在Mac上配置Hadoop伪分布式娱乐环境
去年我曾发文记录如何在Ubuntu上配置伪分布式版的Hadoop3娱乐环境:https://fuhailin.github.io/Hadoop-Install/ ,通过配置Hadoop娱乐环境你可以熟悉Hadoop的一些基本概念与操作方式,后来我的Dell被我玩坏了,也就没法在Ubuntu上顺畅娱乐了,后来一狠心入手了现在MacBook Pro,希望它能皮实耐操一点。今天我们继续在MacOS配置一个Hadoop、Spark娱乐环境,看看它能不能运行处理一些HelloWorld程序。
原文链接:https://fuhailin.github.io/Hadoop-on-MacOS/,并首发于我的同名公众号"赵大寳Note"(ID:StateOfTheArt)
0️⃣安装Java
截至目前(2020年02月28日10:54:46)Apache Hadoop 3.x 只支持到了 Java 8,具体支持信息你可以在这里查看:https://cwiki.apache.org/confluence/display/HADOOP/Hadoop+Java+Versions

那我就安装jdk8吧,由于Oracle对JAVA的商业政策变化,目前Java8在Homebrew(关于Homebrew的安装查看我之前的博文:https://fuhailin.github.io/Essential-Apps/#Homebrew)里面被移除了,需要寻找开源版本的openjdk:
brew tap homebrew/cask-versions
brew cask install homebrew/cask-versions/adoptopenjdk8
java -version

1️⃣安装Hadoop
我尝试了通过Homebrew安装Hadoop,但是它在自动安装时总是下载最新版本的jdk13,于是我就直接在官网(https://hadoop.apache.org/releases.html)下载编译好的二进制版Hadoop进行配置。这一步骤与我之前在Ubuntu配置(https://fuhailin.github.io/Hadoop-Install/)情况相同,Binary版本是编译好的二进制版本,可以直接解压安装,我将其解压在了/Users/vincent/opt/hadoop/;另一个包含 src 的则是 Hadoop 源代码,需要进行编译才可使用。
进入解压后的文件目录,测试一下是否正常:./bin/hadoop version

可以看到打印了版本信息。
关注我的公众号"赵大寳Note"(ID:StateOfTheArt),不定期分享编程相关的有趣内容,查看往期精品搜集收藏一起学习。

2️⃣配置SSH免密登录
cat ~/.ssh/id_rsa.pub >> ~/.ssh/authorized_keys
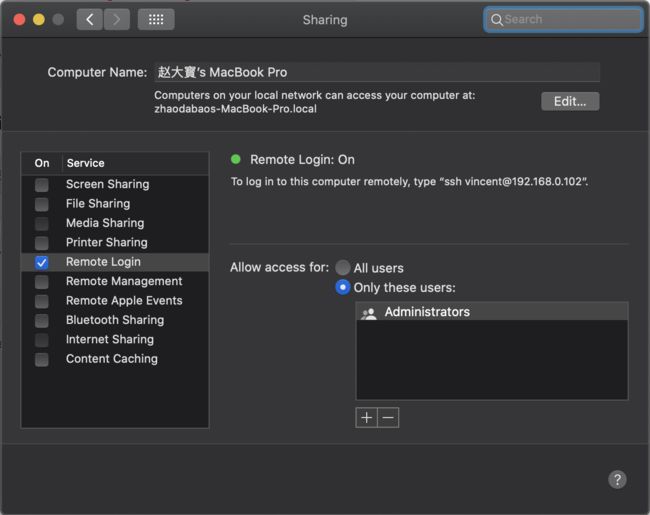
对于Mac系统,需要在计算机系统设置中打开远程登录许可。
3️⃣伪分布式配置
Hadoop 可以在单节点上以伪分布式的方式运行,Hadoop 进程以分离的 Java 进程来运行,节点既作为 NameNode 也作为 DataNode,同时,读取的是 HDFS 中的文件。
Hadoop 的配置文件位于 ./etc/hadoop/ 中,伪分布式需要修改2个配置文件 core-site.xml 和 hdfs-site.xml 。Hadoop的配置文件是 xml 格式,每个配置以声明 property 的 name 和 value 的方式来实现。
输入/usr/libexec/java_home可以查看JAVA_HOME路径。
- 将
JAVA_HOME的路径、HADOOP_HOME,HADOOP_CONF_DIR添加到hadoop-env.sh文件,修改vim ./etc/hadoop/hadoop-env.sh:

- 修改配置文件
./etc/hadoop/core-site.xml:
<configuration>
<property>
<name>hadoop.tmp.dirname>
<value>/Users/vincent/opt/hadoop/hadoop-3.1.3/tmpvalue>
<description>Abase for other temporary directories.description>
property>
<property>
<name>fs.defaultFSname>
<value>hdfs://localhost:9000value>
property>
configuration>
- 修改配置文件
./etc/hadoop/hdfs-site.xml:
<configuration>
<property>
<name>dfs.replicationname>
<value>1value>
property>
<property>
<name>dfs.namenode.name.dirname>
<value>/Users/vincent/opt/hadoop/hadoop-3.1.3/tmp/dfs/namevalue>
property>
<property>
<name>dfs.datanode.data.dirname>
<value>/Users/vincent/opt/hadoop/hadoop-3.1.3/tmp/dfs/datavalue>
property>
configuration>
4️⃣启动与停止Hadoop
第一次启动hdfs需要格式化:./bin/hdfs namenode -format

启动Hadoop:./sbin/start-dfs.sh
启动完成后,可以通过命令 jps 来判断是否成功启动,若成功启动则会列出如下进程: “NameNode”、”DataNode” 和 “SecondaryNameNode”

成功启动后,可以访问 HDFS的Web 界面 http://localhost:9870 查看 NameNode 和 Datanode 信息,还可以在线查看 HDFS 中的文件。

停止Hadoop:./sbin/stop-dfs.sh
5️⃣配置Hadoop环境变量简化命令
给hadoop配置系统环境变量,将下面代码添加到~/.bash_profile文件:
# HADOOP CONFIG
export HADOOP_HOME=/Users/vincent/opt/hadoop/hadoop-3.1.3
export CLASSPATH=$($HADOOP_HOME/bin/hadoop classpath):$CLASSPATH
export HADOOP_COMMON_LIB_NATIVE_DIR=$HADOOP_HOME/lib/native
export PATH=$PATH:$HADOOP_HOME/bin:$HADOOP_HOME/sbin
执行source ~./bash_profile使设置生效
6️⃣运行Hadoop伪分布式实例
由于前面已经配置了Hadoop的环境变量,Hadoop和HDFS的命令已经包含在了系统当中,HDFS有三种shell命令方式:
- hadoop fs : 适用于任何不同的文件系统,比如本地文件系统和HDFS文件系统
- hadoop dfs : 只能适用于HDFS文件系统
- hdfs dfs : 跟hadoop dfs的命令作用一样,也只能适用于HDFS文件系统
估计圆周率PI的值:
cd $HADOOP_HOME
hadoop jar share/hadoop/mapreduce/hadoop-mapreduce-examples-3.1.3.jar pi 2 5
运行结果如下:
Job Finished in 1.441 seconds
Estimated value of Pi is 3.60000000000000000000
计算wordcount:
- 创建input目录和output目录
input作为输入目录,output目录作为输出目录
cd $HADOOP_HOME
mkdir input
mkdir output
- 在input文件夹中创建两个测试文件file1.txt和file2.txt
cd input
echo 'hello world' > file1.txt
echo 'hello hadoop' > file2.txt
- 把测试input文件上传到hdfs中
hadoop fs -put ./input input
复制完成后,可以通过如下命令查看HDFS文件列表:
hdfs dfs -ls input
运行wordcount
hadoop jar share/hadoop/mapreduce/hadoop-mapreduce-examples-3.1.3.jar wordcount ./input ./output
查看output的结果文件
hadoop fs -tail output/part-r-00000
得到的结果是:
- hadoop 1
- hello 2
- world 1
伪分布式运行 MapReduce 作业的方式跟单机模式相同,区别在于伪分布式读取的是HDFS中的文件(可以将单机步骤中创建的本地 input 文件夹,输出结果 output 文件夹都删掉来验证这一点)。
hadoop jar ./share/hadoop/mapreduce/hadoop-mapreduce-examples-*.jar grep input output 'dfs[a-z.]+'
查看运行结果的命令(查看的是位于 HDFS 中的输出结果):
hdfs dfs -cat output/*
结果如下,注意到刚才我们已经更改了配置文件,所以运行结果不同。

我们也可以将运行结果取回到本地:
rm -r ./output # 先删除本地的 output 文件夹(如果存在)
hdfs dfs -get output ./output # 将 HDFS 上的 output 文件夹拷贝到本机
cat ./output/*
Hadoop 运行程序时,输出目录不能存在,否则会提示错误 “org.apache.hadoop.mapred.FileAlreadyExistsException: Output directory hdfs://localhost:9000/user/hadoop/output already exists” ,因此若要再次执行,需要执行如下命令删除 output 文件夹:
hdfs dfs -rm -r output # 删除 output 文件夹
若要关闭 Hadoop,则运行
./sbin/stop-dfs.sh
下次启动 hadoop 时,无需进行 NameNode 的初始化,只需要运行 ./sbin/start-dfs.sh 就可以!
References:
-
Hadoop安装教程_单机/伪分布式配置_Hadoop2.6.0/Ubuntu14.04
-
Ubuntu16.04 下 hadoop的安装与配置(伪分布式环境)
-
Install a Hadoop Cluster on Ubuntu 18.04.1
-
Installing Hadoop on Mac:https://medium.com/beeranddiapers/installing-hadoop-on-mac-a9a3649dbc4d
-
Ubuntu18.04下Hadoop 3的安装与配置(伪分布式环境):https://fuhailin.github.io/Hadoop-Install/