Hadoop集群的搭建及Hadoop生态圈
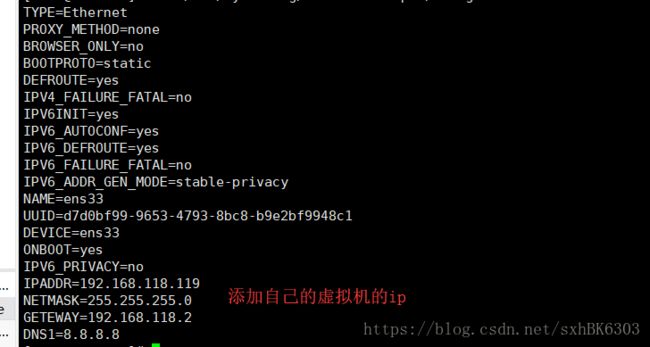
目前是动态IP,所以需要配置IP地址为静态IP
/etc/sysconfig/network-scripts
ll | grep ifcfg-ens33可查看此文件的权限,只能在root下更改
vi ifcfg-ens33:
BOOTPROTO=dhcp改为 BOOTPROTO=static
ONBOOT=yes
添加四行代码:
IPADDR=192.168.220.138
NETMASK=255.255.255.0
GATEWAY=192.168.220.1
DNS1=202.106.0.20
保存后:
遇到的问题:
IP地址的网段:需要从DOS命令中查看VM8的网段和网关
2.修改主机名和主机映射
vi /etc/hostname
将localhost改为虚拟机的名字

vi /etc/hosts
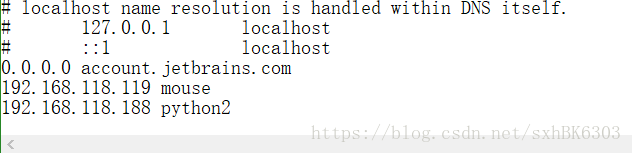
追加:192.168.220.138 python2
保存退出

ssh 192.168.220.138
如果想让Windows系统认识python2
c:/windows/system32/drivers/etc/hosts文件
在此文件中添加:
192.168.220.138 python2
保存
但是没有权限:所以先将文件复制出来再粘贴回去
这时我们需要切换到Hadoop用户下来首先在Hadoop的主体目录下创建一个opt的文件夹 打开xftp来上传文件
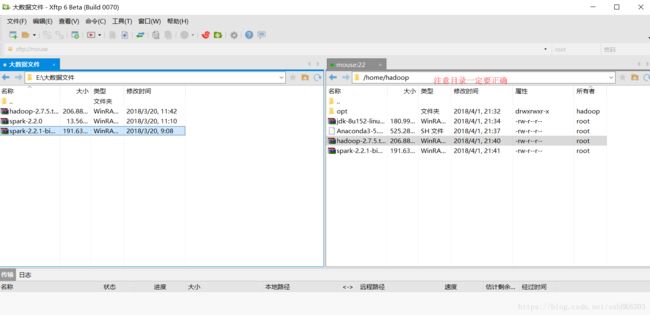
在这里我把需要的安装包一次性上传了,我们首先来解压Java 的jdk压缩包和Hadoop的压缩包到opt文件夹内
解压文件
tar -xzf 文件名 -C 要解压到的文件夹

解压完之后我们可以在opt文件夹下面产生了两个新的文件夹

我们首先来配置java的环境变量,环境变量需要在主目录下的 .bashrc文件中追加需要文件目录,我把环境变量追加.bashrc中

接下来刷新一下环境变量(每次配置完环境变量都要刷新一下才可以起到效果)输入Java看一下是否配置成功
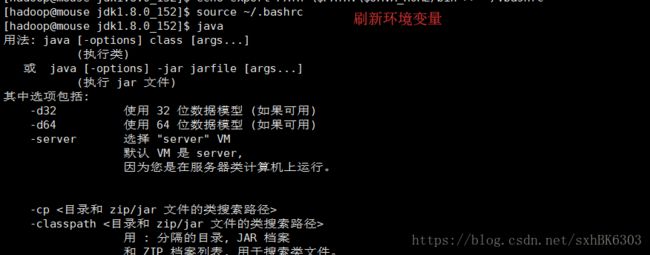
如果没有成功的话就是配置出错了 需要好好检查主目录下的.bashrc文件
接着来配置Hadoop的环境变量我们进入到hadoop-2.7.5文件夹中 ll查看一下里面的内容

有一个bin文件夹还有一个sbin文件夹,
hadoop分客户端和服务端,所以有bin和sbin
所以我们配置环境变量两个都需要来配置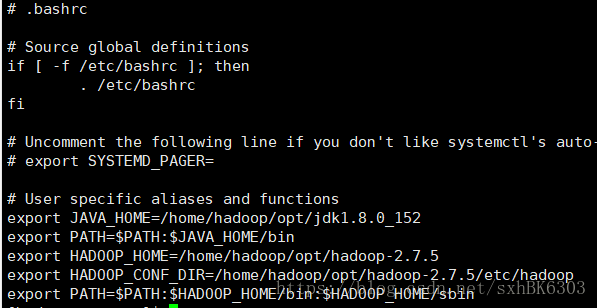
刷新环境 输入hadoop看环境变量是否配置成功

如果没有成功的话或者出现异常情况就是配置出错了 需要好好检查主目录下的.bashrc文件
4.配置hadoop配置文件
伪分布式:一台计算机扮演多个角色:
nameNode secondaryNameNode DataNode
resourceManager nodeManager
配置以下文件:
core-site.xml
hdfs-site.xml
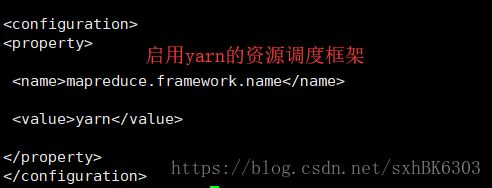
mapred-site.xml
yarn-site.xml
slaves文本文件
-------------------------------------
从官网查询:hadoop.apache.org/docs/
core-site.xml
默认文件系统:hdfs
hdfs-site.xml
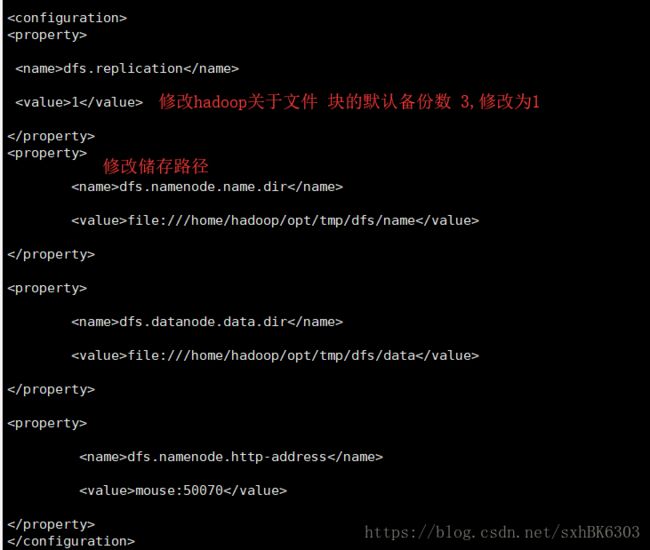
修改mapred-site.xml文件:(修改前复制一下)
cp mapred-site.xml.template mapred-site.xml
vi mapred-site.xml
修改slaves
将localhost改为虚拟机名称


完成后:
关闭防火墙 和 selinux(切换到root用户)
关闭防火墙:
临时关闭:systemctl stop firewalld
永久关闭:systemctl disable firewalld
查看防火墙状态:systemctl status firewalld

临时关闭:setenforce 0
永久关闭:vi /etc/selinux/config
修改文件以上文件中:
SELINUX=disabled
保存关闭
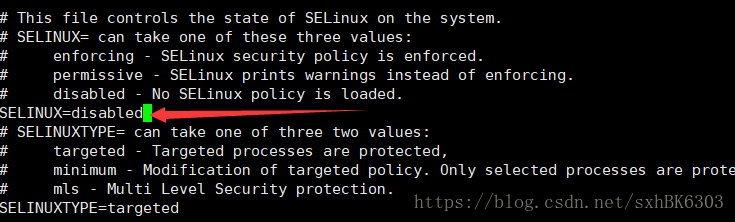
getenforce可以查看值

执行hdfs文件系统格式化:hdfs namenode -format

只要状态为0就成功

ssh-keygen -t rsa
一直敲回车

当前主体目录下多了.ssh文件和目录

ssh-copy-id 你想登录到的计算机名
启动hadoop:start-dfs.sh start-yarn.sh
以上启动了文件系统
输入jps查看如果能看到5个节点就对了
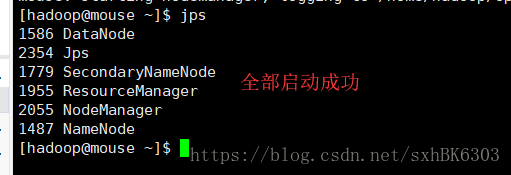
如果没有成功检查上面的步骤有没有错误·
在浏览器中输入:mouse:50070
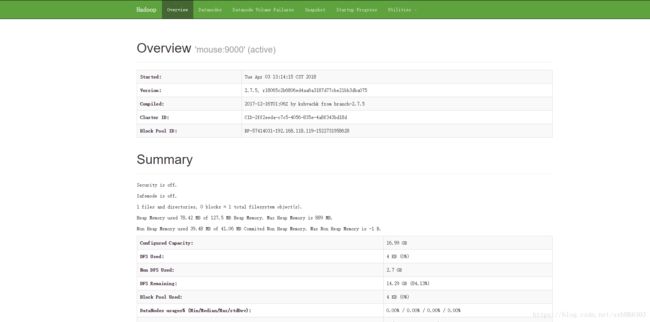
可以看到这个页面表示成功
创建目录
hadoop fs -mkdir -p /user/hadoop
![]()
网盘上就有了此目录

hadoop fs -put data.txt .
![]()

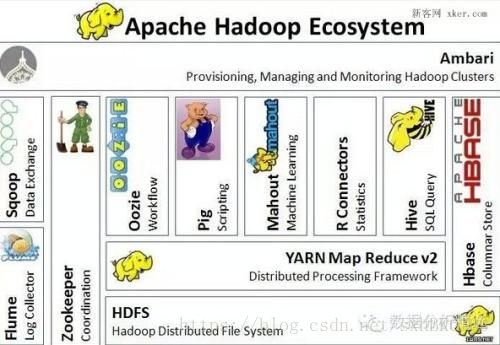
接下来我们了解一下Hadoop的生态圈
一、简介
Hadoop是一个分布式系统基础架构,由Apache基金会开发。用户可以在不了解分布式底层细节的情况下,开发分布式程序。充分利用集群的威力高速运算和存储。简单地说来,Hadoop是一个可以更容易开发和运行处理大规模数据的软件平台。
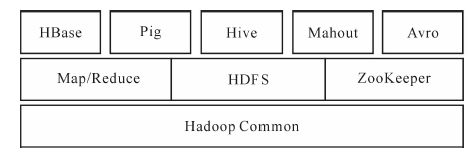
图1 Hadoop主要项目
MapReduce:分布式数据处理模型和执行环境,运行于大型商用机集群。
HDFS:分布式文件系统,运行于大型商用机集群。
Zookeeper:一个分布式、可用性高的协调服务,提供分布式锁之类的基本服务用于构建分布式应用。
HBase:一个分布式、按列存储数据库,使用HDFS作为底层存储,同时支持MapReduce的批量式计算和点查询(随机读取)。
Pig:一种数据流语言和运行环境,用以检索非常大的数据集,运行在MapReduce和HDFS的集群上。
Hive:一个分布式、按列存储的数据仓库,管理HDFS中存储的数据,并提供基于SQL的查询语言(由运行时引起翻译成MapReduce作业)用以查询数据。
Mahout:一个在Hadoop上运行的可扩展的机器学习和数据挖掘类库(例如分类和聚类算法)。
Avro:一种支持高效、跨语言的RPC以及永久存储数据的序列化系统。
Sqoop:在数据库和HDFS之间高效传输数据的工具。
二、核心
Hadoop对应于Google三驾马车:HDFS对应于GFS,即分布式文件系统,MapReduce即并行计算框架,HBase对应于BigTable,即分布式NoSQL列数据库,外加Zookeeper对应于Chubby,即分布式锁设施。

图2 Hadoop核心系统
三、Hadoop生态图谱