Atlas源码解读(1)图数据库JanusGraph
Aparche Atlas是Hadoop数据治理与元数据框架,提供了高效数据查询与分类系统,同时支持数据审计与数据血缘关系的建立。小编认为随大数据发展,数据结构与类型将越来越复杂,元数据治理与数据关系建立将是完成数据挖掘,实现人工智能的重要前提。
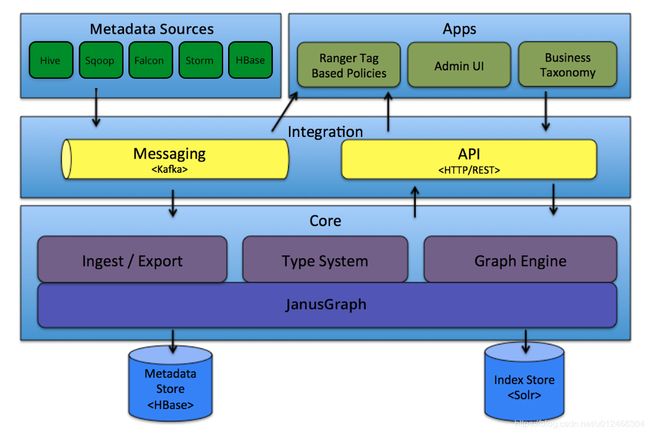
Atlas收集大数据组件元数据通过集成构件kafka传输至底层数据处理构件JanusGraph,JanusGraph作为数据处理核心,为数据存储,关系建立,数据血缘建立,数据查询提供便利。
【JanusGraph基础】
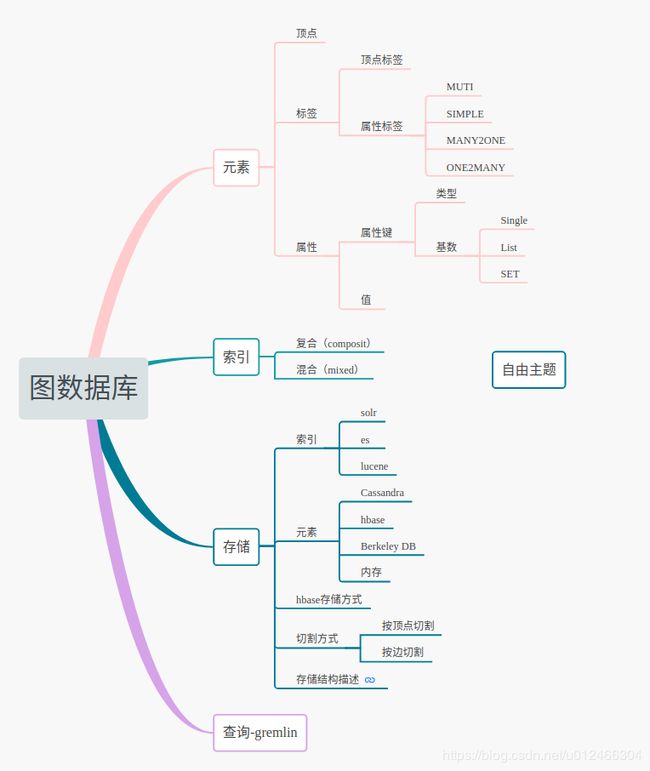
图数据库适用于大数据复杂关系分析的业务场景,关系型数据库通过join的方式进行数据处理,降低数据处理效率;图数据库采用有向图的数据结构,并以索引的方式进行数据检索,提高数据处理效率。JaunusGraph是为数不多的支持分布式的图数据库,适应于大数据发展趋势,可能正是以为如此,所以Atlas选择采用JanusGraph进行数据治理。
关于图数据库的基本使用与介绍可以参考胡佳辉写的《图数据库 JanusGraph 实战》
JanusGraph使用的可视化工具:gephi
搭建:https://www.codercto.com/a/50031.html
使用:https://www.jianshu.com/p/dbb63cdced90
官网:https://gephi.org/tutorials/gephi-tutorial-quick_start.pdf
【Atlas封装JanusGraph】
所有关于图数据库的操作均位于atlas-graphdb子工程下,我们看下该自工程下所有内容:

api定义构成图数据库的基本元素接口,包括属性键,边,边方向, 边标签定义,属性元素定义,图,索引,图管理器(包括事务处理,属性键管理,索引定义),图查询器,遍历器,索引查询器,属性键,顶点,定点查询器;common定义查询语义,例如and,has,in,or,orderby;janus是对元素定义,图数据库查询,数据迁徙的具体实现。
图数据库建立流程如下:
1. 配置文件配置图数据库的数据存储位置和索引存储位置:
atlas.graphdb.backend=org.apache.atlas.repository.graphdb.janus.AtlasJanusGraphDatabase
# Graph Storage
atlas.graph.storage.backend=hbase
atlas.graph.storage.port=2181
atlas.graph.storage.hbase.table=atlas-test
atlas.graph.storage.hostname=docker2,docker3,docker4
# Graph Search Index Backend
atlas.graph.index.search.backend=elasticsearch
atlas.graph.index.search.hostname=127.0.0.1
atlas.graph.index.search.index-name=atlas_test2. 初始化图数据库与数据库管理器:
public static JanusGraph getGraphInstance() {
if (graphInstance == null) {
synchronized (AtlasJanusGraphDatabase.class) {
if (graphInstance == null) {
Configuration config;
try {
config = getConfiguration();
} catch (AtlasException e) {
throw new RuntimeException(e);
}
try {
graphInstance = JanusGraphFactory.open(config);
} catch (JanusGraphException e) {
LOG.warn("JanusGraphException: {}", e.getMessage());
if (e.getMessage().startsWith(OLDER_STORAGE_EXCEPTION)) {
LOG.info("Newer client is being used with older janus storage version. Setting allow-upgrade=true and reattempting connection");
config.addProperty("graph.allow-upgrade", true);
graphInstance = JanusGraphFactory.open(config);
}
else {
throw new RuntimeException(e);
}
}
atlasGraphInstance = new AtlasJanusGraph();
validateIndexBackend(config);
}
}
}
return graphInstance;
}3. 根据业务需要定义schema,初始化顶点标签,边标签,属性键和索引等
AtlasJanusGraphDatabase db = new AtlasJanusGraphDatabase();
AtlasGraphManagement mgmt = db.getGraph().getManagementSystem();
if (mgmt.getGraphIndex(BACKING_INDEX_NAME) == null) {
//提前定义定点混合索引
mgmt.createVertexMixedIndex(BACKING_INDEX_NAME, Constants.BACKING_INDEX, Collections.emptyList());
}
//定义属性键age13
mgmt.makePropertyKey("age13", Integer.class, AtlasCardinality.SINGLE);
//定义属性键和索引
createIndices(mgmt, "name", String.class, false, AtlasCardinality.SINGLE);
createIndices(mgmt, WEIGHT_PROPERTY, Integer.class, false, AtlasCardinality.SINGLE);
createIndices(mgmt, "size15", String.class, false, AtlasCardinality.SINGLE);
createIndices(mgmt, "typeName", String.class, false, AtlasCardinality.SINGLE);
createIndices(mgmt, "__type", String.class, false, AtlasCardinality.SINGLE);
createIndices(mgmt, Constants.GUID_PROPERTY_KEY, String.class, true, AtlasCardinality.SINGLE);
createIndices(mgmt, Constants.TRAIT_NAMES_PROPERTY_KEY, String.class, false, AtlasCardinality.SET);
createIndices(mgmt, Constants.SUPER_TYPES_PROPERTY_KEY, String.class, false, AtlasCardinality.SET);
mgmt.commit();4. 创建顶点,属性等:
AtlasGraph graph = getGraph();
AtlasVertex v1 = createVertex(graph);
v1.setProperty("name", "Fred");
v1.setProperty("size15", "15");
//createVertex方法:
//使用JanusGraph建立顶点
Vertex result = getGraph().addVertex();
//封装顶点和AtlasGraph
return GraphDbObjectFactory.createVertex(this, result); 【总结】
图数据库的编程思想以顶点,边,属性出发,首先建立schema,类似于关系型数据库对表,字段的约束,边标签的多样性约束一对定点间边的个数,属性键类型约束数据存储格式,基数限制属性存储方式;数据存储采用分布式数据库Hbase,Cassardan,并建立图数据库索引;数据查询使用Gremlin进行关系遍历。