《数学之美》与算法
原文链接:https://www.taohui.pub/2019/02/23/%e3%80%8a%e6%95%b0%e5%ad%a6%e4%b9%8b%e7%be%8e%e3%80%8b%e4%b8%8e%e7%ae%97%e6%b3%95/
《数学之美》是一本非常好的算法进阶书,它与吴军老师从事的工作领域密切相关,所以工程性很强。半年时间断断续续读完此书,这里做个笔记,也希望能帮助还未读过本书的同学快速了解主要内容。这本书里主要讲述了两个应用场景:
- 搜索引擎;
- 机器翻译及输入法;
这两个场景都与信息论紧密相关,我们便从信息熵谈起。
1、计算出一段信息的价值
信息熵便是一段信息的价值,计算出它有许多用处。例如:
- 为什么HTTP响应中,对json或者html格式要做压缩,而jpg、gif不做压缩?gzip压缩算法再改进还有多少余地吗?
- 为什么五笔字形早些年很多人在学,现在基本被拼音输入法取代?拼音输入法输入速度越来越快,最快能几个键录入一个汉字?
- 用户搜索“原子能的应用”时,“原子能”、“的”、“应用”这三个词谁的信息价值更大?大多少?
信息的价值就是这段信息的信息量,如何计算出信息量呢?假如我从未来穿越回来,有人问我世界杯32支球队哪支是冠军,如果他很聪明的话,最多问5次就可以获得答案。他可以把32支球队编号,以二分法来问我:1-16号队中有冠军吗?根据我的回答,再问:1-8或者17-24队中有冠军吗?这样,最多log232次即5次即可获得结果,那么32支球队中冠军是哪支队伍的信息量就是5。
如果这个人是一个球迷,他知道巴西队夺冠的概率高,中国队夺冠的概率低,根据他历年的观察经验算出了这32支球队的夺冠概率,那么这条信息的信息量对他来说便小于5。因为他可以这么问:是某8个热门球队夺冠还是其他24支比较弱的队伍夺冠?这样便可以通过更少的次数从我这拿到结果。
所以,设信息量为H,每支球队的夺冠概率是P(n),那么信息量H=−(P1∗logP1+P2∗logP2+…+P32xlogP32)。根据香农的定义,信息量H(x)=−∑nx=1P(x)∗log2P(x)。
因此,“太阳每过24小时都会从东边升起”,这条信息对成人来说信息量很小,而对4岁的儿童信息量就很大,这是因为他们的已知信息不同,这也是为什么百度搜索信息总是没有谷歌准确的原因,即使他们使用了同样的PageRank算法,但当谷歌从搜索关键字里拿到更多信息量时(例如历史用户点击率、用户搜索的准确领域等),就能提供更准确的结果。
现在我们来回答第1个问题(第2、3问题留待搜索引擎与输入法章节再回答)。根据信息熵的定义,HTTP响应中每个字符的概率P(n)是不同的,怎么得到概率呢?首先我们要拿到统计样本,或者叫语料库,若该语料库足够大且覆盖所有场景,那么根据大数定理,只要统计量足够大那么相对频率便等于概率。设语料库共有字符N个,而待统计的字符x共出现了M次,那么x的概率P(x)便等于M/N。
例如对汉字而言,常用汉字大约7000个(参见GB2312,共收录6763个汉字),若所有字等概率出现,那么每个字的概率是log27000=12.8比特,而实际上前10%的汉字占到95%以上的出现概率,所以若不考虑上下文相关性那么每个汉字的独立概率大约是8-9比特,考虑上下文相关性后,每个汉字大约5比特。所以,一本50万字的图书信息量大约是5∗500000=2500000比特,若采用GBK编码(2字节1汉字)时需要500000×2=1MB空间,而好的压缩算法仅需要2500000÷8=320KB空间。
所以,对于一段HTML或者JSON文本,它的信息熵远小于UTF-8直接按字符编码后的空间大小,而gzip压缩后的空间大小与信息熵的差值,就是压缩算法的改进余地。而JPG或者GIF图片事实上已经做过压缩,其信息熵与文件大小相差不大,所以没必要再做gzip压缩。
2、拼音输入法与维特比算法
笔者从94年开始学习五笔字形输入法(那个时代的小霸王学习机大家还有印象吗?),照着稿子打(拆字)可以达到每分钟500个字,由此极度鄙视拼音输入法。那时候的拼音输入法还分为全拼和双拼,全拼就是我们熟知的拼音,双拼又是什么鬼?由于觉得敲N个键出M个字,每个键的贡献度M/N太小了,于是把含多个键的声母或者韵母重新编码,以减少输入键数创造出来的编码方式。早期的拼音输入法也没有模糊音的概念,于是全中国非北京的同学都苦逼了,要么分不清平舌音和翘舌音,要么分不清前鼻音和后鼻音,要么分不清nlt。就像五笔输入法一样,双拼是需要额外学习成本的。
输入一个汉字究竟最少需要敲几个键呢?
若常用汉字7000个,而我们只用26个字母(不考虑数字键和方向键)输入,那么2个键262=676是不够的,至少需要3个键263=17576才能完成。
再细化点,根据香农的信息熵公式,不考虑相关性每个汉字的熵是10比特,只用26个字母输入的话每个键的熵是log226=4.7次,所以每个汉字至少需要10/4.7=2.1次击键。
如果引入词组,汉字的平均熵下降到8比特,则每个汉字需要8/4.7=1.7次击键,再引入上下文把平均熵降到6比特,则平均每个汉字需要6/4.7=1.3次击键。当然,这是理论上的极限值,目前的全拼使用了常用词组、上下文后,每汉字击键次数约3次,这已经小于五笔字形等靠拆字为生的字形输入法了。
当然,五笔字形等输入法最大的缺点是需要很高的学习成本(记忆成本,还记得“王旁青头兼五一”吗?),而且拆字会中断思维,一心二用的效率是低下的。拼音输入法能直线进步的一个重要原因是靠上下文猜出我们想输入的词组(包括模糊音、容错、只输入部分就猜出全部),这依赖马上要介绍的维特比算法。
由于我们输入的拼音没有声调,平均一个无声调拼音对应约13个汉字,如果我们要输入10个拼音,对应汉字的组合有多少呢?1310约等于1016!我们现在的CPU每秒钟不过3GHz,如果用穷举法,一天都猜不出这10个字的组合里,哪个是用户最想输入的汉字组合。
当然,所谓用户最想输入的汉字组合,就是概率最大的汉字组合,设10个汉字为w1到w10,则该组合的概率为P(w1,w2,w3,…,w10)。怎么算这个联合概率呢?需要用到条件概率公式P(A,B)=P(A|B)*P(B),其中P(A|B)表示B已经发生时再发生A的概率,对应已经输入w1汉字后w2的概率。
所以,P(w1,w2,w3,…,w10)=P(w1)*P(w2|w1)*P(w3|w1,w2)*…*P(w10|w1,w2,…,w9)。怎样计算出这些概率呢?根据上一节我们介绍过的大数定理,只要语料库足够大,根据w1出现的次数就可以计算出P(w1),也可以按词组计算出P(w2|w1),以此类推。但后面的计算量实在太大了,于是我们用到了马尔可夫模型。一元马尔可夫模型假定,P(w4|w1,w2,w3)约等于P(w4|w3),即仅与前一个字相关,而二元模型下P(w4|w1,w2,w3)约等于P(w4|w2,w3),当然计算量也更大。
当得到任10个汉字组合短语概率后,我们现在希望找出最大概率作为第1选择给到用户,此时,维特比算法登场了。
每个拼音若对应13个汉字,那么求10个汉字组合,相当于从13*10的有向图中找出10个汉字相连后的最短路径(概率最大)。简化为下图中,共有4*4*4=64种路径,要找出最短的红色路径,便可以使用维特比算法:

维特比算法其实就是一种动态规划算法(动态规划算法是地图导航、3/4/5G通讯、基于有限状态机的通讯地址分析等场景下的基础算法,不了解的同学建议先读下《算法导论》第15章),它也用到了计算机编程中常用的递归思想。打个比方,如果你是马云,你怎么管理好数万人的阿里巴巴公司呢?你只需要找到最合适的几个高管,如果他们能把阿里云、大文娱、支付宝、天猫等公司管理到最好,则阿里巴巴集团自然也就是最好的了。动态规划便基于这个思想,当然,它的前提是:1、这是个求最优解的问题;2、每个问题的最优解可以分解为子问题的最优解。
维特比算法下,求B层到C层的最短路径时,并不用重新计算S到A或者A到B的路径,而只需要从B层所有节点到C层所有节点的路径上找出最短路径即可:
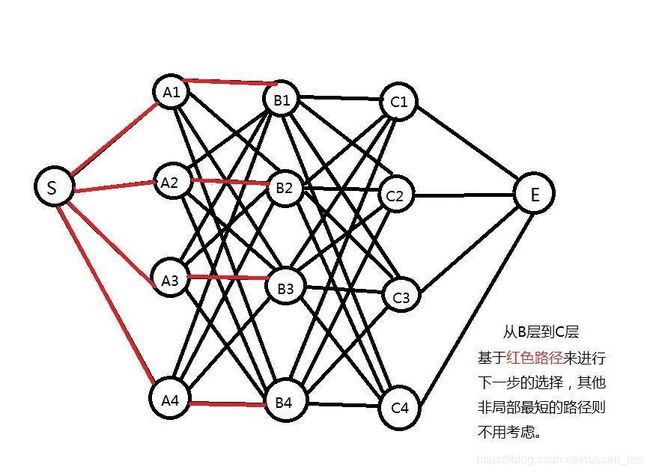
所以,10个汉字中找出最短路径的计算量是13*13*10,这远远小于穷举法中的1310!
3、维特比与频分多址
维特比算法是高通公司创始人维特比发明的算法,该算法对无线通讯中的3G4G5G网络有很大贡献。
上世纪九十年代的“大哥大”无线电话用的是1G网络,类似对讲机、卫星电话他们用的都是频分多址FDMA技术,该技术按波长把固定频率分给一组通话。它最大的问题是很难容纳大量的并发通话数。
到2G时代,欧洲主导的GSM技术使用的是TDMA时分多址,就像我们的操作系统,虽然所有进程共享同一个CPU,但把CPU的时间分成多片,进程们轮流占用时间片,进而产生多进程同时运行的效果。TDMA也是一样,在同一段频率下,许多通话同时分时共享频段。相比FDMA,它能容纳更多的并发通话,但问题是,时分多址会有一些频率浪费在分隔点左右,效率不高。
到3G时代的CDMA使用码分多址技术,每对通话使用不同的译码,虽然接收到完整的频率,但靠着不同的code译出想要的数据,如下图所示:

什么叫译码呢?就像吉普赛纸牌,若我们接收到以下数据:

第1组通话的CODE是在卡片上方挖出6个孔,第2组通话的CODE是在卡片上挖出另外14个孔,把卡片分别盖在上面的接收数据上,便分别得到了2组通话待接收的数据,如下图所示:

基于FDMA频分多址后,我们的通话便可以尽情的使用尽可能多的频段。4G LTE、5G网速越来越快的原因,便在于基于FDMA后,加入更多的超高频扩展我们的频段后便通过更宽的通道带来更大的速率。
4、网络爬虫与布隆过滤器
搜索引擎主要由三个组成部分:
- 由爬虫将网络中的网页爬下并建立倒排索引;
- 类似SQL查询,把用户查询关键字解析为布尔代数,按规则从索引中取出数据(所谓的“搜商”便体现在这里);
- 根据PageRank算法、站点权威性、点击率等信息将网页结果排序。
由于全网的页面之间互相引用,形成了一张图。网络爬虫希望在有效的时间段内快速下载页面,便面临2个问题:
- 问题1:应该以深度优先(先把一个网站的页面全部下载完)还是广度优先(先下载各大站点的首页,再依次下载它们的二级页面,等等)算法下载页面呢?
网页有生命周期,重要程度也不相同,往往首页最重要,二级页面次之。采用广度优先去下载全网页面,能照顾到页面的权重。
然而,纯按广度优先会使得TCP连接的效率很差,对同一个站点反复握手建立连接、拥塞窗口缓慢增加等,都降低了网络效率,使用深度优先可以基于长连接提升爬虫效率。所以,爬虫需要兼顾深度优先和广度优先算法。
- 问题2:页面之间互相引用,所以发现一个URL后,怎么判定该URL曾经下载过,页面已经存在了呢?
对非网络爬虫场景,使用哈希表都是没问题的,通过长度有限的信息指纹基于O(1)时间复杂度快速判定字符串URL是否被下载过。
但网络爬虫面对的URL集合太大,这表现在:1、URL数量太大;2、URL字符串长度达几十、几百字节。这造成需要几十几百台服务器才能以哈希表放下全量URL。而布隆过滤器可以使用更少的服务器解决这一场景。
布隆过滤器将一个元素通过多个哈希函数映射出多个值,按位保存在数组中。例如下图中,有h1、h2、h3三个哈希函数,对元素a而言h1(a)=3,h2(a)=9,h3(a)=14,于是将数组B中第3、9、14位置1。集合S里有a、b、c三个元素,分别在B中9个位置设为1,其余位置为0。

判定新元素d和e是否在S中很简单,若h1、h2、h3计算出的值对应在B数组中的位有任何一个不为1,那么一定不在集合S中,例如元素e,虽然h2(e)h3(e)都是1,但h1(e)是0,那么e一定不在S中。
但布隆过滤器就像任何哈希表一样,存在碰撞可能,也就是误算率。例如对元素d而言,三个哈希函数的值对应的位都为1,但d并不在S中。它的误算率到底是多少呢?设n是集合S中元素的个数,而m是B数组中位的个数,而k是哈希函数的个数,那么其误算率如下表所示:
| m/n | k | k=1 | k=2 | k=3 | k=4 | k=5 | k=6 | k=7 | k=8 |
| 2 | 1.39 | 0.393 | 0.400 | ||||||
| 3 | 2.08 | 0.283 | 0.237 | 0.253 | |||||
| 4 | 2.77 | 0.221 | 0.155 | 0.147 | 0.160 | ||||
| 5 | 3.46 | 0.181 | 0.109 | 0.092 | 0.092 | 0.101 | |||
| 6 | 4.16 | 0.154 | 0.0804 | 0.0609 | 0.0561 | 0.0578 | 0.0638 | ||
| 7 | 4.85 | 0.133 | 0.0618 | 0.0423 | 0.0359 | 0.0347 | 0.0364 | ||
| 8 | 5.55 | 0.118 | 0.0489 | 0.0306 | 0.024 | 0.0217 | 0.0216 | 0.0229 | |
| 9 | 6.24 | 0.105 | 0.0397 | 0.0228 | 0.0166 | 0.0141 | 0.0133 | 0.0135 | 0.0145 |
| 10 | 6.93 | 0.0952 | 0.0329 | 0.0174 | 0.0118 | 0.00943 | 0.00844 | 0.00819 | 0.00846 |
| 11 | 7.62 | 0.0869 | 0.0276 | 0.0136 | 0.00864 | 0.0065 | 0.00552 | 0.00513 | 0.00509 |
| 12 | 8.32 | 0.08 | 0.0236 | 0.0108 | 0.00646 | 0.00459 | 0.00371 | 0.00329 | 0.00314 |
| 13 | 9.01 | 0.074 | 0.0203 | 0.00875 | 0.00492 | 0.00332 | 0.00255 | 0.00217 | 0.00199 |
| 14 | 9.7 | 0.0689 | 0.0177 | 0.00718 | 0.00381 | 0.00244 | 0.00179 | 0.00146 | 0.00129 |
| 15 | 10.4 | 0.0645 | 0.0156 | 0.00596 | 0.003 | 0.00183 | 0.00128 | 0.001 | 0.000852 |
| 16 | 11.1 | 0.0606 | 0.0138 | 0.005 | 0.00239 | 0.00139 | 0.000935 | 0.000702 | 0.000574 |
| 17 | 11.8 | 0.0571 | 0.0123 | 0.00423 | 0.00193 | 0.00107 | 0.000692 | 0.000499 | 0.000394 |
| 18 | 12.5 | 0.054 | 0.0111 | 0.00362 | 0.00158 | 0.000839 | 0.000519 | 0.00036 | 0.000275 |
| 19 | 13.2 | 0.0513 | 0.00998 | 0.00312 | 0.0013 | 0.000663 | 0.000394 | 0.000264 | 0.000194 |
| 20 | 13.9 | 0.0488 | 0.00906 | 0.0027 | 0.00108 | 0.00053 | 0.000303 | 0.000196 | 0.00014 |
| 21 | 14.6 | 0.0465 | 0.00825 | 0.00236 | 0.000905 | 0.000427 | 0.000236 | 0.000147 | 0.000101 |
| 22 | 15.2 | 0.0444 | 0.00755 | 0.00207 | 0.000764 | 0.000347 | 0.000185 | 0.000112 | 7.46e-05 |
| 23 | 15.9 | 0.0425 | 0.00694 | 0.00183 | 0.000649 | 0.000285 | 0.000147 | 8.56e-05 | 5.55e-05 |
| 24 | 16.6 | 0.0408 | 0.00639 | 0.00162 | 0.000555 | 0.000235 | 0.000117 | 6.63e-05 | 4.17e-05 |
| 25 | 17.3 | 0.0392 | 0.00591 | 0.00145 | 0.000478 | 0.000196 | 9.44e-05 | 5.18e-05 | 3.16e-05 |
| 26 | 18 | 0.0377 | 0.00548 | 0.00129 | 0.000413 | 0.000164 | 7.66e-05 | 4.08e-05 | 2.42e-05 |
| 27 | 18.7 | 0.0364 | 0.0051 | 0.00116 | 0.000359 | 0.000138 | 6.26e-05 | 3.24e-05 | 1.87e-05 |
| 28 | 19.4 | 0.0351 | 0.00475 | 0.00105 | 0.000314 | 0.000117 | 5.15e-05 | 2.59e-05 | 1.46e-05 |
| 29 | 20.1 | 0.0339 | 0.00444 | 0.000949 | 0.000276 | 9.96e-05 | 4.26e-05 | 2.09e-05 | 1.14e-05 |
| 30 | 20.8 | 0.0328 | 0.00416 | 0.000862 | 0.000243 | 8.53e-05 | 3.55e-05 | 1.69e-05 | 9.01e-06 |
| 31 | 21.5 | 0.0317 | 0.0039 | 0.000785 | 0.000215 | 7.33e-05 | 2.97e-05 | 1.38e-05 | 7.16e-06 |
| 32 | 22.2 | 0.0308 | 0.00367 | 0.000717 | 0.000191 | 6.33e-05 | 2.5e-05 | 1.13e-05 | 5.73e-06 |
| m/n | k | k=9 | k=10 | k=11 | k=12 | k=13 | k=14 | k=15 | k=16 |
| 11 | 7.62 | 0.00531 | |||||||
| 12 | 8.32 | 0.00317 | 0.00334 | ||||||
| 13 | 9.01 | 0.00194 | 0.00198 | 0.0021 | |||||
| 14 | 9.7 | 0.00121 | 0.0012 | 0.00124 | |||||
| 15 | 10.4 | 0.000775 | 0.000744 | 0.000747 | 0.000778 | ||||
| 16 | 11.1 | 0.000505 | 0.00047 | 0.000459 | 0.000466 | 0.000488 | |||
| 17 | 11.8 | 0.000335 | 0.000302 | 0.000287 | 0.000284 | 0.000291 | |||
| 18 | 12.5 | 0.000226 | 0.000198 | 0.000183 | 0.000176 | 0.000176 | 0.000182 | ||
| 19 | 13.2 | 0.000155 | 0.000132 | 0.000118 | 0.000111 | 0.000109 | 0.00011 | 0.000114 | |
| 20 | 13.9 | 0.000108 | 8.89e-05 | 7.77e-05 | 7.12e-05 | 6.79e-05 | 6.71e-05 | 6.84e-05 | |
| 21 | 14.6 | 7.59e-05 | 6.09e-05 | 5.18e-05 | 4.63e-05 | 4.31e-05 | 4.17e-05 | 4.16e-05 | 4.27e-05 |
| 22 | 15.2 | 5.42e-05 | 4.23e-05 | 3.5e-05 | 3.05e-05 | 2.78e-05 | 2.63e-05 | 2.57e-05 | 2.59e-05 |
| 23 | 15.9 | 3.92e-05 | 2.97e-05 | 2.4e-05 | 2.04e-05 | 1.81e-05 | 1.68e-05 | 1.61e-05 | 1.59e-05 |
| 24 | 16.6 | 2.86e-05 | 2.11e-05 | 1.66e-05 | 1.38e-05 | 1.2e-05 | 1.08e-05 | 1.02e-05 | 9.87e-06 |
| 25 | 17.3 | 2.11e-05 | 1.52e-05 | 1.16e-05 | 9.42e-06 | 8.01e-06 | 7.1e-06 | 6.54e-06 | 6.22e-06 |
| 26 | 18 | 1.57e-05 | 1.1e-05 | 8.23e-06 | 6.52e-06 | 5.42e-06 | 4.7e-06 | 4.24e-06 | 3.96e-06 |
| 27 | 18.7 | 1.18e-05 | 8.07e-06 | 5.89e-06 | 4.56e-06 | 3.7e-06 | 3.15e-06 | 2.79e-06 | 2.55e-06 |
| 28 | 19.4 | 8.96e-06 | 5.97e-06 | 4.25e-06 | 3.22e-06 | 2.56e-06 | 2.13e-06 | 1.85e-06 | 1.66e-06 |
| 29 | 20.1 | 6.85e-06 | 4.45e-06 | 3.1e-06 | 2.29e-06 | 1.79e-06 | 1.46e-06 | 1.24e-06 | 1.09e-06 |
| 30 | 20.8 | 5.28e-06 | 3.35e-06 | 2.28e-06 | 1.65e-06 | 1.26e-06 | 1.01e-06 | 8.39e-06 | 7.26e-06 |
| 31 | 21.5 | 4.1e-06 | 2.54e-06 | 1.69e-06 | 1.2e-06 | 8.93e-07 | 7e-07 | 5.73e-07 | 4.87e-07 |
| 32 | 22.2 | 3.2e-06 | 1.94e-06 | 1.26e-06 | 8.74e-07 | 6.4e-07 | 4.92e-07 | 3.95e-07 | 3.3e-07 |
| m/n | k | k=17 | k=18 | k=19 | k=20 | k=21 | k=22 | k=23 | k=24 |
| 22 | 15.2 | 2.67e-05 | |||||||
| 23 | 15.9 | 1.61e-05 | |||||||
| 24 | 16.6 | 9.84e-06 | 1e-05 | ||||||
| 25 | 17.3 | 6.08e-06 | 6.11e-06 | 6.27e-06 | |||||
| 26 | 18 | 3.81e-06 | 3.76e-06 | 3.8e-06 | 3.92e-06 | ||||
| 27 | 18.7 | 2.41e-06 | 2.34e-06 | 2.33e-06 | 2.37e-06 | ||||
| 28 | 19.4 | 1.54e-06 | 1.47e-06 | 1.44e-06 | 1.44e-06 | 1.48e-06 | |||
| 29 | 20.1 | 9.96e-07 | 9.35e-07 | 9.01e-07 | 8.89e-07 | 8.96e-07 | 9.21e-07 | ||
| 30 | 20.8 | 6.5e-07 | 6e-07 | 5.69e-07 | 5.54e-07 | 5.5e-07 | 5.58e-07 | ||
| 31 | 21.5 | 4.29e-07 | 3.89e-07 | 3.63e-07 | 3.48e-07 | 3.41e-07 | 3.41e-07 | 3.48e-07 | |
| 32 | 22.2 | 2.85e-07 | 2.55e-07 | 2.34e-07 | 2.21e-07 | 2.13e-07 | 2.1e-07 | 2.12e-07 | 2.17e-07 |
5、网页分类与TF-IDF算法
怎样判定两个网页的内容是否相似呢?我们可以先取出网页的特征。我们把网页的词汇取出,为了防止相同的词汇偏向长网页,我们使用TF算法(term frequency),设网页1由w1,w2,w3,…等词语(已经去重)组成,若一个词反复出现则表示与主题更相关,其中w1出现了tf1次,w2出现了tf2次,依此类推。这样,我们得到了初级版本的特征,例如[0,0,…,tf1,0,…,tf2,…tf3,…],其中词库是有序的,若某词未在网页中出现,则tf词频为0,相应位置也为0。
TF算法没有解决词本身的主题区分度问题。例如,原子能的应用里,这三个词“原子能”、“的”、“应用”里,显然“原子能”的区分度最高,而“的”这种区分度非常低。IDF(inverse document frequency)算法可以计算出词语的区分度,若语料库中“原子能”出现M次,而所有词语总数为N,那么其IDF值就是M/N。这样,引入IDF逆词频算法后,我们的特征向量变成了[0,0,…,tf1*idf1,0,…,tf2*idf2,…tf3*idf3,…],这便是TF-IDF算法。
网页根据TF-IDF算法得到向量后,我们可以利用余弦定理计算出向量的相似性。如果向量只有二维,那么在二维坐标系X,Y轴中我们可以根据[x1,y1]和[x2,y2]画出两个点,并从原点引出向量a和向量b。

向量a、b的夹角就是其余弦值,我们再回顾下初中时学过的余弦定理:
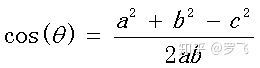
这样,扩展到高维后,向量间的余弦值越小,网页便越相似。
这里我们使用了余弦相似度,而人脸识别算法(可以参考我的另一篇文章《深入浅出人脸识别》)中每张人脸的特征向量是128维浮点型向量,使用的是欧氏距离也计算相似度。欧氏距离与余弦相似度是不同的,如下面的三维坐标图所示:
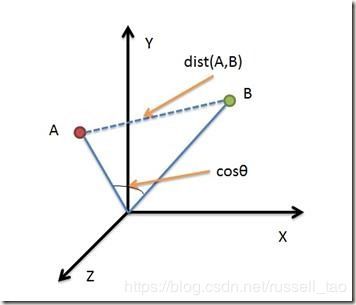
比如上面的欧氏距离dist(A,B)更强调距离,而下面的cos余弦更强调方向的相似。
当然,《数学之美》中还介绍了矩阵的奇异值分解、贝叶斯网络两种更快速的方法分类,这里不再介绍。
6、PageRank算法与网页权威度
当用户搜索关键字对应着成千上万个网页时,上个世纪的搜索引擎是没有办法把用户最需要的网页放在结果列表的最前面的,所以搜索引擎仅在学术领域小规模使用。当google的创始人拉里佩奇Larry Page发明了PageRank算法后,搜索引擎开始进入商用。
PageRank算法认为,应当由网页们自己投票计算出谁是最重要的网页,这样便可以按重要度排序将搜索结果呈现给用户。那怎样民主投票出重要度呢?PageRank算法认为,重要的页面会被更多的网页引用,如下图所示:

其中页面是图中的结点,URL超链接则构成了边。指向页面的边越多,这个页面就越重要。
这里也有一个问题,一些娱乐性质的站点PageRank排名更高,但它更八卦更强调运营效果,把这个结果放在更优先的搜索结果是不合适的,因为学术性站点虽然PageRank结果低但其实更权威,所以PageRank只是结果排名中的一个比较重要的因素,如领域权威性、用户点击率等维度也需要加入到网页排名算法中。
当然,《数学之美》书中远不止以上6点所介绍的算法,通过通俗易懂的方式点到为止的介绍诸多实用算法,这体现了吴军老师的深厚功力,这本书值得从事计算机领域工作的同学一读。最后列出我的读书笔记思维导图:
