HIVE 的窗口函数理论与实践
写自定义目录标题
- 欢迎使用Markdown编辑器
- 二 实践
- 数据准备
- 1: LEAD与 LAG 、first_value
- 3: first_value 与Last_value
- 2: 聚合函数 SUM、AVG、MIN、MAX
- 3:序列函数 NTILE、ROW_NUMBER、RANK、DENSE_RANK
- 4 序列函数 cume_DIST,Percent_rank
- 5 # GROUPING SETS,GROUPING__ID,CUBE,ROLLUP
写自定义目录标题
- 欢迎使用Markdown编辑器
- 二 实践
- 数据准备
- 1: LEAD与 LAG 、first_value
- 3: first_value 与Last_value
- 2: 聚合函数 SUM、AVG、MIN、MAX
- 3:序列函数 NTILE、ROW_NUMBER、RANK、DENSE_RANK
- 4 序列函数 cume_DIST,Percent_rank
- 5 # GROUPING SETS,GROUPING__ID,CUBE,ROLLUP
欢迎使用Markdown编辑器
二 实践
数据准备
#建表、造数据
create table window_temp(
uname string,
create_time string,
pv String)
row format delimited fields terminated by ',';
insert overwrite table window_temp
select
split(detail,',')[0] as uname
,split(detail,',')[1] as create_time
,split(detail,',')[2] as pv
from
(
select
regexp_replace(
concat(
'u1,2019-10-02,7
#u1,2019-10-05,4
#u1,2019-10-07,5
#u1,2019-10-03,6
#u1,2019-10-04,3
#u1,2019-10-01,3
#u2,2019-10-06,4
#u2,2019-10-04,3
#u2,2019-10-01,3
#u2,2019-10-03,6
#u2,2019-10-06,4'),
'\n',''
) as ct_str
) t
lateral view explode(split(ct_str,'#')) t2 as detail;
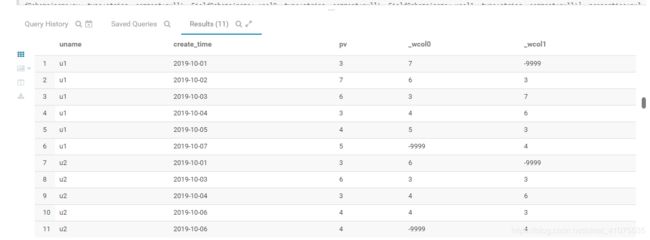
1: LEAD与 LAG 、first_value
备注:不支持window字句
1:LEAD(col,n,DEFAULT) 用于统计窗口内往下第n行值。第一个参数为列名, 第二个是窗口内的第几列,第三个为默认值,当取值为null时就取这个值。
2:LAG(col,n,DEFAULT) 与Lead相反,原理和Lead一致,区别点是在Lag窗口内按照倒序取
select uname,create_time,pv ,lead(pv,1,-9999) over(partition by uname order by create_time) ,lag(pv,1,-9999) over(partition by uname order by create_time) from window_temp
OUT:
3: first_value 与Last_value
1:first_value 取窗口内第一行
2:Last_value 取窗口内最后一行,
select uname,create_time,pv ,
row_number() over (partition by uname order by create_time ) as rn,-- 给窗口内数据排序
first_value(pv) over (partition by uname order by create_time asc ) as first_rn, – 取窗口内的第一行
last_value(pv) over (partition by uname order by create_time desc ) as last_rn – 取窗口内最后一行
from window_temp

2: 聚合函数 SUM、AVG、MIN、MAX
还可以对窗口内的数据求聚合运算,适合求占比、求与均值差异的运算
窗口函数里的关键字:
preceding: 往前
current row: 当前行
following: 往后
unbounded: 起点,UNBOUNDED PRECEDING 表示从前面的起点,UNBOUNDED FOLLOWING,表示到后面的终点行
select uname,create_time,pv,
sum(pv) over(partition by uname ) as pv, -- 统计窗口内所有行
sum(pv) over(partition by uname order by create_time ) as pv1, -- 求窗口内的和,默认为窗口起点到当前行
sum(pv) over(partition by uname order by create_time rows between unbounded preceding and current row ) as pv2, -- 同pv1,窗口起点到当前行
sum(pv) over(partition by uname order by create_time rows between 2 preceding and current row ) as pv3, -- 当前行+往前2行
sum(pv) over(partition by uname order by create_time rows between 2 preceding and unbounded FOLLOWING ) as pv4, -- 当前行的前两行+往后所有行
sum(pv) over(partition by uname order by create_time rows between 3 preceding and 1 following) as pv5, -- 当前行+前三行+往后一行
sum( case when uname='u1' then pv else 0 end) over(partition by uname ) as pv6 -- 对窗口内的数据过滤
from window_temp

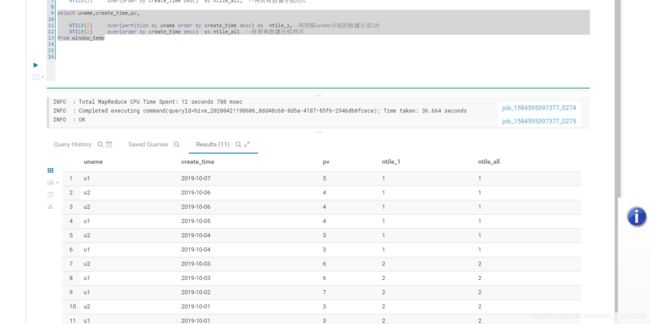
3:序列函数 NTILE、ROW_NUMBER、RANK、DENSE_RANK
功能:这几个函数主要用于对窗口内数据排名,这几个函数不支持chuangkou
NTILE: 切片函数,用于将数据按照顺序切片,如果切片不均匀,默认增加第一个切片的分布
select uname,create_time,pv,
NTILE(2) over(partition by uname order by create_time desc) as ntile_1,--将按照uname分组的数据分成2片
NTILE(2) over(order by create_time desc) as ntile_all --将所有数据分成两片
from window_temp
select uname,create_time,pv,
row_number() over(partition by uname order by create_time desc) as rn, --对分组类的数据排序,相同的值顺序递增
rank() over(partition by uname order by create_time desc) as rn2, --对分组类内的数据排序,相同的值排名会相同,在接下来的地方会留下空位
dense_rank() over(partition by uname order by create_time desc) as rn3 --对分组类内的数据排序,相同的值排名会相同,在接下来的地方不会留下空位
from window_temp

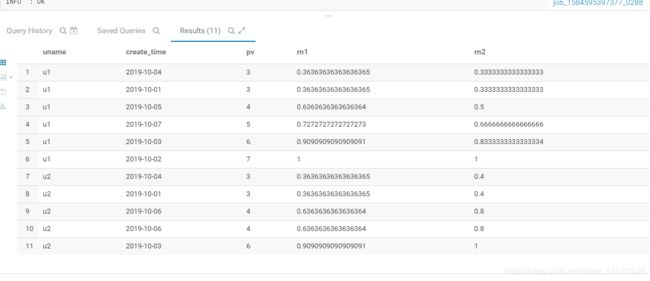
4 序列函数 cume_DIST,Percent_rank
备注:不支持window字句
1:cume_DIST 统计小于等于当前值的行数/分组内的总行数,
应用场景:统计小于等于当前薪水的人数,所占总人数的比例
2:percent_rank 分组内当前行的RANK值-1/分组内总行数-1
应用场景不了解,可能在一些特殊算法的实现中可以用到吧。
select uname,
create_time,
pv,
cume_dist() over(order by pv ) as rn1, -- 输出窗口内,小于等于次数的条数与总条数占比
cume_dist() over(partition by uname order by pv) as rn2 --再rn1的基础上加了partition
from window_temp
5 # GROUPING SETS,GROUPING__ID,CUBE,ROLLUP
这几个函数通常用于OLAP种,不能累加,而且需要根据不同维度上钻与下钻的指标统计,比如:分、小时、天、月的UV数
详细见:https://cwiki.apache.org/confluence/display/Hive/Enhanced+Aggregation%2C+Cube%2C+Grouping+and+Rollup