大数据014——Storm 集群及入门案例
分布式实时数据处理框架——Storm
1. Storm 集群
1.1 Storm 版本变更
| 版本 | 编写语言 | 重要特性 | HA 高可用 |
|---|---|---|---|
| 0.9.x | java+clojule | 改进与Kafka、HDFS、HBase的集成 | 不支持,storm集群只支持一个nimbus节点 |
| 0.10.x | 1. 增强安全性和多用户调度部署 2. 更加方便版本升级 3. Storm 0.10.0集成了Flux框架,该框架能使Storm拓扑的定义和部署变得更加简洁方便 4. 新的分组策略:局部关键词分组策略 5. 改进型日志框架 6. 与Apache Hive的整合 7. 支持Redis 8. JDBC/RDBMS的整合 |
支持,storm集群可以支持多个nimbus节点,其中有一个为leader,负责真正运行,其余的为offline | |
| 1.x.x | 1. 性能提升,Storm 1.0的速度能够提升至16倍 2. Pacemaker-心跳服务器 3. 分布式缓存API 4. Nimbus的HA高可用 5. 原生本地流式窗口API 6. 状态管理-自动Checkpoint的有状态的Bolt 7. 自动反压机制 8. 资源感知调度器 9. 动态的日志等级 10. Tuple采样和调试 11. 分布式的日志查找 12. 动态的Worker性能分析 |
||
| 2.x.x | java | STORM::Wave Creator、STORM::Ice Blast、STORM::sandMan、STORM::Unfold、STORM::Volume Lattic、STORM::Tree、... |
1)、python 2.6 及以上(centos 6.8 系统自带),如本机:
[root@node01 ~]# python
Python 2.6.6 (r266:84292, Jan 22 2014, 09:42:36)
[GCC 4.4.7 20120313 (Red Hat 4.4.7-4)] on linux2
Type "help", "copyright", "credits" or "license" for more information.
>>> exit()
[root@node01 ~]#
2)、JDK 1.7及以上,并配置环境变量;
3)、集群之间 ssh 免密登录;
4)、zookeeper 集群,Storm 集群是依赖于zookeeper的。
1.3 Storm 集群安装
1)、下载 Storm 的安装包 http://storm.apache.org/downloads.html,这里使用apache-storm-1.0.2.tar.gz;
2)、上传到某一节点并解压;
3)、修改配置文件
cd apache-storm-1.0.2/conf
vim storm.yaml
修改:
# Storm 集群对应的 ZooKeeper 集群的主机列表
storm.zookeeper.servers:
- "node01"
- "node02"
- "node03"
# HA高可用时可以指定多个nimbus主节点
nimbus.seeds: ["node01","node02"]
# 注意:nimbus.seeds指定的时候最好指定主机名,否则在webui界面查询的时候会重复显示节点信息。
# 使用的本地文件系统目录(必须存在并且 Storm 可读写)
storm.local.dir: "/usr/local/storm/data"
#superviso 上能够运行 workers 的端口列表,每个 worker占用一个端口,且每个端口只运行一个 worker,通过这项配置可以调整每台机器上运行的 worker 数
supervisor.slots.ports:
- 6700
- 6701
- 6702
- 6703
4)、将 Storm 发送到其它节点。
1.4 启动 Storm 集群
1)、事先启动zookeeper集群;
2)、启动 nimbus 节点
node01、node02:
bin/storm nimbus
后台启动不占用命令行:nohup bin/storm nimbus >/dev/null 2>&1 &
3)、启动 Supervisor 节点,打开另一个终端窗口
node02、node03:
bin/storm supervisor
后台启动不占用命令行:nohup bin/storm supervisor >/dev/null 2>&1 &
4)、启动日志展示服务
node01、node02、node03:
bin/storm logviewer
后台启动不占用命令行:nohup bin/storm logviewer >/dev/null 2>&1 &
5)、启动 UI,再打开另一个终端窗口
node01:
bin/storm ui
后台启动不占用命令行:nohup bin/storm ui >/dev/null 2>&1 &
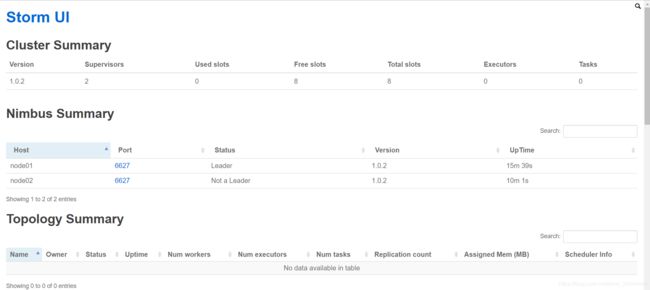
- 启动 Storm 用户界面应用程序后,在浏览器中键入 http:// node01:8080,可以看到 Storm 集群信息及其运行的拓扑,图示如下:
6)、关闭 Storm 集群
上述第一种启动防止可以直接关闭终端窗口或 ctrl+c 关闭,第二种启动方式前期请直接杀死进程。
2. Storm 入门案例(集群模式)
通过Strom API 编写入门案例,在非集群的本地环境下运行体验 Storm 实时处理数据的底层实现,有助于更好的理解 Storm 实时数据处理的开发流程。
2.1 数字累加操作
| 业务 | 对1,2,3,4....这种递增数字进行累加求和 | |
| topology | spout | 负责产生从1开始的递增数据,每次加1 |
| bolt | 负责对spout发送出来的数据进行累加求和 | |
- eclipse 开发工具借助 Maven 环境新建项目;
- 添加 Storm 依赖:
<dependency>
<groupId>org.apache.stormgroupId>
<artifactId>storm-coreartifactId>
<version>1.2.2version>
dependency>
- 编写代码:
public class RemoteTopology {
/**
* 自定义的spout需要继承BaseRichSpout
*/
public static class MySpout extends BaseRichSpout{
private Map conf;
private TopologyContext context;
private SpoutOutputCollector collector;
/**
* 初始化方法,在spout组件初始化的时候只执行一次;执行初始化操作,如:如果需要实现对mysql的操 * 作,需要使用连接池,那么连接池初始化的代码就需要放在open方法里面。
* Map conf:其实是storm的配置类,这里面可以保存一个配置信息在storm中进行传递。
* TopologyContext context:topology的上下文对象
* SpoutOutputCollector collector:发射器,负责发射数据
*/
@Override
public void open(Map conf, TopologyContext context,
SpoutOutputCollector collector) {
this.conf = conf;
this.context = context;
this.collector = collector;
}
/**
* 这个方法会被框架一直调用,死循环的调用
* spout负责在nextTuple中向外发射数据
* 这个方法每执行一次,都会向外发射一条数据。
*/
int num=0;
@Override
public void nextTuple() {
num++;//这样就可以产生递增的数字
this.collector.emit(new Values(num));
System.out.println("spout:"+num);
Utils.sleep(1000);//线程休眠1000sm,防止耗尽资源
}
/**
* 声明输出字段
* 这个方法也是在开始执行一次
*/
@Override
public void declareOutputFields(OutputFieldsDeclarer declarer) {
//注意:Fields中封装的字段和values中封装的数据是一一对应的
declarer.declare(new Fields("num"));
}
}
/**
* 自定义的bolt需要继承baserichbolt
*/
public static class SumBolt extends BaseRichBolt{
private Map stormConf;
private TopologyContext context;
private OutputCollector collector;
/**
* 是一个初始化方法,也是只会执行一次
*/
@Override
public void prepare(Map stormConf, TopologyContext context,
OutputCollector collector) {
this.stormConf = stormConf;
this.context = context;
this.collector = collector;
}
/**
* 这个方法也会执行很多次,只要上一个组件发射一条数据,那么这个bolt就收到这个条数据,然后调用 * execute方法去处理数据
*/
int sum = 0;
@Override
public void execute(Tuple input) {
Integer num = input.getIntegerByField("num");
//因为tuple其实就是一个list,list有角标,所以也可以通过脚本获取数据
//Integer num = input.getInteger(0);
sum+=num;
System.out.println("和为:"+sum);
//注意:这个bolt已经是最后一个bolt了,所以就不需要向外面发射数据了,也就不用调用emit方法了。
}
/**
* 注意:如果这个组件没有调用emit向外发射数据,那么这个方法就不需要实现。
* 如果这个组件向外发射了数据,那么在这个方法内部必须要声明输出字段。
*/
@Override
public void declareOutputFields(OutputFieldsDeclarer declarer) {
}
}
public static void main(String[] args) {
//把spout和bolt组装成一个topology去执行
TopologyBuilder topologyBuilder = new TopologyBuilder();
topologyBuilder.setSpout("spoutid", new MySpout());
topologyBuilder.setBolt("boltid", new SumBolt()).shuffleGrouping("spoutid");
//拓扑的名称
String simpleName = RemoteTopology.class.getSimpleName();
//配置类
Config config = new Config();
try {
//在集群运行
StormSubmitter.submitTopology(simpleName, config, topologyBuilder.createTopology());
} catch (AlreadyAliveException e) {
e.printStackTrace();
} catch (InvalidTopologyException e) {
e.printStackTrace();
} catch (AuthorizationException e) {
e.printStackTrace();
}
}
}
-
将项目打成 jar 包上传至服务器;
-
把jar包提交到storm集群运行:
bin/storm jar storm.jar com.xxx.xxx.RemoteTopology
[root@node01 apache-storm-1.0.2]# bin/storm jar mystorm.jar com.bigdata1024.mystorm.RemoteTopology
Running: java -client -Ddaemon.name= -Dstorm.options= -Dstorm.home=/home/apache-
......{"storm.zookeeper.topology.auth.scheme":"digest","storm.zookeeper.topology.auth.payload":"-7388545638023553246:-6649187761340360334"}
1030 [main] INFO o.a.s.StormSubmitter - Finished submitting topology: RemoteTopology
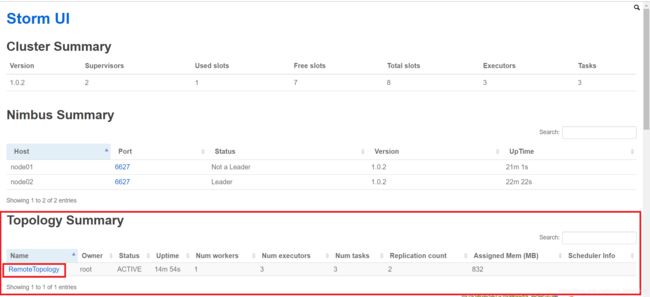
- WebUI查看Topology Summary,点击RemoteTopology:
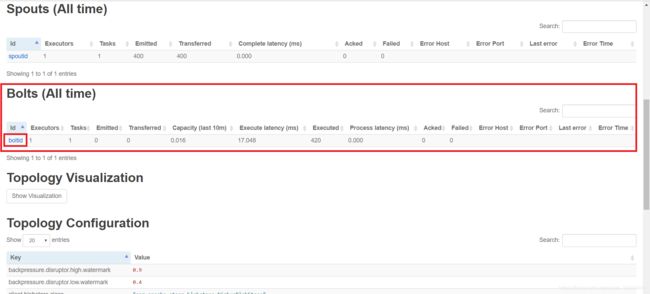
- 查看Bolts(All time),点击boltid
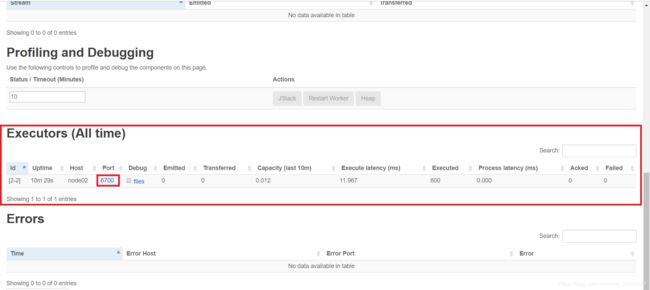
- 查看Executors(All time),点击端口号6700
- 日志信息如下:
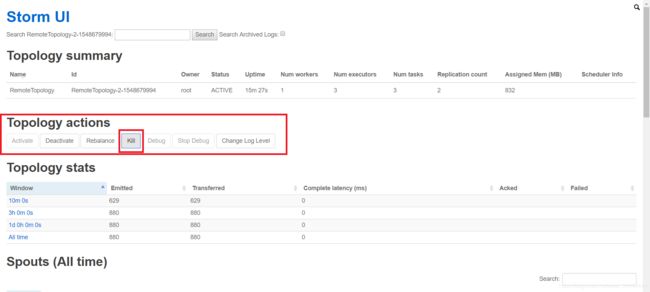
6)、停止Topology任务,选择Topology actions,点击 Kill:
3. Storm 并行度
提高storm的某一个组件的并行度可以提高storm程序的处理能力。并行度可以简单理解为多线程。并行度是针对某一个组件(spout/bolt)而言的。
该如何提高storm的并行度呢,首先storm程序是由spout和bolt组成的。而spout和bolt在运行的时候会生成 task(new spout()/new bolt())task 是一个实例对象,实例对象想要运行时需要依赖于线程的;而线程需要在进程内运行;而进程是需要在服务器上创建的。所以可以从下面几个方法:
-
最直接的就是提高线程的数量(最直接的)。
例如:本来bolt组件使用一个线程去运行,那么并行度就是一
如果bolt组件使用两个线程去运行,那么并行度就是二;如设置线程数为3:
topologyBuilder.setBolt("boltid", new SumBolt(),3).shuffleGrouping("spoutid"); -
提高进程的数量(间接)
因为每个进程里面运行的线程个数是有限的,线程太多的话会导致线程之间竞争抢资源。
例如:本来一个进程内部运行了100个线程。可能这个进程中运行10个线程效率最高,所以针对这100个线程可以分配10个进程。这样的话效率就高了。 如设置2个worker:
config.setNumWorkers(2);//注意:默认每一个worker进程中都有一个acker线程 -
提高task数量(间接)
正常情况下,每一个线程中只会创建一个task实例。因为一个线程同时也就只能运行一个task实例。在进程里面,可以并行运行线程,但是在线程内部,就不支持并行运行task了。 如设置task数为3:
topologyBuilder.setBolt("boltid", new SumBolt(),3).setNumTasks(3).shuffleGrouping("spoutid"); 提高task的数量,并不能直接影响组件的并行度和处理能力,那为什么还要提高task的数量呢?因为提高task的数量,可以方便后期动态调整某一个组件的并行度。【是因为:当一个topology提交到集群之后,这个topopology中每个组件创建的task数目就不会变了,而每一个task最多只能让一个线程去执行。但是每个组件的线程数量可能会发生变化例如:remotetopology是由一个spout和一个bolt组成的。正常情况下每个组件只会占用生成一个task,使用一个线程去执行。这样当代码提交到集群之后,后期就不能动态调整组件的线程数了.】
注意:因为一个supervisor节点最多可以启动4个worker进程,每一个topology默认占用一个worker进程
所以两个从节点的集群最多可以运行8个topology。