Hive分析搜索引擎的数据
最近学习Hive的基本使用,下面就记录一下我学习Hive的一些基本语句
数据格式:
(数据可以点击:用户查询日志(SogouQ)下载搜狗实验室的数据,可以根据自己的需要选择数据规模)
00:00:00 2982199073774412 [360安全卫士] 8 3 download.it.com.cn/softweb/software/firewall/antivirus/20067/17938.html
00:00:00 07594220010824798 [哄抢救灾物资] 1 1 news.21cn.com/social/daqian/2008/05/29/4777194_1.shtml
00:00:00 5228056822071097 [75810部队] 14 5 www.greatoo.com/greatoo_cn/list.asp?link_id=276&title=%BE%DE%C2%D6%D0%C2%CE%C5
字段含义为:
搜索时间 用户ID 搜索关键字 点击次序 返回次序 网页链接
在Hive中操作数据:
1.启动hive
2.创建一个hive数据库

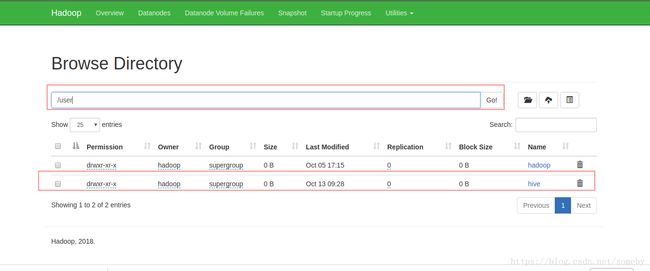
3.创建完成后查看

在HDFS上已经有一个hive的目录了
4.先将数据导入到HDFS上
hdfs dfs -mkdir -p /sougou/input
![]()
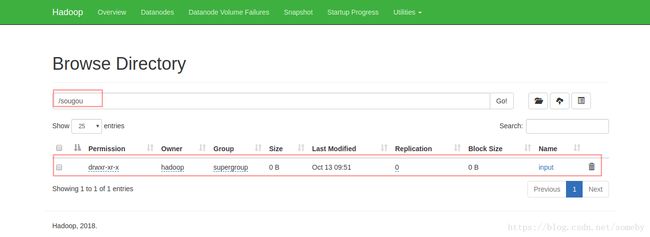
5.把数据上传到HDFS上
hdfs dfs -put ~/SogouQ*.txt /sougou/input
![]()
6.创建一张表,表的字段要和你要导入的数据的字段保持一致,否则数据就会乱掉
create table SogouQ3(ID string,websession string,word string,s_seq int,c_seq int,website string) row format delimited fields terminated by '\t' lines terminated by '\n';
注意:一行中数据字段之间是以"\t"分开,行之间是以"\n"分开,在创建表的时候需要说明;
7.从HDFS上导入数据
LOAD DATA INPATH '/sougou/input/SogouQ3.txt' INTO TABLE sogouq3;
在web上已经可以看到相关数据了
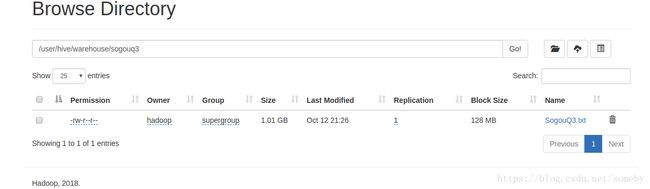
9.对hive上的数据进行操作
select count(*) from sogouq3; //查看有多少条记录
select count(*) from sogouq3 where website like '%baidu%'; //查看字段中有baidu的有多少条记录
select count(*) from sogouq3 where like '%baidu%' and s_seq = 1 and c_seq = 1;
10.创建一张外部表
create external table SogouQ1(ID string,websession string,word string,s_seq int,c_seq int,website string) row format delimited fields terminated by '\t' lines terminated by '\n' stored as textfile location '/sougou/input/SogouQ1external';
需要说明元数据的引用位置,我这里指定为'/sougou/input/SogouQ1external
11.对外部表操作和内部表操作是一样的
select count(*) from sogouq1 where s_seq=1 and c_seq=1;
select word,count(word) as countword from sogouq1 group by word order by countword desc limit 5;
说明:
外部表就是关联的时候只是将元数据关联到表中,删除表不会删除元数据;
内部表是将元数据转移到表中,删除表时元数据也会被删除掉;