MD5原理及Python实现
简介
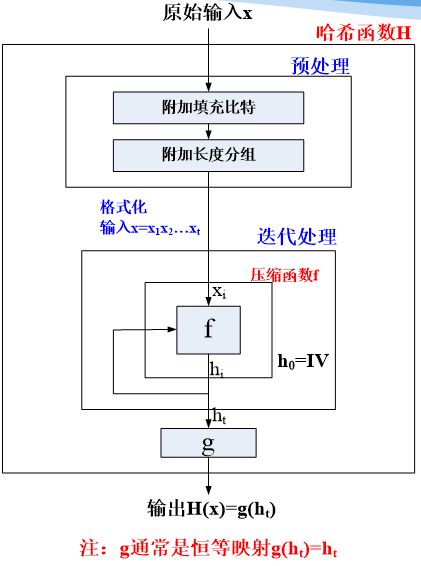
MD5消息摘要算法一种被广泛使用的密码散列函数,输入长度小于264比特的消息,我的代码也是以小于264比特的消息为例,输出一个128位(16字节)的散列值 (hash value),输入信息以512比特的分组为单位处理。
算法流程
- 附加位填充
- 初始化链接变量
- 分组处理
- 步函数的运算
这个流程描述下来非常符合hash函数的一般模型:
单个点拿出来仔细分析
附加位填充
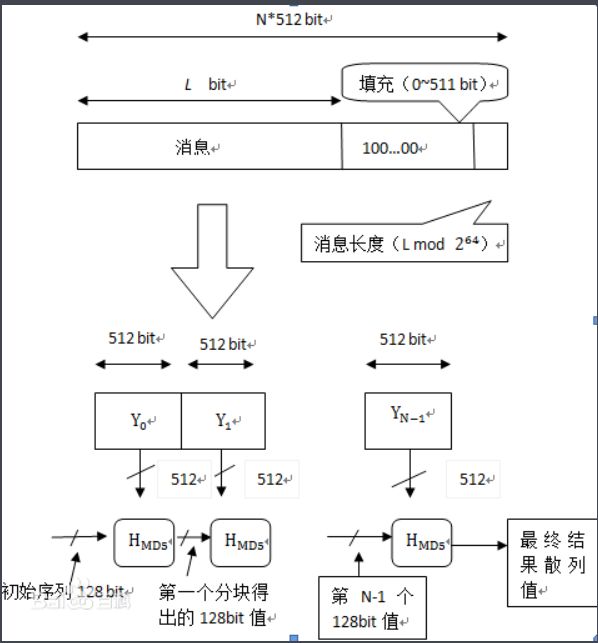
填充一个1和若干个0使消息长度模512与448同余,也就说剩余消息(此处的消息长度已经不满512位了)的最后512比特分组里面加上这一对填充的东西长度应该是448,还剩下64位是消息的长度,满足L mod 2^64,下图就很清楚解释了这一过程:
关键代码:
length = struct.pack(', len(message)*8) #原消息长度64位比特的添加格式,太骚额这种写法
while len(message) > 64:
solve(message[:64])
message = message[64:]
#长度不足64位消息自行填充
message += '\x80'
message += '\x00' * (56 - len(message) % 64)
#print type(length)
message += length
solve(message[:64])
初始化链接变量
使用4个32位的寄存器A, B,C, D存放4个固定的32位整型参数,用于第一轮迭代,这里需要注意,书本上的值是直接给你的,但是没有倒过来,也就是大端和小端的转换问题。
#初始向量
A, B, C, D = (0x67452301, 0xefcdab89, 0x98badcfe, 0x10325476)
# A, B, C, D = (0x01234567, 0x89ABCDEF, 0xFEDCBA98, 0x76543210)
分组处理
与分组密码分组处理相似,有4轮步骤,将512比特的消息分组平均分为16个子分组,每个子分组有32比特,参与每一轮的的16步运算,每步输入是4个32比特的链接变量和一个32位的的消息子分组,经过这样的64步之后得到4个寄存器的值分别与输入的链接变量进行模加,关键代码如下,为了能够保存一下一开始A,B,C,D这四个初始变量的值,所以就先找四个变量把他们的值暂存一下,为最后一步的模加做准备。
def solve(chunk):
global A
global B
global C
global D
w = list(struct.unpack('<' + 'I' * 16, chunk)) #分成16个组,I代表1组32位,tql,学到了
a, b, c, d = A, B, C, D
for i in range(64): #64轮运算
if i < 16: #每一轮运算只用到了b,c,d三个
f = ( b & c)|((~b) & d)
flag = i #用于标识处于第几组信息
elif i < 32:
f = (b & d)|(c & (~d))
flag = (5 * i +1) %16
elif i < 48:
f = (b ^ c ^ d)
flag = (3 * i + 5)% 16
else:
f = c ^(b |(~d))
flag = (7 * i ) % 16
tmp = b + lrot((a + f + k[i] + w[flag])& 0xffffffff,r[i]) #&0xffffffff为了类型转换
a, b, c, d = d, tmp & 0xffffffff, b, c
#print(hex(a).replace("0x","").replace("L",""), hex(b).replace("0x","").replace("L","") , hex(c).replace("0x","").replace("L",""), hex(d).replace("0x","").replace("L",""))
A = (A + a) & 0xffffffff
B = (B + b) & 0xffffffff
C = (C + c) & 0xffffffff
D = (D + d) & 0xffffffff
这上面的代码也包含了第四步的步函数,可以单独把他们提取出来,而不同轮使用的步函数使用的非线性函数是不一样的。即四轮使用四个不同的非线性函数,其实可以发现每个非线性函数的输入不需要A寄存器里面的值,我们只需要B,C,D寄存器里面的东西,这里面得出来的结果分别放进A,C,D寄存器,所以一开始才要找另外的寄存器去存储本身的值,不然的话在转化过程中本身的变量会丢失。
f = ( b & c)|((~b) & d)
f = (b & d)|(c & (~d))
f = (b ^ c ^ d)
f = c ^(b |(~d))
A寄存器里面的值的运算有另外自己的一套模式,先用B,C,D向量里面做一次非线性的运算,然后将得出来的结果依次加上第一个变量,32比特的消息和一个伪随机数常数,再将结果循环左移指定的位数,并加上B的值,最后把得出来的结果放进B寄存器。
#循环左移的位移位数
r = [ 7, 12, 17, 22, 7, 12, 17, 22, 7, 12, 17, 22, 7, 12, 17, 22,
5, 9, 14, 20, 5, 9, 14, 20, 5, 9, 14, 20, 5, 9, 14, 20,
4, 11, 16, 23, 4, 11, 16, 23, 4, 11, 16, 23, 4, 11, 16, 23,
6, 10, 15, 21, 6, 10, 15, 21, 6, 10, 15, 21, 6, 10, 15, 21
]
lrot = lambda x,n: (x << n)|(x >> 32- n)
#使用正弦函数产生的位随机数,也就是书本上的T[i]
k = [int(math.floor(abs(math.sin(i + 1)) * (2 ** 32))) for i in range(64)]
tmp = b + lrot((a + f + k[i] + w[flag])& 0xffffffff,r[i])
正确性
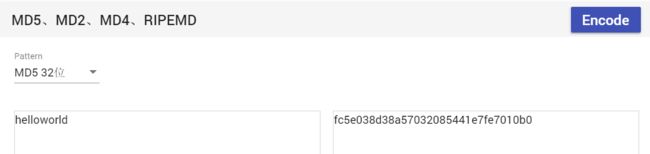
以"helloworld"为例,分别将其在代码中运行,以及线上工具运行,检查它们的一致性。