索引扫描、查找、书签查询、覆盖查询示例介绍
以下文章选自Inside Microsoft SQL Server 2005-Query Tuning and Optimization
真正理解查询计划和发现与计划有关的问题,需要对构成这些计划的查询运算符有深入的了解.总而言之,有许多运算符值得探讨.
扫描与查找
扫描与查找操作均是SQL Server从表或索引中读取数据采用的迭代器,这些也是SQL Server支持的最基本的运算.几乎在每一个查询计划中都可以找到,因此理解它们的不同是很重要的,扫描是在整张表上进行处理,而索引是在整个页级上进行处理,而查找则返回特定谓词上一个或多个范围内的数据行.
下面让我们看一个扫描的例子(这里使用Northwind数据库)
SELECT [OrderId] FROM [Orders] WHERE [RequiredDate] = '1998-03-26'
在Orders表中,并不存在对RequiredDate列的索引,因此,SQL Server必须读取Orders表的每一行来估计每一行的RequiredDate谓词,如果满足该谓词条件(即找到包含’1998-03-26’的记录),则返回该行数据.
为了最大化提升性能,SQL Server尽可能地使用扫描迭代器来估计该谓词,然而,如果该谓词过于复杂或开销过大,SQL Server或许使用别的筛选迭代器来估计.以下是WHERE关键字中的文本计划的过程:
|--Clustered Index Scan(OBJECT:([Orders].[PK_Orders]),
WHERE:([Orders].[RequiredDate]='1998-03-26'))
下图描述了该操作的流程图:

由于扫描表的每一行数据,不论满足与否,因此,其查询开销对表中的总记录数是均衡的,当表中的数据很少或满足谓词的行比较多时,采用扫描操作有效,如果表中数据量比较大或满足谓词的行较少时,使用扫描将读取更多的页面或执行更多的I/O操作来获取数据,这显而不是最有效的方法.
下面让我们看一个关于索引查找的例子,下面的例子在OrderdDate列上创建了索引:
SELECT [OrderId] FROM [Orders] WHERE [OrderDate] = '1998-02-26'
这次SQL Server能够使用索引查找来直接找到满足谓词的那些记录行,这里称该谓词为"查找"谓词.大多数情况下,SQL Server并不显式地估计"查找"谓词,而索引确保了"查找"操作仅返回满足的数据行,以下是"查找"谓词的文本计划:
|--Index Seek(OBJECT:([Orders].[OrderDate]),
SEEK:([Orders].[OrderDate]=CONVERT_IMPLICIT(datetime,[@1],0)) ORDERED FORWARD)
注意:SQL Server自动使用@1参数替换查询文本中的参数
由此看来,查找仅扫描满足该谓词的数据页,其查询开销显然要比表中总记录数的开销低,因此,对于高选择度的查询谓词操作,查找通常是最有效的策略.也就是说,对于估计大表中的数据时,使用查找谓词是比较有效率的.
SQL Server将扫描与查找进行区分,如同将在堆(无聚集索引的对象)上扫描,聚集索引上的扫描,非聚集索引上的扫描进行分区.下表说明了这些出现在的查询计划中的扫描与查找运算.
|
|
扫描 |
查找 |
| 堆 |
表扫描 |
|
| 聚集索引 |
聚集索引找描 |
聚集索引查找 |
| 非聚集索引 |
索引扫描 |
索引查找 |
可查找的谓词与覆盖列
SQL Server在执行索引查找之前,它需要确定索引键是否满足查询中的谓词,我们称该谓词为"可查找的谓词",SQL Server必须确定该索引是否包含或"覆盖"查询中引用的列集合.下面描述了如何确定哪个谓词是可查找的,哪个谓词不是可查找的,哪些列需要索引覆盖.
单列索引
在单列索引上判断谓词是否是可查找的是很容易的,SQL Server使用单列索引来响应多数简单的比较(包括相等和不等(大于,小于等))或者更复杂的表达式,如在列上运算的函数和LIKE %谓词,这些运算符将阻止SQL Server使用索引查找.
例如,假设我们在Col1列上创建了单列索引,可以在以下谓词上进行索引查找:
Ø [Col1] = 3.14
Ø [Col1] > 100
Ø [Col1] BETWEEN 0 AND 99
Ø [Col1] LIKE 'abc%'
Ø [Col1] IN (2, 3, 5, 7)
然页,在以下谓词上将不能使用索引查找:
Ø ABS([Col1]) = 1
Ø [Col1] + 1 = 9
Ø [Col1] LIKE '%abc'
下面我通过一些例子来介绍单列索引:
首先创建一些架构对象:
create table person
(id int, last_name varchar(30), first_name varchar(30))
create unique clustered index person_id
on person (id)
create index person_name
on person (last_name, first_name)
以下是三个查询及其各自的文本查询计划,第一个查询在person_name索引上进行查找,第二个查询首先在第一个键列上进行索引查找,然后使用residual谓词来估计first_name,第三个查询不能使用索引查找,而是使用了索引扫描来处理residual谓词.
select id from person where last_name = 'Doe' and first_name = 'John'
|--Index Seek(OBJECT:([person].[person_name]), SEEK:([person].[last_name]='Doe' AND [person].[first_name]='John'))
select id from person where last_name > 'Doe' and first_name = 'John'
|--Index Seek(OBJECT:([person].[person_name]), SEEK:([person].[last_name] > 'Doe'), WHERE:([person].[first_name]='John'))
select id from person where last_name like '%oe' and first_name = 'John'
|--Index Scan(OBJECT:([person].[person_name]), WHERE:([person].[first_name]='John' AND [person].[last_name] like '%oe'))
上面三条查询的图形查询计划:

复合索引
复合索引或多列索引,与单列索引相比,略显得复杂,对于复合索引,比较关心的是键列的次序,它决定了索引的排序,同时对SQL Server使用该索引来进行估计的查找谓词集合有一定的影响.
用一种简单的方法来说明这一问题就是使用电话本,电话本可能包括last_name,first_name列的索引.如果电话本的内容是按照last_name进行排序,要查找某个人的电话,只需知道last_name就可以轻松地找到该人,然而,如果我们仅知道该人的first_name,要找出符合该名的电话清单就是那么容易了,这就需要在first_name上进行排序的另一个电话本.
例如,在Col1和Col2列上有一个两列的索引,可以使用该索引来查找单列索引上的任何一个谓词,可以在以下谓词上进行查找:
Ø [Col1] = 3.14 AND [Col2] = 'pi'
Ø [Col1] = 'xyzzy' AND [Col2] <= 0
对于使用索引来满足col1列上的谓词,并非是col2列,在这些情况中,需要使用剩余谓词来查找:
Ø [Col1] > 100 AND [Col2] > 100
Ø [Col1] LIKE 'abc%' AND [Col2] = 2
不能使用索引来查找不在col1列上的谓词查找,则必须使用不同的索引来查找(也就是说以col2为第一个键列)或使用谓词扫描.
Ø [Col2] = 0
Ø [Col1] + 1 = 9 AND [Col2] BETWEEN 1 AND 9
Ø [Col1] LIKE '%abc' AND [Col2] IN (1, 3, 5)
标识索引键
在多数情况下,索引键通常是在CREATE INDEX语句中指定的列集合,当在含有聚集索引的表上创建非唯一的非聚集索引时,如果该索引并未显式说明非聚集索引键的部分时,需要将聚集索引键添加到非聚集索引键上.正如可以显式指定他们来查找这些隐式的键列一样.
覆盖列
对于堆或聚集索引的一张表,也叫"基表",包含(覆盖)了表的所有列,换句话说,非聚集索引只包含(覆盖)了表中的一小部分列,通过在非聚集索引来限制列的集合,SQL Server可以在每一页储存更多的行,这显然节约了空间,提高查找与扫描的效率,降低了I/O的操作数和页面数.然而,对于索引的扫描或查找来说,它只能返回该索引覆盖的那些列的记录行.
当创建覆盖列时,可以在非聚集索引上指定这些键列.如果基表是含有聚集索引的,位于该表上的每一个非聚集索引将覆盖聚集索引键,而不关心它们是否是非聚集索引键列的成员.在SQL Server 2005中,我们可以在非聚集索引上使用CREATE INDEX ...INCLUDE子语来添加额外的键列,注意:和索引键不同,INCLUDE中的列的次序并不重要.
下面我来通过一个示例说明,首先我们创建以下架构和对象:
CREATE TABLE T_heap (a int, b int, c int, d int, e int, f int)
CREATE INDEX T_heap_a ON T_heap (a)
CREATE INDEX T_heap_bc ON T_heap (b, c)
CREATE INDEX T_heap_d ON T_heap (d) INCLUDE (e)
CREATE UNIQUE INDEX T_heap_f ON T_heap (f)
CREATE TABLE T_clu (a int, b int, c int, d int, e int, f int)
CREATE UNIQUE CLUSTERED INDEX T_clu_a ON T_clu (a)
CREATE INDEX T_clu_b ON T_clu (b)
CREATE INDEX T_clu_ac ON T_clu (a, c)
CREATE INDEX T_clu_d ON T_clu (d) INCLUDE (e)
CREATE UNIQUE INDEX T_clu_f ON T_clu (f)
下面列举上面每一个索引的键列和覆盖列.
| 索引名称 |
键列 |
覆盖列 |
| T_heap_a |
a |
a |
| T_heap_bc |
b,c |
b,c |
| T_heap_d |
d |
d,e |
| T_heap_f |
f |
f |
| T_clu_a |
a |
a,b,c,d,e,f |
| T_clu_b |
b,a |
a,b |
| T_clu_ac |
a,c |
a,c |
| T_clu_d |
d,a |
a,d,e |
| T_clu_f |
f |
a,f |
注意:对于T_clu表中的每一个非聚集索引键列均包含一个聚集索引键(T_clu_f除外,它是一个唯一索引).T_clu_ac显式包含了索引的第一个键,而其他的索引并无显式包含a列.
对于创建的列在实际的索引查找和书签查询是有何不同呢?
下面我们来看一个例子:
SELECT e from t_clu where b = 2
初看,这个查询看起来符合索引查找的候选,然而,该索引并不覆盖列e,因而索引的扫描或查找并不能返回e列的值,其解决方法是很简单的,对于从非聚集索引中获取的每一行,我们可以通过聚集索引来查询e列的值,这种方法称为"书签查询",书签查询是一个指向堆或聚集索引行的一个指针.在非聚集索引中存储每一行的书签,这样每次在进行非聚集索引查询时,总是由非聚集索引转向基表中相对应的行.
书签查询
在上面的例子中,我们了解了SQL Server如何使用索引查找来有效地获取满足谓词上的数据,然而,我们也知道非聚集索引并不覆盖表的所有列.试想一下,若我们有这样一个在非聚集索引键上的谓词查询:select查询的列并未被索引覆盖,当SQL Server在非聚集索引上查找时,将会丢失一些需要的列,与之相反,如果在聚集索引或唯上执行扫描时,将获取所有列,由于要扫描表的每一行,其操作显然不是很有效.以下的查询就是如此:
SELECT [OrderId], [CustomerId] FROM [Orders] WHERE [OrderDate] = '1998-02-26'
上面的查询与先前我们进行索引查找的用到的查询一样,唯一不同的是,这里我们选择了两列:OrderID和CustomerID.非聚集索引OrderDate列仅覆盖OrderID列.
SQL Server具有处理这一问题的方法,对于从非聚集索引中获取的每一行,它可能查询包含在聚集索引中的剩余列(这里是CustomerID),我们称该操作为"书签查询".书签查询是一个指向堆或聚集索引行的指针.SQL Server在非聚集索引中存储每一行的书签,这样一来,可以从非聚集索引直接转向基表中相对应的记录行.
SQL Server 2000使用指定的迭代器来实现书签查询,通过文本计划可以看出索引查找与书签查询迭代器:
|--Bookmark Lookup(BOOKMARK:([Bmk1000]), OBJECT:([Orders]))
|--Index Seek(OBJECT:([Orders].[OrderDate]),
SEEK:([Orders].[OrderDate]=Convert([@1])) ORDERED FORWARD)
下图为SQL Server 2000中的图形查询计划:

在SQL Server 2005中将使用嵌套循环联接和聚集索引查找来实现,仅当基表含有聚集索引或RID查询(基表是堆),SQL Server 2005中的查询计划与SQL Server 2000中的计划有些不同,但逻辑上是相同的.聚集索引查找就是通过LOOKUP关键来
实现的一种书签查询或通过属性Lookup=”1”.以下是SQL Server 2005的图形查询计划和文本查询计划:
|--Nested Loops(Inner Join, OUTER REFERENCES:([Orders].[OrderID]))
|--Index Seek(OBJECT:([Orders].[OrderDate]),
SEEK:([Orders].[OrderDate]='1998-02-26') ORDERED FORWARD)
|--Clustered Index Seek(OBJECT:([Orders].[PK_Orders]),
SEEK:([Orders].[OrderID]=[Orders].[OrderID]) LOOKUP ORDERED FORWARD)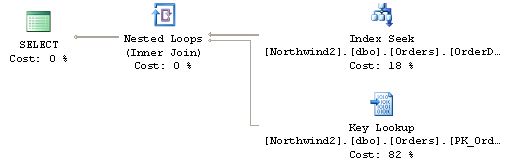
书签查询可以用在堆中,也可以用在聚集索引中,正如上所描述的,在SQL Server 2000中,堆上的书签查询与聚集索引
上的书签查询是相同的,而在SQL Server 2005中,堆上的书签查询仍旧使用一个嵌套循环联接运算,代替了聚集索引查找
,SQL Server使用一个叫做RID查询运算符.RID查询运算符包括在堆上进行书签查询的查找谓词,但是堆并不是一个索
引,RID查询也不是一个索引查找.
索引示例介绍
查询优化器在从表中查询数据时,需要选择一个合适的访问模式,在决定使用哪一种索引,使用扫描还是查找,使用书签
查询时,查询优化器要考虑许多因素,这些因素包括:
l 索引执行时,查找或扫描所需的I/O数
l 评估查询中的索引键是否是最佳
l 谓词的选择性(也就是说,相对于表中总记录数满足谓词的百分比)
l 索引是否覆盖所有列?
下面通过一个例子来介绍:
create table T (a int, b int, c int, d int, x char(200))
create unique clustered index Ta on T(a)
create index Tb on T(b)
create index Tcd on T(c, d)
create index Tdc on T(d, c)
插入一些数据:
set nocount on
declare @i int
set @i = 0
while @i < 100000
begin
insert T values (@i, @i, @i, @i, @i)
set @i = @i + 1
end
无WHERE条件
SELECT a,b FROM T,
该查询不包含WHERE条件语句,而使用扫描,可是这里有两种索引可用:聚集索引(Ta)和非聚集索引(Tb),这两个索
引均覆盖a和b两列,另外,聚集索引也覆盖c和x列.由于x列是字符型,长度为200个字符,聚集索引的每一行
总宽度超过了200个字节,对于每一个8KB的页面,存储的行数也不超过40行.而索引需要2500个页来
存储所有10万行数据,与之相反的是,非聚集索引中每一行的总宽仅有8个字节,加一些头部信息,每一页可以
存储上百行数据,索引则需要不到250页来存储所有的10万行数据.通过扫描非聚集索引,当执行查询时则需
要较少的I/O操作.因而使用的最佳计划是:
|--Index Scan(OBJECT:([T].[Tb]))
我们也可以使用sys.dm_db_index_physical_stats视图来比较聚集索引与非聚集索引两者所使用的页数
select index_id, page_count
from sys.dm_db_index_physical_stats
(DB_ID('northwind'), OBJECT_ID('T'), NULL, NULL, NULL)
执行上述查询后,结果如下:
index_id page_count
----------- --------------------
1 2858
2 174
3 223
4 223
从输出结果可以看出,非聚集索引存储行所使用的页数明显小于聚集索引使用的页数.
当然我们也可以使用stats I/O和索引hints来比较聚集索引与非聚集索引的I/O数.
set statistics io on
select a, b from T with (index(Ta))
表'T'。扫描计数1,逻辑读取2872 次,物理读取0 次,预读0 次,lob 逻辑读取0 次,lob 物理读取0 次,lob 预读0 次。
select a, b from T with (index(Tb))
表'T'。扫描计数1,逻辑读取176 次,物理读取0 次,预读0 次,lob 逻辑读取0 次,lob 物理读取0 次,lob 预读0 次。
从stats I/O数可以看出,非聚集索引在获取数据时,读取较少的数据页.
索引的选择性
select a from T
where c > 150 and c < 160 and d > 100 and d < 200
此查询有两个不同的谓词用于索引查找,可以使用位于c列上的非聚集索引Tcd,也可以使用位于d列上的非聚集索引Tdc.
查询优化器通过查看两个谓词的选择性来确定使用哪一个索引,在c列上的谓词选择的行仅有9行,而在d列上则有99行,显
然使用索引Tcd来评估位于d列上的residual谓词比使用Tdc索引的I/O开销要小得多.
以下是该查询的计划:
|--Index Seek(OBJECT:([T].[Tcd]), SEEK:([T].[c] > (150) AND [T].[c] < (160)),
WHERE:([T].[d]>(100) AND [T].[d]<(200)) ORDERED FORWARD)
索引查找与索引扫描示例
select a from T where a between 1001 and 9000
select a from T where a between 101 and 90000
其执I/O信息如下:
表'T'。扫描计数1,逻辑读取234 次,物理读取0 次,预读0 次,lob 逻辑读取0 次,lob 物理读取0 次,lob 预读0 次。
表'T'。扫描计数1,逻辑读取176 次,物理读取0 次,预读0 次,lob 逻辑读取0 次,lob 物理读取0 次,lob 预读0 次。
如您所预料的,对于第一个查询来说,查询优化器在a列上选择使用聚集索引来获取数据,以下是其的查询计划:
|--Clustered Index Seek(OBJECT:([T].[Ta]),
SEEK:([T].[a] >= CONVERT_IMPLICIT(int,[@1],0) AND [T].[a] <= CONVERT_IMPLICIT(int,[@2],0)) ORDERED FORWARD)
注意:该计划中的两个参数是由自动参数化功能所生成的,当执行该计划时,@1参数为1001,@2参数为9000.
对于第二个查询来说,查询优化器却选择了非聚集索引来扫描数据,以下其查询计划:
|--Index Scan(OBJECT:([T].[Tb]), WHERE:([T].[a]>=(101) AND [T].[a]<=(90000)))
为什么是这样呢?注意第一个查询选择的记录数有8千行(相对于10万行数据而言),对于聚集索引来说,
选择度为表的8%,约230个数据页,而第二查询选择的记录数有89000行,选择度为表的约90%,
若使用聚集索引来读取89000行数据时,则需要读2500个数据页.通过比较,非聚集索引仅需要读取174个页面,
查询优化器选择此计划,大大减少了I/O操作.
带书签查询的查询与扫描示例
select x from T where b between 101 and 200
select x from T where b between 1001 and 2000
对于上述的两个查询而言,可以通过聚集索引直接扫描然后在列b上应用谓词,或者使用非聚集索引Tb在列b上执行索引
查找,然后在聚集索引上执行书签查询来读取满足x列值的行.(注意:书签查询采用的I/O开销比较大的方式是随机读.)
对于查找的选择度高的书签查询,则是值得的.
以下是第一个包含书签查询的查询计划(仅需要读取100行):
|--Nested Loops(Inner Join, OUTER REFERENCES:([T].[a], [Expr1005]) ...)
|--Index Seek(OBJECT:([T].[Tb]), SEEK:([T].[b] >= (101) AND [T].[b] <= (200)) ...)
|--Clustered Index Seek(OBJECT:([T].[Ta]), SEEK:([T].[a]=[T].[a]) LOOKUP ...)
而第二个查询则读取1000行,对于表而言,仅有1%.查询优化器由此推出,执行1000次的随机读要比
执行2800次的顺序读的开销要大得多,第二个查询的计划如下:
|--Clustered Index Scan(OBJECT:([T].[Ta]), WHERE:([T].[b]>=(1001) AND [T].[b]
<=(2000)))
注:以上是阅读Inside MS SQL Server 2005:Query Tuning and Optimization记录的一些简要笔记,
个别词汇翻译不准,望读者给予指导,共同学习!