在centOS7 下搭建 HADOOP3.0.3 完全分布式集群环境
一、基础环境
在Linux上安装Hadoop之前,需要先安装两个程序:
1.1 安装说明
1. JDK 1.8或更高版本(本文所提到的安装的是jdk1.8);
2. SSH(安全外壳协议),推荐安装OpenSSH。
下面简述一下安装这两个程序的原因:
1. Hadoop是用Java开发的,Hadoop的编译及MapReduce的运行都需要使用JDK。
2. Hadoop需要通过SSH来启动salve列表中各台主机的守护进程,因此SSH也是必须安装的,即使是安装伪分布式版本(因为Hadoop并没有区分集群式和伪分布式)。对于伪分布式,Hadoop会采用与集群相同的处理方式,即依次序启动文件conf/slaves中记载的主机上的进程,只不过伪分布式中salve为localhost(即为自身),所以对于伪分布式Hadoop,SSH一样是必须的。
1.2 下载安装JDK
1.2.1 下载
地址:http://www.oracle.com/technetwork/java/javase/downloads/jdk8-downloads-2133151.html
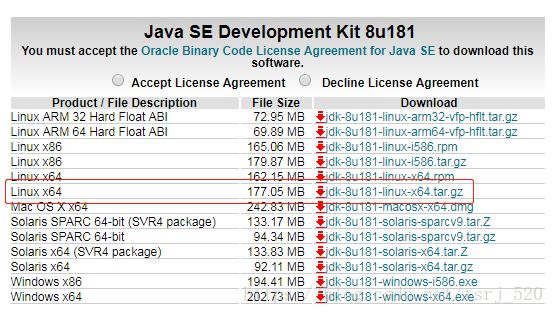
1.2.2 安装配置
1)、使用命令 tar -zxfv jdk-8u181-linux-x64.tar.gz 解压
2)、然后移动 mv jdk1.8.0_181 /usr/local
然后将这些目录通过scp命令拷贝到Slave1和Slave2的相同目录下。
scp -r /usr/local/jdk1.8.0_181 root@slave1:/usr/local/
scp -r /usr/local/jdk1.8.0_181 root@slave2:/usr/local/3)、配置环境变量:vi /etc/profile 在末尾空白处添加
如下配置
#JAVA
JAVA_HOME=/usr/local/jdk1.8.0_181
JRE_HOME=$JAVA_HOME/jre
CLASS_PATH=.:$JAVA_HOME/lib/dt.jar:$JAVA_HOME/lib/tools.jar:$JRE_HOME/lib
PATH=$PATH:$JAVA_HOME/bin:$JRE_HOME/bin
export JAVA_HOME JRE_HOME CLASS_PATH PATH然后立刻生效运行:source /etc/profile
验证是否成功:java,javac,java -version
1.3 查看配置ssh 免密码登录
1.3.1 查看是否安装ssh
查看ssh的安装包 :rpm -qa | grep ssh
查看ssh是否安装成功 :ps -ef | grep ssh
1.3.2 配置SSH免密码登录
进入~/.ssh目录
每台机器执行:ssh-keygen -t rsa,一路回车
生成两个文件,一个私钥,一个公钥,在master1中执行:cp id_rsa.pub authorized_keys
a:本机无密钥登录
修改authorized_keys权限:chmod 644 authorized_keys
此时重启ssh服务:sudo service sshd restart
试一试,连接及退出
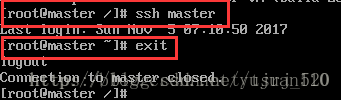
b:master与其他节点无密钥登录
从master中把authorized_keys分发到各个结点上(会提示输入密码,输入密码即可):
scp /root/.ssh/authorized_keys slave1:/root/.ssh
scp /root/.ssh/authorized_keys slave2:/root/.ssh (这里.ssh的位置需要注意下,由于我用的是root用户,所以直接就在/root下,其他可能是/home/用户名/下)
然后在各个节点对authorized_keys执行(一定要执行该步,否则会报错):chmod 644 authorized_keys
试试连接到其他节点
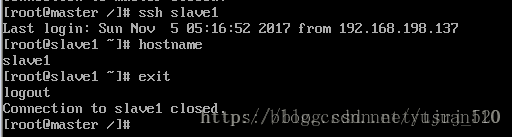
连接成功,而且不需要密码
1.4 Host配置
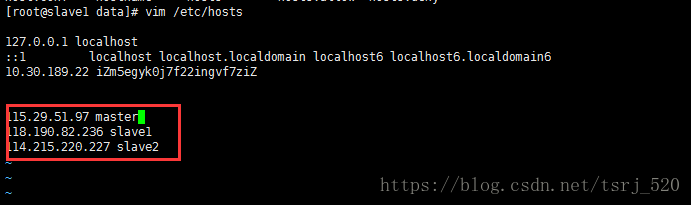
由于我搭建Hadoop集群包含三台机器,所以需要修改调整各台机器的hosts文件配置,进入/etc/hosts,配置主机名和ip的映射,命令如下:
vim /etc/hosts
如果没有足够的权限,可以切换用户为root。
三台机器的内容统一增加以下host配置:
可以通过hostname来修改服务器名称为master、slave1、slave2
hostname master
然后将这些目录通过scp命令拷贝到Slave1和Slave2的相同目录下。
scp -r /etc/hosts root@slave1:/etc/
scp -r /etc/hosts root@slave2:/etc/修改主机名:vi /etc/hostname
在后面追加:
HOSTNAME=master (每台机器的主机名称 如:slave1)二、hadoop安装配置
1、下载
地址:http://hadoop.apache.org/releases.html

用WinSCP将hadoop-3.0.3.tar.gz 上传到 /data/下
解压 tar -zxvf hadoop-3.0.3.tar.gz
2、配置环境变量:
命令: vi /etc/profile
#HADOOP
HADOOP_HOME=/data/hadoop-3.0.3
PATH=$PATH:$HADOOP_HOME/bin:$HADOOP_HOME/sbin
export HADOOP_HOME
export PATH
export HADOOP_MAPRED_HOME=$HADOOP_HOME
export HADOOP_COMMON_HOME=$HADOOP_HOME
export YARN_HOME=$HADOOP_HOME
export HADOOP_ROOT_LOGGER=INFO,console
export HADOOP_COMMON_LIB_NATIVE_DIR=$HADOOP_HOME/lib/native
export HADOOP_OPTS="-Djava.library.path=$HADOOP_HOME/lib"然后将这些目录通过scp命令拷贝到Slave1和Slave2的相同目录下。
scp -r /etc/profile root@slave1:/etc/
scp -r /etc/profile root@slave2:/etc/分别运行命令:
source /etc/profile3、补全配置文件
配置文件全在hadoop-3.0.0/etc/hadoop里
hadoop-env.sh
添加
export JAVA_HOME=/usr/local/jdk1.8.0_1814、workers
删除localhost
加入slave虚拟机的名称一行一个
例如我的是
slave1
slave2
5、创建文件目录
为了便于管理,给Master的hdfs的NameNode、DataNode及临时文件,在用户目录下创建目录:
mkdir /data/hdfs/tmp
mkdir /data/hdfs/var
mkdir /data/hdfs/logs
mkdir /data/hdfs/dfs
mkdir /data/hdfs/data
mkdir /data/hdfs/name
mkdir /data/hdfs/checkpoint
mkdir /data/hdfs/edits然后将这些目录通过scp命令拷贝到Slave1和Slave2的相同目录下。
scp -r /data/hdfs root@slave1:/data
scp -r /data/hdfs root@slave2:/data
6、Hadoop的配置
进入hadoop-3.0.3的配置目录:
cd /data/hadoop-3.0.3/etc/hadoop
依次修改core-site.xml、hdfs-site.xml、mapred-site.xml、yarn-site.xml以及workers文件。
1)、core-site.xml
<property>
<name>fs.checkpoint.periodname>
<value>3600value>
property>
<property>
<name>fs.checkpoint.sizename>
<value>67108864value>
property>
<property>
<name>fs.defaultFSname>
<value>hdfs://master:9000value>
property>
<property>
<name>hadoop.tmp.dirname>
<value>file:/data/hdfs/tmpvalue>
property>
<property>
<name>hadoop.http.staticuser.username>
<value>rootvalue>
property>2)、hdfs-site.xml
<property>
<name>dfs.replicationname>
2
property>
<property>
<name>dfs.namenode.name.dirname>
file:/data/hdfs/name
property>
<property>
<name>dfs.datanode.data.dirname>
file:/data/hdfs/data
property>
<property>
<name>dfs.namenode.secondary.http-addressname>
master:50090
property>
<property>
<name>dfs.namenode.http-addressname>
master:50070
The address and the base port where the dfs namenode web ui will listen on.
If the port is 0 then the server will start on a free port.
property>
<property>
<name>dfs.namenode.checkpoint.dirname>
file:/data/hdfs/checkpoint
property>
<property>
<name>dfs.namenode.checkpoint.edits.dirname>
file:/data/hdfs/edits
property>3)、mapred-site.xml
<property>
<name>mapreduce.framework.namename>
<value>yarnvalue>
property>
<property>
<name>mapred.job.tarckername>
<value>master:10020value>
property>
<property>
<name>mapreduce.jobhistory.webapp.addressname>
<value>master:19888value>
property>4)、yarn-site.xml
<property>
<name>yarn.resourcemanager.hostnamename>
<value>mastervalue>
property>
<property>
<name>yarn.nodemanager.aux-servicesname>
<value>mapreduce_shufflevalue>
property>
<property>
<name>yarn.nodemanager.aux-services.mapreduce.shuffle.classname>
<value>org.apache.hadoop.mapred.ShuffleHandlevalue>
property>
<property>
<name>yarn.resourcemanager.resource-tarcker.addressname>
<value>master:8025value>
property>
<property>
<name>yarn.resourcemanager.scheduler.addressname>
<value>master:8030value>
property>
<property>
<name>yarn.resourcemanager.addressname>
<value>master:8040value>
property>
<property>
<name>yarn.resourcemanager.admin.addressname>
<value>master:8033value>
property>
<property>
<name>yarn.resourcemanager.webapp.addressname>
<value>master:8088value>
property>7、关掉防火墙
由于hadoop中的程序都是网络服务,需要监听端口,这些端口默认会被linux防火墙挡住。因此要把hadoop中的端口一个个打开,或者把防火墙关掉。由于都是内网,所以关掉就好了。
sudo firewall-cmd –state 查看防火墙状态
sudo systemctl stop firewalld.service 关闭防火墙
再次查看状态,看到已经关闭了。但在下一次开机时还会自启动,因此 sudo systemctl disable firewalld.service 禁止开机时防火墙自启。

8、启动
避免因为缺少用户定义造成的错误
1)、错误:Starting resourcemanager
ERROR: Attempting to launch yarn resourcemanager as root
ERROR: but there is no YARN_RESOURCEMANAGER_USER defined. Aborting launch.
所以分别编辑开始和关闭脚本
vi sbin/start-yarn.sh
vi sbin/stop-yarn.sh
在顶部空白处添加内容:
YARN_RESOURCEMANAGER_USER=root
HADOOP_SECURE_DN_USER=yarn
YARN_NODEMANAGER_USER=root
2)、错误: Starting resourcemanager
ERROR: Attempting to launch yarn resourcemanager as root
ERROR: but there is no YARN_RESOURCEMANAGER_USER defined. Aborting launch.
所以分别编辑开始和关闭脚本
vi sbin/start-yarn.sh
vi sbin/stop-yarn.sh
顶部添加
YARN_RESOURCEMANAGER_USER=root
HADOOP_SECURE_DN_USER=yarn
YARN_NODEMANAGER_USER=root
3)、运行
在master上运行:
hdfs namenode –format不报错并在倒数五六行左右有一句 successfully。。。。即成功
start-dfs.sh
start-yarn.sh或者
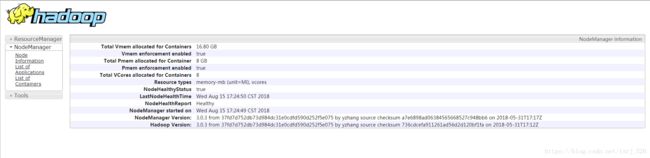
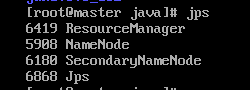
start-all.sh运行完后输入jps可看到master下的节点
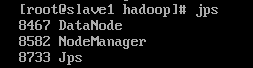
slave下的节点
成功
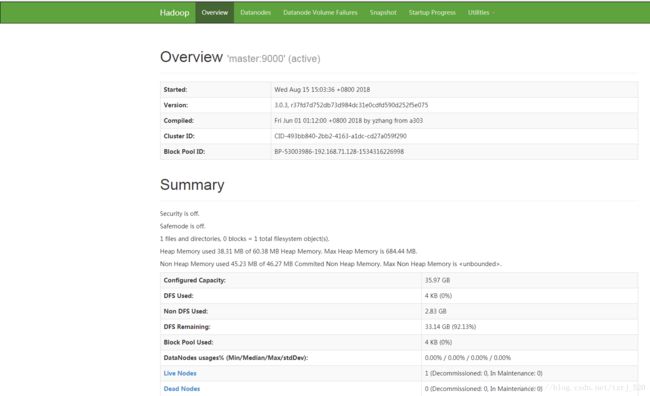
9、测试
地址:http://192.168.71.128:50070
地址:http://192.168.71.128:8088
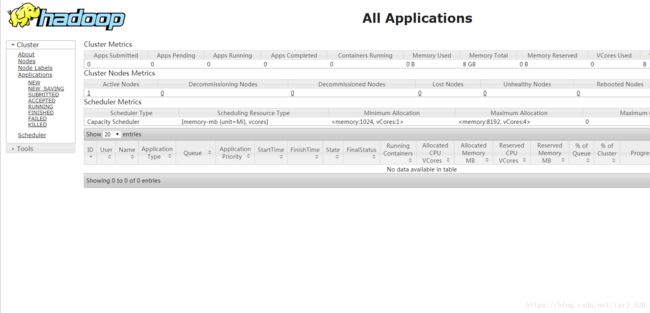
地址:http://192.168.1.35:8042