Spark RDD高级应用
教程目录
- 0x00 教程内容
- 0x01 向Spark传递参数的方式
- 1. 匿名函数
- 2. 传入静态方法和传入方法的引用
- 0x02 闭包
- 1. 闭包的概念
- 2. 闭包实操
- 3. 打印 RDD 的元素
- 0x03 共享变量
- 1. 广播变量
- 2. 累加器
- 0xFF 总结
0x00 教程内容
- 向Spark传递参数的两种方式
- 闭包的概念及实操
- 共享变量的两种方式
0x01 向Spark传递参数的方式
Spark 中的大部分操作都依赖于用户传递的函数,主要有两种方式:
方式一:匿名函数
方式二:传入静态方法和传入方法的引用
1. 匿名函数
在前面的教程中,我们用到了很多次这种方式,如这句:
val wordRDD = textFileRDD.flatMap(line => line.split(" "))
=> 左边是参数,参数可以省略参数类型,右边是函数体。
关于匿名函数:
var inc = (x:Int) => x+1
也可以这样写,可能会更易懂一点
var inc = ((x:Int) => x+1)
或者:
var inc = {(x:Int) => x+1}
其实这句匿名函数,跟下面这种写法是一样的意思:
def add2 = new Function1[Int,Int]{
def apply(x:Int):Int = x+1;
}
使用的时候,直接把 inc 当成函数名就可以了,Java 是一门面向对象的编程语言,一切皆对象;而 Scala 是一门面向函数的编程语言,一切皆函数!
使用方式:
inc(1)
或者:
var x = inc(7)-1
我们也可以在匿名函数中可以定义多个参数:
var mul = (x: Int, y: Int) => x*y
使用方式如下:
println(mul(3, 4))
我们也可以不给匿名函数设置参数:
var userDir = () => { System.getProperty("user.dir") }
使用方式如下:
println( userDir() )
2. 传入静态方法和传入方法的引用
我们可以传入全局单例对象的静态方法。比如:先定义 Object Functions,然后传递 Functions.func1。
val nums = sc.parallelize(List(1,2,3,4))
object Functions{
def func1(x:Int):Int = {x+1}
}
nums.map(Functions.func1).collect()
注意:虽然可以在同一个类实例中传递方法的引用,但是需要发送包含该类的对象连同该方法到集群,此过程会比仅传递静态方法到集群的开销更大。
0x02 闭包
1. 闭包的概念
闭包是一个函数,返回值依赖于声明在函数外部的一个或多个变量。
闭包可以简单的理解为:可以访问一个函数里面局部变量的另外一个函数。
2. 闭包实操
我们现在有个需求:计算所有元素的总和
val data = Array(1,2,3,4,5)
var counter = 0
var rdd = sc.parallelize(data)
rdd.foreach(x => counter+=x)
println("counter的值:" + counter)
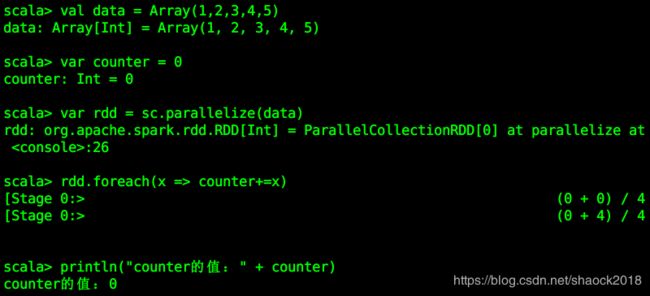
此时发现了一个问题,计算结果竟然是0!原因是在执行的时候,Spark会将 RDD 拆分成多个 task,并且分发给不同的执行器(executor)执行,而分发到每个执行器的counter是复制过去的,执行器之间不能相互访问,导致执行器在执行foreach方法的时候只能修改自己执行器中的值,驱动程序中的counter值没有被修改,所以最终输出的counter值依然是 0。这种场景有点像函数中参数的调用,调用的时候,应该传入变量的地址,否则,当需要调用的函数执行完结果后,不会把执行后的结果返回给主函数。
在上面的代码中,我们的foreach() 函数就是 闭包 。在执行的过程中,引用了函数外部的counter变量。
那我们可以怎么去解决以上的问题呢?
此时,我们可以使用共享全局变量的方式来解决:
val data = Array(1,2,3,4,5)
// 使用全局共享变量的累加器(accumulator)
val counter = sc.accumulator(0)
var rdd = sc.parallelize(data)
rdd.foreach(x => counter+=x)
println("counter的值:" + counter)
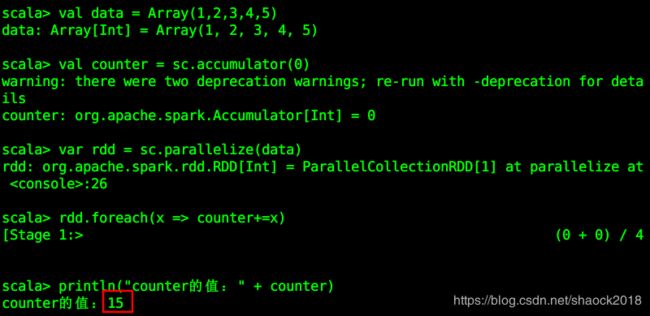
发现结果是对的,此时已经将 counter变量设置为共享全局变量。
Spark 有两种共享变量的方式:广播变量(broadcast variable)与累加器(accumulator),此处我们使用的是累加器,下面还会详细讲解。
3. 打印 RDD 的元素
- 如果是 Spark 是单机模式,可以使用
rdd.foreach(println)或rdd.map(println)来打印 RDD 的元素。但是如果是集群模式,就需要考虑闭包问题了,因为此时,执行器输出写入的是执行器的stdout,而不是驱动程序的stdout。所以如果那么要想在驱动程序中打印元素,可以怎么操作呢?
- 如果数据量不多的话可以使用
collect()方法:
rdd.collect().foreach(println);
- 如果数据量很大的话可以使用
take()方法:
rdd.take(num).foreach(println);
RDD 算子相关教程参考: Spark RDD的实操教程(二)
0x03 共享变量
Spark 为了能够让多节点之间共享变量,提供了两种方法:广播变量和累加器。
1. 广播变量
广播变量可以在每个节点上缓存一个只读的变量,可以提高数据的分配效率。
- 创建方式:
sc.broadcast(v)
可以在Spark Shell中执行:
// 创建广播变量
val broadcastVar = sc.broadcast(Array(1, 2, 3))
// 查看广播变量的值
broadcastVar.value

2. 累加器
累加器只能够通过加操作的变量,因此在并行操作中具备更高的效率,可以实现 counters和 sums。
可以在Spark Shell中执行:
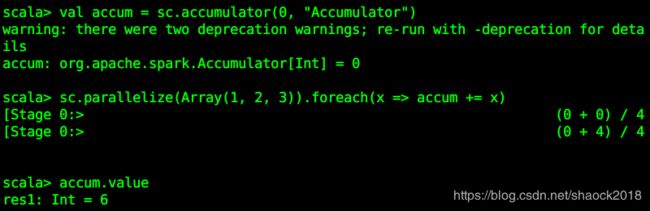
// 创建累加器
val accum = sc.accumulator(0, "Accumulator")
// 对RDD数据集的数值进行累加
sc.parallelize(Array(1, 2, 3)).foreach(x => accum += x)
// 查看累加器的结果
accum.value
0xFF 总结
- 本文介绍了向Spark传递参数的两种方式,其实一般只会用匿名函数这样的用法;闭包的概念其实也比较简单,需要理解;共享变量的两种方式必须要掌握,包括原理。
- 请继续学习相关课程,加油!
作者简介:邵奈一
全栈工程师、市场洞察者、专栏编辑
| 公众号 | 微信 | 微博 | CSDN | 简书 |
福利:
邵奈一的技术博客导航
邵奈一原创不易,如转载请标明出处,教育是一生的事业。