一、简介
1. 定义
Redis是开源的高性能非关系型数据库,它可以是数据库、缓存和消息的中间件。它使用ANSI C语言编写、遵守BSD协议、支持网络、可基于内存亦可持久的日志型、Key-Value数据库,并提供多种语言的API。
2. 特点
1). 内存数据库,速度快,也支持数据持久化,可以将内存中的数据保存在磁盘中,重启的时候可以加载来再次进行使用。
2). Redis不仅仅支持简单的Key-Value类型的数据,同时还提供list, set, zset, hash等数据结构的存储。
3). Redis支持数据备份,即master-slave模式的数据备份。
4). 支持事务。
3. 优势
1). 性能极高,Redis读的速度是11000次/s, 写的速度是81000次/s。
2). 丰富的数据类型,Redis支持String, list, set, zset, hash共五种数据类型的操作。
3). 原子,Redis的所有操作都是原子的,同时还支持将几个操作合并为一个原子操作。(事务)
4). 丰富的特性,Redis还支持publish/subscribe,通知,key过期等特性。
二、使用
1. Redis安装目录介绍
Redis安装好后(Windows版),其安装目录下,会有以下几个文件:
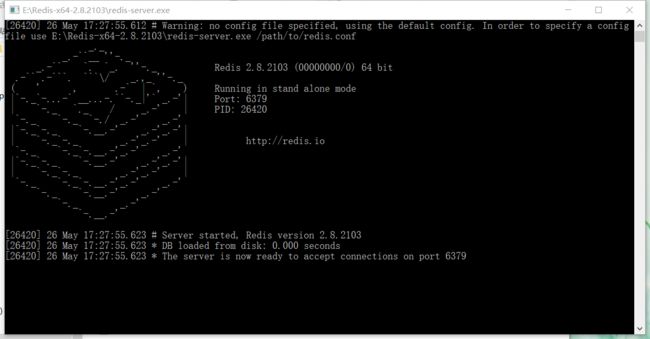
1). redis-server.exe:服务程序 , 也是Reids服务端程序,要先双击这个文件就可以使用Redis了(出现图1的内容就表明启动成功,Redis使用期间此窗口不可关闭)。
2). redis-cli.exe:简单测试,也可以称为Redis客户端程序,双击它后会出现一个窗口,在窗口中可以写命令来操作Redis。
3). redis-check-dump.exe:本地数据库检查 。
4). redis-check-aof.exe:更新日志检查 。
5). redis-benchmark.exe:性能测试,用以模拟同时由N个客户端发送M个 SETs/GETs 查询 (类似于 Apache 的ab 工具)。
6). redis.windows.conf:Redis的配置文件,可以在该文件里设置Redis的端口,超时时间,持久化策略等。
2. 各数据类型的使用
1). String
a. set keyName value: 设置key及value。
b. get keyName: 获取数据。
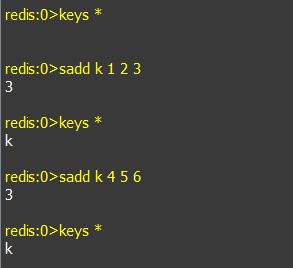
c. keys *: 查看当前数据库有多少key,当然也适用于其它数据类型。

d. del keyName: 删除key, 也可以删除多个key。
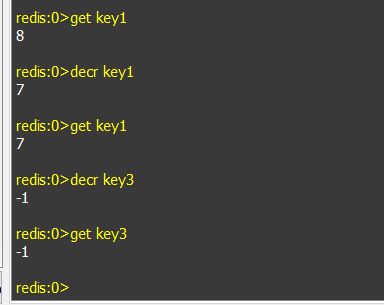
e. incr, decr:递增和递减数值,前提是key的值可转化为数值,不然会报错。如果key不存在,会将key的值从0开始计算。
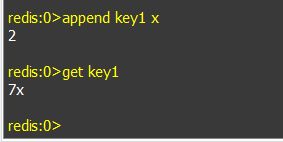
f. append keyName: 在值的尾部添加值。
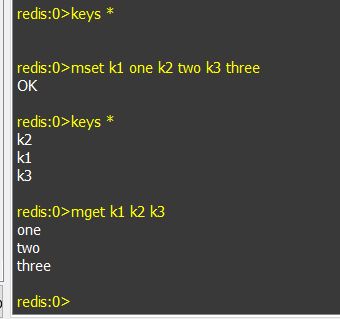
g. mset, mget: 同时设置,获取多个键的值。
2). list
在Redis中,List类型是按照插入顺序排序的字符串链表。和数据结构中的普通链表一样,我们可以在其头部(left)和尾部(right)添加新的元素。在插入时,如果该键并不存在,Redis将为该键创建一个新的链表。与此相反,如果链表中所有的元素均被移除,那么该键也将会被从数据库中删除。List中可以包含的最大元素数量是4294967295。从元素插入和删除的效率视角来看,如果我们是在链表的两头插入或删除元素,这将会是非常高效的操作,即使链表中已经存储了百万条记录,该操作也可以在常量时间内完成。然而需要说明的是,如果元素插入或删除操作是作用于链表中间,那将会是非常低效的。相信对于有良好数据结构基础的开发者而言,这一点并不难理解。
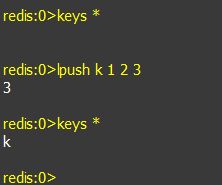
a. lpush keyName value1 value2 value3 ...:往key名为keyName的链表中插入值value1, value2, value3...。从左向右插入,请注意存值的顺序;如果没有链表,则会创建。
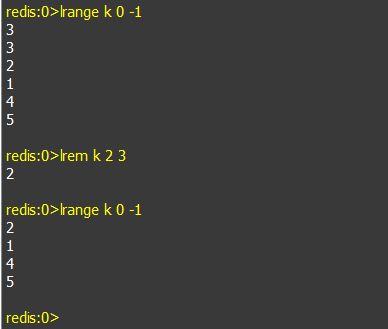
b. lrange keyName startIndex endIndex:取名为keyName链表的数据,startIndex和endIndex为数据在链表中的位置区间,以0开始,如果endIndex中写-1, 表示取startIndex到最后的数据。

c. rpush keyName value1 value2 value3 ...: 往key名为keyName的链表中插入值value1, value2, value3...。从右向左插入,请注意存值的顺序;如果没有链表,则会创建。
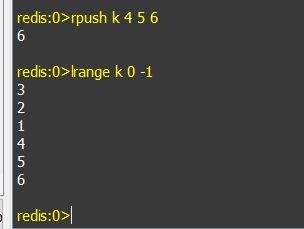
d. lpop keyName:在key名为keyName的链表中从左边取出一个数据,如果链表不存在,则会输出NULL。
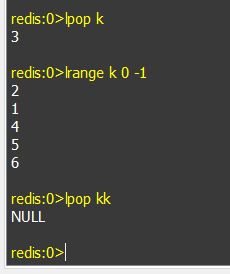
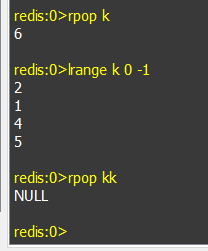
e. rpop keyName: 在key名为keyName的链表中从右边取出一个数据,如果链表不存在,则会输出NULL。
f. rpoplpush key1 key2: 在key名为key1的链表右端弹出一个值,往key名为key2的链表左边插入。如果key1不存在会输出NULL,如果key2不存在会创建。

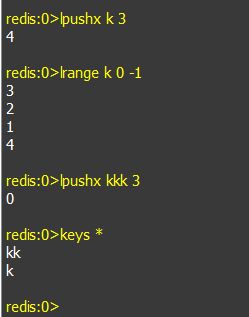
g. lpushx keyName value: 在key名为keyName的链表左边插入一个数据,如果该链不存在,不会做任何操作。rpushx命令与lpushx命令相似,请自行学习。
h. llen keyName: 获取key名为keyName的链表的长度,如果该链表不存在,返回0.
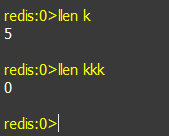
i. lrem keyName count value: 在key名为keyName的链表中,删除前count个值等于value的元素。如果count大于0,从头向尾遍历并删除,如果count小于0,则从尾向头遍历并删除。如果count等于0,则删除链表中所有等于value的元素。如果指定的Key不存在,则直接返回0。
3). set
在Redis中,我们可以将Set类型看作为没有排序的字符集合,和List类型一样,我们也可以在该类型的数据值上执行添加、删除或判断某一元素是否存在等操作。需要说明的是,这些操作的时间复杂度为O(1),即常量时间内完成次操作。Set可包含的最大元素数量是4294967295。和List类型不同的是,Set集合中不允许出现重复的元素,这一点和C++标准库中的set容器是完全相同的。换句话说,如果多次添加相同元素,Set中将仅保留该元素的一份拷贝。和List类型相比,Set类型在功能上还存在着一个非常重要的特性,即在服务器端完成多个Sets之间的聚合计算操作,如unions(并集)、intersections(交集)和differences(差集)。由于这些操作均在服务端完成,因此效率极高,而且也节省了大量的网络IO开销。
a. sadd keyName value1 value2 value3 ...: 往key名为keyName的集合中插入数据,如果该集合不存在,则会创建。
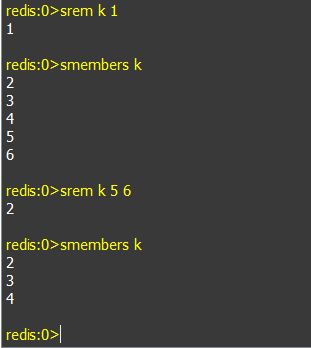
b. smembers keyName: 取名为keyName的集合中所有元素值。

c. srem keyName value1 value2 ...: 删除名为keyName的集合中值为value1, value2...的元素。
d. sismember keyName value: 判断在key名为keyName的集合中,value这个值是否存在。1表示存在,0表示不存在。(无论集合中有多少元素都可以极速的返回结果)

e. sdiff key1 key2: 返回集合key1与key2的差集,即属于key1并且不属于key2的元素构成的集合。(与key的顺序有关)
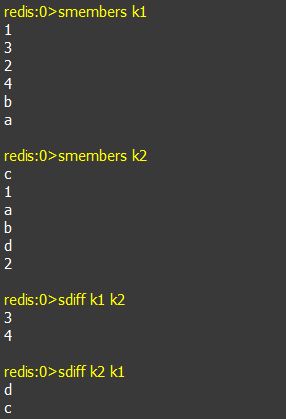
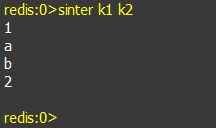
f. sinter key1 key2: 返回集合key1与key2的交集,即同时在key1和key2中存在的元素。
g. sunion key1 key2: 返回集合key1与key2的并集,即属于key1或者属于key2的元素构成的集合。

h. scard keyName: 返回集合keyName的元素数量。

i. srandmember keyName: 随机返回集合keyName中一个元素。

j. spop keyName: 随机删除集合keyName中一个元素。

4). hash
5). zset
2. 其它命令
1). select
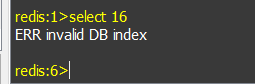
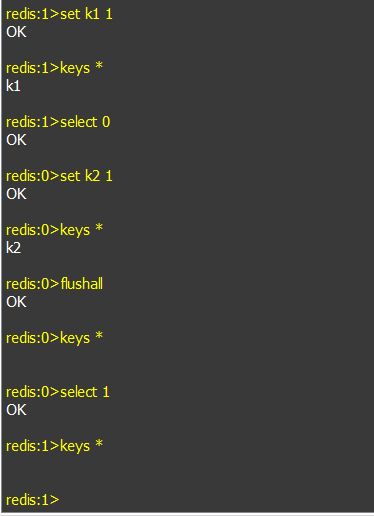
一个 Redis实例可以包括多个数据库,客户端可以指定连接某个redis实例的哪个数据库,就好比一个mysql中创建多个数据库,客户端连接时指定连接哪个数据库。 一个redis实例最多可提供16个数据库,下标从0到15,客户端默认连接第0号数据库,也可以通过select选择连接哪个数据库,如下连接1号库:

如果选择不存在的数据库会报错:
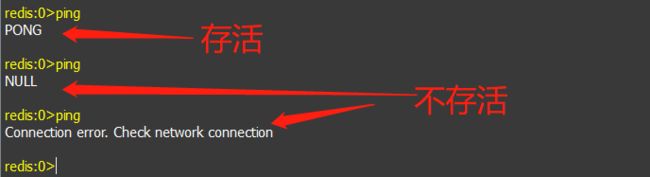
2). ping
测试连接是否存活。
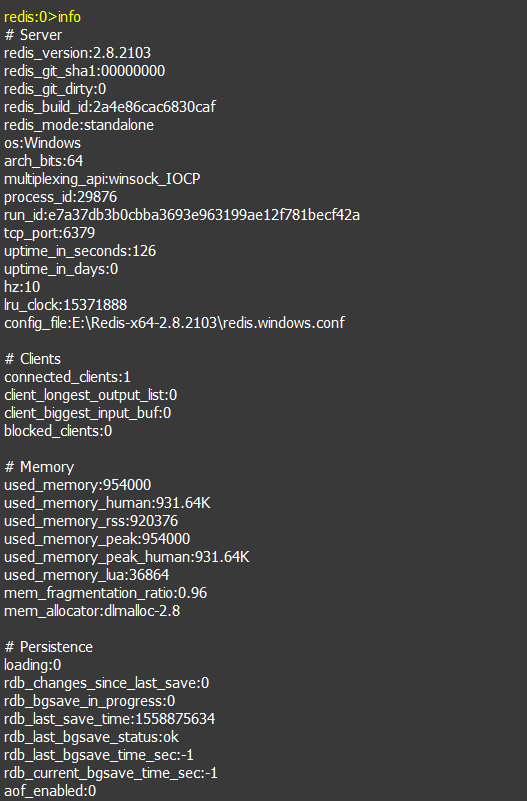
3). info
获取服务器的信息
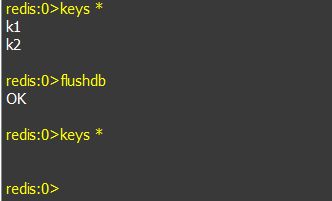
4). flushdb
删除当前数据库下所有key。
5). flushall
删除所有数据库中所有的key
3. Redis事务
1). 事务特征
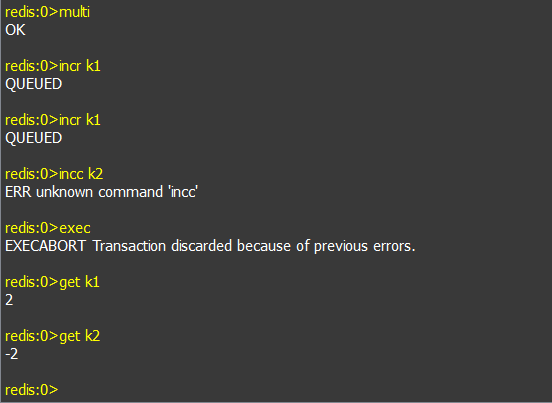
a、在事务中的所有命令都将会被串行化的顺序执行,事务执行期间,Redis不会再为其它客户端的请求提供任务服务。
b、和关系型数据库中的事务相比,在Redis事务中如果有一条命令执行失败,其后的命令仍然会被继续执行。(持有疑问)
c、 我们可以通过MULTI命令开启一个事务,有关系型数据库开发经验的人可以将其理解为"BEGIN
TRANSACTION"语句。在该语句之后执行的命令都将被视为事务之内的操作,最后我们可以通过执行EXEC/DISCARD命令来提交/回滚该事务内的所有操作。这两个Redis命令可被视为等同于关系型数据库中的COMMIT/ROLLBACK语句。
d、 在事务开启之前,如果客户端与服务器之间出现通讯故障并导致网络断开,其后所有待执行的语句都将不会被服务器执行。然而如果网络中断事件是发生在客户端执行EXEC命令之后,那么该事务中的所有命令都会被服务器执行。
e、 当使用Append-Only模式时,Redis会通过调用系统函数write将该事务内的所有写操作在本次调用中全部写入磁盘。然而如果在写入的过程中出现系统崩溃,如电源故障导致的宕机,那么此时也许只有部分数据被写入到磁盘,而另外一部分数据却已经丢失。Redis服务器会在重新启动时执行一系列必要的一致性检测,一旦发现类似问题,就会立即退出并给出相应的错误提示。此时,我们就要充分利用Redis工具包中提供的redis-check-aof工具,该工具可以帮助我们定位到数据不一致的错误,并将已经写入的部分数据进行回滚。修复之后我们就可以再次重新启动Redis服务器了。
2). 事务的使用
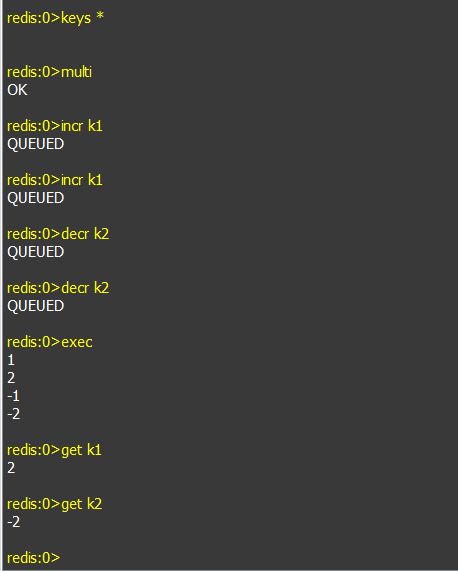
a. multi:开启事务用于标记事务的开始,其后执行的命令都将被存入命令队列,直到执行EXEC时,这些命令才会被原子的执行,类似与关系型数据库中的:begin transaction
b. exec:提交事务,类似与关系型数据库中的:commit
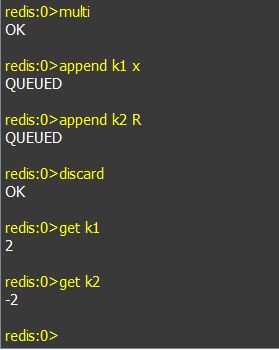
c. discard:事务回滚,类似与关系型数据库中的:rollback