Hadoop-Mapreduce本地Windows和服务端Linux调试
Mapreduce本地Windows和服务端Linux调试
本地windows调试
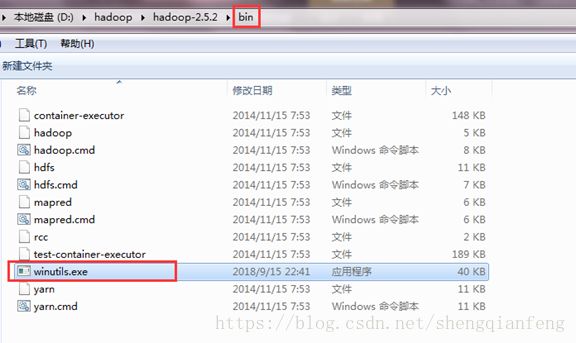
| 本地测试环境(windows): 在windows的hadoop目录bin目录有一个winutils.exe
配置完环境变量可能需要重启windows系统,如果不想重启可以在代码执行前加入:
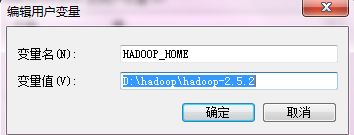
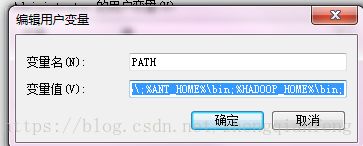
2 拷贝debug工具(winutils.ext)到HADOOP_HOME/bin
3 修改hadoop的源码 ,注意:确保项目的lib需要真实安装的jdk的lib
4、MR调用的代码需要改变: a、本地执行肯定src不能有服务器的hadoop配置文件,否则将读取服务器配置,就会把任务在服务器上执行。本地执行只是读取hdfs中的输入数据,利用本地代码进行计算。 b、在调用是使用:
|
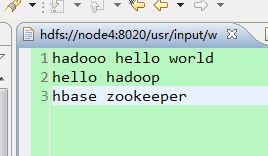
开始执行RunJob.java
package com.jeff.mr.wordCount;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
/**
* 案例1 :
* 在一个很大的文件中含有一行行的单词,每行的单词以空格分隔,计算每个单词出现的个数
* @author jeffSheng
* 2018年9月18日
*/
public class RunJob {
public static void main(String[] args) {
System.setProperty("hadoop.home.dir", "D:\\hadoop\\hadoop-2.5.2");
//初始化Configuration自动装载src或者class下的配置文件
Configuration config = new Configuration();
/**
指定nameNode主机名和端口,namenode主要做的就是读写文件,而如果想本地执行mapreduce,
输入数据还在hdfs上,需要将输入数据从hdfs取出来
*/
config.set("fs.defaultFS", "hdfs://node4:8020");
//指定resourceManager的主机名
config.set("yarn.resourcemanager.hostname", "node4");
try {
FileSystem fs =FileSystem.get(config);
//创建执行的任务,静态创建方式,传入config
Job job = Job.getInstance(config);
//设置入口类,就是当前类
job.setJarByClass(RunJob.class);
//设置job任务名称
job.setJobName("wordCount");
//job任务运行时Map Task执行类
job.setMapperClass(WordCountMapper.class);
//job任务运行时Reduce Task执行类
job.setReducerClass(WordCountReducer.class);
//map Task输出的key的类型,就是单词
job.setMapOutputKeyClass(Text.class);
//map Task输出的value的类型,就是单词出现数量
job.setMapOutputValueClass(IntWritable.class);
//先指定mapTask输入数据的目录:/usr/input/
FileInputFormat.addInputPath(job, new Path("/usr/input/"));
//指定输出数据的目录:/usr/output/wc
Path outpath =new Path("/usr/output/wc");
//判断目录是否存在,存在则递归删除
if(fs.exists(outpath)){
fs.delete(outpath, true);
}
//指定输出数据的目录
FileOutputFormat.setOutputPath(job, outpath);
//等待job任务完成
boolean f= job.waitForCompletion(true);
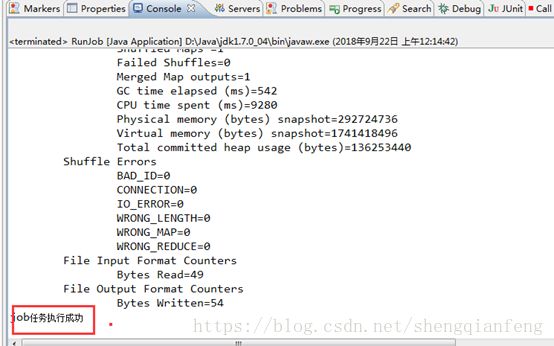
if(f){
System.out.println("job任务执行成功");
}
} catch (Exception e) {
e.printStackTrace();
}
}
}
WordCountMapper.java
package com.jeff.mr.wordCount;
import java.io.IOException;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.util.StringUtils;
/**
* Map Task定义
* 计算文件中单词出现次数和默认第一阶段洗牌
* @author jeffSheng
* 2018年9月18日
* 继承Mapper接口,泛型参数:
* Mapper
*
* KEYIN, VALUEIN
* mapTask输入数据从文件切割后的碎片段来的按照行去传递给MapTask,默认以数据行的下标为键值,类型为LongWritable,value为Text类型表示一行的数据
*
* KEYOUT, VALUEOUT
* mapTask的输出数据以单词为key,就是字符串类型Text,value则是单词的数量类型IntWritable
* Mapper
*/
public class WordCountMapper extends Mapper{
/**
* 该map方法循环调用,从文件的split碎片段中逐行即读取每行则调用一次,把该行所在的下标为key,该行的内容为value
*/
protected void map(LongWritable key, Text value,Context context) throws IOException, InterruptedException {
//value是split的每一行的值,在本例子中是空格分隔的字符串
String[] words = StringUtils.split(value.toString(), ' ');
for(String word :words){
//输出以单词word为键,1作为值的键值对,这里mapTask只是输出数据,统计则是在reduceTask
/**
* 输出数据会经历第一阶段洗牌,即分区,排序,合并,溢写。这些在mapTask端有默认的操作
*/
context.write(new Text(word), new IntWritable(1));
}
}
}
WordCountReducer.java
package com.jeff.mr.wordCount;
import java.io.IOException;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Reducer;
/**
* reduce Task定义
* mapTask第一阶段洗牌完成后输出数据传给reduce Task进行第二阶段的洗牌(分区,排序,分组)后作为reduce的输入,数据类型一致。
* Tips:分组后,每一组数据传给reduce Task,即每一组调用一次,这一组数据的特点是key相等,value可能是多个
* @author jeffSheng
* 2018年9月18日
*/
public class WordCountReducer extends Reducer{
//循环调用此方法,每组调用一次,这一组数据特点:key相同,value可能有多个。
/**
* Text arg0: 键,就是每一组中的key,即某个单词。
* Iterable arg1: 迭代器中可以拿到每一组中的所有值去迭代
*/
protected void reduce(Text arg0, Iterable arg1,Context arg2)
throws IOException, InterruptedException {
int sum =0;
for(IntWritable i: arg1){
sum=sum + i.get();
}
//输出以单词为key,总和为value的键值对
arg2.write(arg0, new IntWritable(sum));
}
}
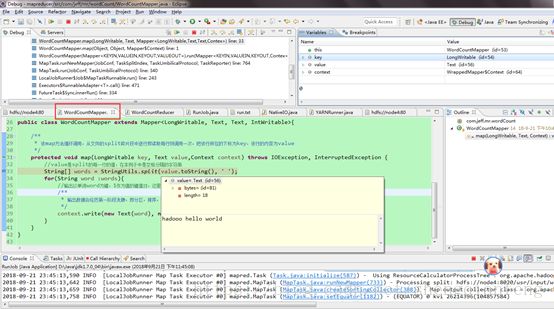
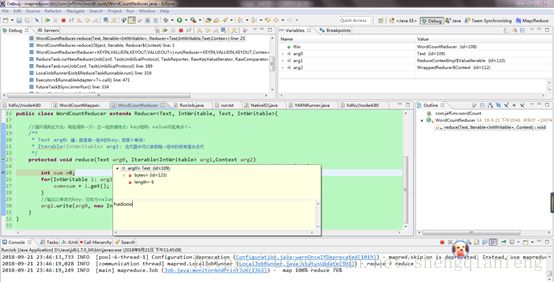
另外,本地还可以进行debug调试,查看MapTask 和reduce Task的执行过程:
Map Task:
Reduce Task:
| 2018-09-21 23:22:28,875 WARN [main] util.NativeCodeLoader (NativeCodeLoader.java: 2018-09-21 23:22:29,945 INFO [main] Configuration.deprecation (Configuration.java:warnOnceIfDeprecated(1019)) - session.id is deprecated. Instead, use dfs.metrics.session-id 2018-09-21 23:22:29,946 INFO [main] jvm.JvmMetrics (JvmMetrics.java:init(76)) - Initializing JVM Metrics with processName=JobTracker, sessionId= 2018-09-21 23:22:30,631 WARN [main] mapreduce.JobSubmitter (JobSubmitter.java:copyAndConfigureFiles(150)) - Hadoop command-line option parsing not performed. Implement the Tool interface and execute your application with ToolRunner to remedy this. 2018-09-21 23:22:30,702 WARN [main] mapreduce.JobSubmitter (JobSubmitter.java:copyAndConfigureFiles(259)) - No job jar file set. User classes may not be found. See Job or Job#setJar(String). 2018-09-21 23:22:30,864 INFO [main] input.FileInputFormat (FileInputFormat.java:listStatus(281)) - Total input paths to process : 1 2018-09-21 23:22:31,187 INFO [main] mapreduce.JobSubmitter (JobSubmitter.java:submitJobInternal(396)) - number of splits:1 2018-09-21 23:22:31,554 INFO [main] mapreduce.JobSubmitter (JobSubmitter.java:printTokens(479)) - Submitting tokens for job: job_local1249666866_0001 2018-09-21 23:22:31,609 WARN [main] conf.Configuration (Configuration.java:loadProperty(2368)) - file:/tmp/hadoop-Administrator/mapred/staging/Administrator1249666866/.staging/job_local1249666866_0001/job.xml:an attempt to override final parameter: mapreduce.job.end-notification.max.retry.interval; Ignoring. 2018-09-21 23:22:31,616 WARN [main] conf.Configuration (Configuration.java:loadProperty(2368)) - file:/tmp/hadoop-Administrator/mapred/staging/Administrator1249666866/.staging/job_local1249666866_0001/job.xml:an attempt to override final parameter: mapreduce.job.end-notification.max.attempts; Ignoring. 2018-09-21 23:22:32,080 WARN [main] conf.Configuration (Configuration.java:loadProperty(2368)) - file:/tmp/hadoop-Administrator/mapred/local/localRunner/Administrator/job_local1249666866_0001/job_local1249666866_0001.xml:an attempt to override final parameter: mapreduce.job.end-notification.max.retry.interval; Ignoring. 2018-09-21 23:22:32,087 WARN [main] conf.Configuration (Configuration.java:loadProperty(2368)) - file:/tmp/hadoop-Administrator/mapred/local/localRunner/Administrator/job_local1249666866_0001/job_local1249666866_0001.xml:an attempt to override final parameter: mapreduce.job.end-notification.max.attempts; Ignoring. 2018-09-21 23:22:32,095 INFO [main] mapreduce.Job (Job.java:submit(1289)) - The url to track the job: http://localhost:8080/ 2018-09-21 23:22:32,096 INFO [main] mapreduce.Job (Job.java:monitorAndPrintJob(1334)) - Running job: job_local1249666866_0001 2018-09-21 23:22:32,097 INFO [Thread-12] mapred.LocalJobRunner (LocalJobRunner.java:createOutputCommitter(471)) - OutputCommitter set in config null 2018-09-21 23:22:32,127 INFO [Thread-12] mapred.LocalJobRunner (LocalJobRunner.java:createOutputCommitter(489)) - OutputCommitter is org.apache.hadoop.mapreduce.lib.output.FileOutputCommitter 2018-09-21 23:22:32,364 INFO [Thread-12] mapred.LocalJobRunner (LocalJobRunner.java:runTasks(448)) - Waiting for map tasks 2018-09-21 23:22:32,364 INFO [LocalJobRunner Map Task Executor #0] mapred.LocalJobRunner (LocalJobRunner.java:run(224)) - Starting task: attempt_local1249666866_0001_m_000000_0 2018-09-21 23:22:32,498 INFO [LocalJobRunner Map Task Executor #0] util.ProcfsBasedProcessTree (ProcfsBasedProcessTree.java:isAvailable(181)) - ProcfsBasedProcessTree currently is supported only on Linux. 2018-09-21 23:22:32,616 INFO [LocalJobRunner Map Task Executor #0] mapred.Task (Task.java:initialize(587)) - Using ResourceCalculatorProcessTree : org.apache.hadoop.yarn.util.WindowsBasedProcessTree@759006d2 2018-09-21 23:22:32,624 INFO [LocalJobRunner Map Task Executor #0] mapred.MapTask (MapTask.java:runNewMapper(733)) - Processing split: hdfs://node4:8020/usr/input/wc.txt:0+49 2018-09-21 23:22:32,647 INFO [LocalJobRunner Map Task Executor #0] mapred.MapTask (MapTask.java:createSortingCollector(388)) - Map output collector class = org.apache.hadoop.mapred.MapTask$MapOutputBuffer 2018-09-21 23:22:32,746 INFO [LocalJobRunner Map Task Executor #0] mapred.MapTask (MapTask.java:setEquator(1182)) - (EQUATOR) 0 kvi 26214396(104857584) 2018-09-21 23:22:32,746 INFO [LocalJobRunner Map Task Executor #0] mapred.MapTask (MapTask.java:init(975)) - mapreduce.task.io.sort.mb: 100 2018-09-21 23:22:32,747 INFO [LocalJobRunner Map Task Executor #0] mapred.MapTask (MapTask.java:init(976)) - soft limit at 83886080 2018-09-21 23:22:32,747 INFO [LocalJobRunner Map Task Executor #0] mapred.MapTask (MapTask.java:init(977)) - bufstart = 0; bufvoid = 104857600 2018-09-21 23:22:32,747 INFO [LocalJobRunner Map Task Executor #0] mapred.MapTask (MapTask.java:init(978)) - kvstart = 26214396; length = 6553600 2018-09-21 23:22:33,099 INFO [main] mapreduce.Job (Job.java:monitorAndPrintJob(1355)) - Job job_local1249666866_0001 running in uber mode : false 2018-09-21 23:22:33,113 INFO [main] mapreduce.Job (Job.java:monitorAndPrintJob(1362)) - map 0% reduce 0% 2018-09-21 23:22:34,344 INFO [LocalJobRunner Map Task Executor #0] mapred.LocalJobRunner (LocalJobRunner.java:statusUpdate(591)) - 2018-09-21 23:22:34,353 INFO [LocalJobRunner Map Task Executor #0] mapred.MapTask (MapTask.java:flush(1437)) - Starting flush of map output 2018-09-21 23:22:34,353 INFO [LocalJobRunner Map Task Executor #0] mapred.MapTask (MapTask.java:flush(1455)) - Spilling map output 2018-09-21 23:22:34,353 INFO [LocalJobRunner Map Task Executor #0] mapred.MapTask (MapTask.java:flush(1456)) - bufstart = 0; bufend = 76; bufvoid = 104857600 2018-09-21 23:22:34,353 INFO [LocalJobRunner Map Task Executor #0] mapred.MapTask (MapTask.java:flush(1458)) - kvstart = 26214396(104857584); kvend = 26214372(104857488); length = 25/6553600 2018-09-21 23:22:34,450 INFO [LocalJobRunner Map Task Executor #0] mapred.MapTask (MapTask.java:sortAndSpill(1641)) - Finished spill 0 2018-09-21 23:22:34,475 INFO [LocalJobRunner Map Task Executor #0] mapred.Task (Task.java:done(1001)) - Task:attempt_local1249666866_0001_m_000000_0 is done. And is in the process of committing 2018-09-21 23:22:34,486 INFO [LocalJobRunner Map Task Executor #0] mapred.LocalJobRunner (LocalJobRunner.java:statusUpdate(591)) - map 2018-09-21 23:22:34,486 INFO [LocalJobRunner Map Task Executor #0] mapred.Task (Task.java:sendDone(1121)) - Task 'attempt_local1249666866_0001_m_000000_0' done. 2018-09-21 23:22:34,487 INFO [LocalJobRunner Map Task Executor #0] mapred.LocalJobRunner (LocalJobRunner.java:run(249)) - Finishing task: attempt_local1249666866_0001_m_000000_0 2018-09-21 23:22:34,513 INFO [Thread-12] mapred.LocalJobRunner (LocalJobRunner.java:runTasks(456)) - map task executor complete. 2018-09-21 23:22:34,516 INFO [Thread-12] mapred.LocalJobRunner (LocalJobRunner.java:runTasks(448)) - Waiting for reduce tasks 2018-09-21 23:22:34,527 INFO [pool-6-thread-1] mapred.LocalJobRunner (LocalJobRunner.java:run(302)) - Starting task: attempt_local1249666866_0001_r_000000_0 2018-09-21 23:22:34,537 INFO [pool-6-thread-1] util.ProcfsBasedProcessTree (ProcfsBasedProcessTree.java:isAvailable(181)) - ProcfsBasedProcessTree currently is supported only on Linux. 2018-09-21 23:22:34,595 INFO [pool-6-thread-1] mapred.Task (Task.java:initialize(587)) - Using ResourceCalculatorProcessTree : org.apache.hadoop.yarn.util.WindowsBasedProcessTree@2642b4bb 2018-09-21 23:22:34,625 INFO [pool-6-thread-1] mapred.ReduceTask (ReduceTask.java:run(362)) - Using ShuffleConsumerPlugin: org.apache.hadoop.mapreduce.task.reduce.Shuffle@575dcfa4 2018-09-21 23:22:34,640 INFO [pool-6-thread-1] reduce.MergeManagerImpl (MergeManagerImpl.java: 2018-09-21 23:22:34,643 INFO [EventFetcher for fetching Map Completion Events] reduce.EventFetcher (EventFetcher.java:run(61)) - attempt_local1249666866_0001_r_000000_0 Thread started: EventFetcher for fetching Map Completion Events 2018-09-21 23:22:34,693 INFO [localfetcher#1] reduce.LocalFetcher (LocalFetcher.java:copyMapOutput(140)) - localfetcher#1 about to shuffle output of map attempt_local1249666866_0001_m_000000_0 decomp: 92 len: 96 to MEMORY 2018-09-21 23:22:34,766 INFO [localfetcher#1] reduce.InMemoryMapOutput (InMemoryMapOutput.java:shuffle(100)) - Read 92 bytes from map-output for attempt_local1249666866_0001_m_000000_0 2018-09-21 23:22:34,795 INFO [localfetcher#1] reduce.MergeManagerImpl (MergeManagerImpl.java:closeInMemoryFile(307)) - closeInMemoryFile -> map-output of size: 92, inMemoryMapOutputs.size() -> 1, commitMemory -> 0, usedMemory ->92 2018-09-21 23:22:34,897 INFO [EventFetcher for fetching Map Completion Events] reduce.EventFetcher (EventFetcher.java:run(76)) - EventFetcher is interrupted.. Returning 2018-09-21 23:22:34,898 INFO [pool-6-thread-1] mapred.LocalJobRunner (LocalJobRunner.java:statusUpdate(591)) - 1 / 1 copied. 2018-09-21 23:22:34,953 INFO [pool-6-thread-1] reduce.MergeManagerImpl (MergeManagerImpl.java:finalMerge(667)) - finalMerge called with 1 in-memory map-outputs and 0 on-disk map-outputs 2018-09-21 23:22:35,004 INFO [pool-6-thread-1] mapred.Merger (Merger.java:merge(591)) - Merging 1 sorted segments 2018-09-21 23:22:35,005 INFO [pool-6-thread-1] mapred.Merger (Merger.java:merge(690)) - Down to the last merge-pass, with 1 segments left of total size: 83 bytes 2018-09-21 23:22:35,008 INFO [pool-6-thread-1] reduce.MergeManagerImpl (MergeManagerImpl.java:finalMerge(742)) - Merged 1 segments, 92 bytes to disk to satisfy reduce memory limit 2018-09-21 23:22:35,009 INFO [pool-6-thread-1] reduce.MergeManagerImpl (MergeManagerImpl.java:finalMerge(772)) - Merging 1 files, 96 bytes from disk 2018-09-21 23:22:35,026 INFO [pool-6-thread-1] reduce.MergeManagerImpl (MergeManagerImpl.java:finalMerge(787)) - Merging 0 segments, 0 bytes from memory into reduce 2018-09-21 23:22:35,026 INFO [pool-6-thread-1] mapred.Merger (Merger.java:merge(591)) - Merging 1 sorted segments 2018-09-21 23:22:35,028 INFO [pool-6-thread-1] mapred.Merger (Merger.java:merge(690)) - Down to the last merge-pass, with 1 segments left of total size: 83 bytes 2018-09-21 23:22:35,065 INFO [pool-6-thread-1] mapred.LocalJobRunner (LocalJobRunner.java:statusUpdate(591)) - 1 / 1 copied. 2018-09-21 23:22:35,125 INFO [main] mapreduce.Job (Job.java:monitorAndPrintJob(1362)) - map 100% reduce 0% 2018-09-21 23:22:35,213 INFO [pool-6-thread-1] Configuration.deprecation (Configuration.java:warnOnceIfDeprecated(1019)) - mapred.skip.on is deprecated. Instead, use mapreduce.job.skiprecords 2018-09-21 23:22:35,592 INFO [pool-6-thread-1] mapred.Task (Task.java:done(1001)) - Task:attempt_local1249666866_0001_r_000000_0 is done. And is in the process of committing 2018-09-21 23:22:35,597 INFO [pool-6-thread-1] mapred.LocalJobRunner (LocalJobRunner.java:statusUpdate(591)) - 1 / 1 copied. 2018-09-21 23:22:35,598 INFO [pool-6-thread-1] mapred.Task (Task.java:commit(1162)) - Task attempt_local1249666866_0001_r_000000_0 is allowed to commit now 2018-09-21 23:22:35,644 INFO [pool-6-thread-1] output.FileOutputCommitter (FileOutputCommitter.java:commitTask(439)) - Saved output of task 'attempt_local1249666866_0001_r_000000_0' to hdfs://node4:8020/usr/output/wc/_temporary/0/task_local1249666866_0001_r_000000 2018-09-21 23:22:35,647 INFO [pool-6-thread-1] mapred.LocalJobRunner (LocalJobRunner.java:statusUpdate(591)) - reduce > reduce 2018-09-21 23:22:35,647 INFO [pool-6-thread-1] mapred.Task (Task.java:sendDone(1121)) - Task 'attempt_local1249666866_0001_r_000000_0' done. 2018-09-21 23:22:35,647 INFO [pool-6-thread-1] mapred.LocalJobRunner (LocalJobRunner.java:run(325)) - Finishing task: attempt_local1249666866_0001_r_000000_0 2018-09-21 23:22:35,648 INFO [Thread-12] mapred.LocalJobRunner (LocalJobRunner.java:runTasks(456)) - reduce task executor complete. 2018-09-21 23:22:36,125 INFO [main] mapreduce.Job (Job.java:monitorAndPrintJob(1362)) - map 100% reduce 100% 2018-09-21 23:22:36,126 INFO [main] mapreduce.Job (Job.java:monitorAndPrintJob(1373)) - Job job_local1249666866_0001 completed successfully 2018-09-21 23:22:36,146 INFO [main] mapreduce.Job (Job.java:monitorAndPrintJob(1380)) - Counters: 38 File System Counters FILE: Number of bytes read=546 FILE: Number of bytes written=487750 FILE: Number of read operations=0 FILE: Number of large read operations=0 FILE: Number of write operations=0 HDFS: Number of bytes read=98 HDFS: Number of bytes written=54 HDFS: Number of read operations=17 HDFS: Number of large read operations=0 HDFS: Number of write operations=4 Map-Reduce Framework Map input records=3 Map output records=7 Map output bytes=76 Map output materialized bytes=96 Input split bytes=99 Combine input records=0 Combine output records=0 Reduce input groups=6 Reduce shuffle bytes=96 Reduce input records=7 Reduce output records=6 Spilled Records=14 Shuffled Maps =1 Failed Shuffles=0 Merged Map outputs=1 GC time elapsed (ms)=54 CPU time spent (ms)=0 Physical memory (bytes) snapshot=0 Virtual memory (bytes) snapshot=0 Total committed heap usage (bytes)=1029046272 Shuffle Errors BAD_ID=0 CONNECTION=0 IO_ERROR=0 WRONG_LENGTH=0 WRONG_MAP=0 WRONG_REDUCE=0 File Input Format Counters Bytes Read=49 File Output Format Counters Bytes Written=54 job任务执行成功
|
服务器Linux执行方式
方式1:
这个方式就是把程序打jar包上传到ResourceManager节点上使用命令手动执行:
| 直接在服务器上,使用命令的方式调用,执行过程也在服务器上 a、把MR程序打包(jar),传送到服务器上 b、通过: hadoop jar jar路径 类的全限定名 |
之前我们已经测试过了!
方式2:
这种方式也是将jar提交到Hadoop的ResourceManager上执行,但是不是通过命令,而是通过本地执行main方法执行,其实就是程序将本地的jar提交到服务器上去执行的。
| 首先需要在src下放置服务器上的hadoop配置文件,这几个文件直接从服务器上下载下来放到src下。
1、在本地直接调用,执行过程在服务器上(真正企业运行环境) a、把MR程序打包(jar),直接放到本地,打包方式跟之前案例1-wordCount是一样的。
b、修改hadoop的源码 ,注意:确保项目的lib需要真实安装的jdk的lib
c、增加一个属性: d、本地执行main方法,servlet调用MR。 |

问题:执行报错,原因是本地windows的用户名跟hadoop的用户名不一致,解决办法可以设置hadoop的用户登录名。
org.apache.hadoop.security.AccessControlException: Permission denied: user=Administrator, access=EXECUTE, inode="/tmp":root:supergroup:drwx------
这个错误,解决办法:System.setProperty("HADOOP_USER_NAME", "root")
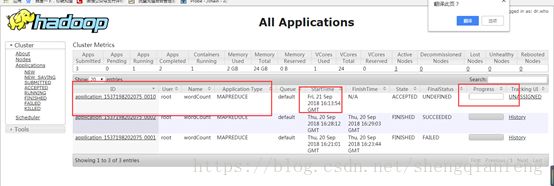
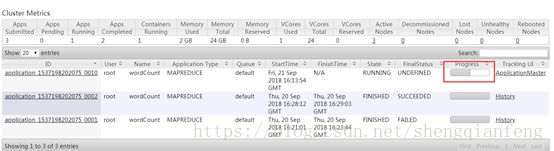
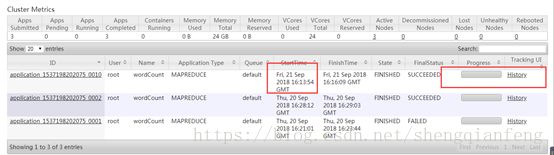
将任务jar提交到ResourceManager上去执行
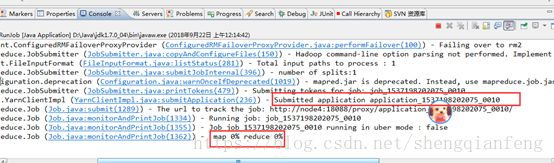
看到在http://node4:18088/cluster有了我们新提交的任务,需要注意的是如果我们测试的是本地windows执行则不会在这里看到,因为计算程序是在本地eclipse运行的,而不是现在这样提交给了ResourceManager执行。
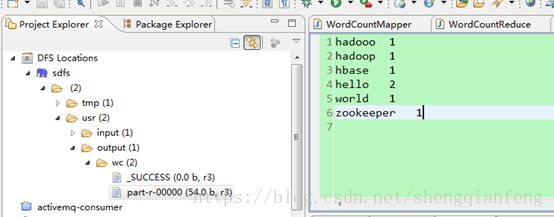
以上三种方式都可以实现!