTAMP" />
<result column="gmt_modified" property="modified" javaType="date" jdbcType="TIMESTAMP" />
resultMap>
<sql id="Base_Column_List">
e.id,
e.`name`,
e.gender,
e.no,
e.password,
e.phone,
e.address,
e.status,
e.deleted,
e.department_id,
e.gmt_create,
e.gmt_modified
sql>
<select id="selectByPrimaryKey" parameterType="java.lang.String" resultMap="BaseResultMap">
select
<include refid="Base_Column_List" />
from
demo_employee e
where
e.id = #{id}
select>
除了表列名和实体的属性名一致的情况,其他的字段都需要我们手动配置映射,这样做比较麻烦。但是,大部分情况下,我们都会遵循驼峰命名的规则来定义实体的属性名,是否可以直接通过这种规则来自动映射呢?
mybatis 提供了mapUnderscoreToCamelCase配置项来处理这种情况。
<settings>
<setting name="mapUnderscoreToCamelCase" value="true" />
settings>
参考资料
Mybatis官方中文文档
相关源码请移步:mybatis-demo
本文为原创文章,转载请附上原文出处链接:https://www.cnblogs.com/ZhangZiSheng001/p/12773971.html