【Spark benchmark】 NMON 和 BigDataBench测试
Benchmark测试:NMON + BigDataBench
一、 NMON监控、分析系统性能
1. 在Linux中使用apt-get install nmon安装
2. 输入nmon显示下面页面表示安装成功

3. 生成报表: 如 nmon –s2 –c1800 –f –m~/code/tmp/benchmark
-s2 每 2 秒采集一次数据。
-c1800 采集 1800 次,即为采集十分钟的数据。
-f 生成的数据文件名中包含文件创建的时间。
-m 生成的数据文件的存放目录。
4. 生成性能报告表格文档:
使用nmon analyser_v34a.xls文件,传入上述报表文件,即可生成性能报表,如下图:

二、 基准测试工具:BigDataBench
2.1 安装BigDataBench:
1. 下载BigDataBench_V3.2.5_Spark.tar.gz并解压到相应文件夹
2. 按着本机的jdk、hadoop、scala、spark等配置conf_properties文件
3. 编译源码,执行sudo ./prepar.sh
2.2 生成测试数据:
1. 进入MicroBenchmarks文件夹,运行genData_MicroBenchmarks.sh:
sh genData_MicroBenchmarks.sh (采用bash而非dash)
2. 输入想生成的数据大小,等待片刻即可在./MicroBenchmarks/data-MicroBenchmarks中找到新生成的数据文件。
3. 将生成的数据放入HDFS中(该过程在生成数据后自动执行,可在hdfs的/data-MicroBenchmarks可看到上传的文件)
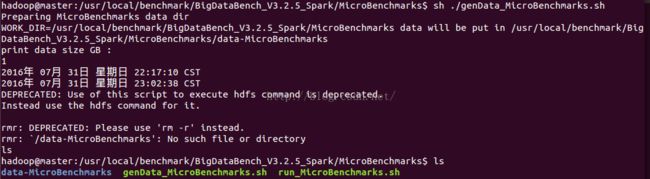
4. 执行run_MicroBnechmarks.sh即可测spark中的sort、gerp、wordcount函数性能。
三、 基准测试:
3.1 集群环境:
| 集群 |
主机名 |
| Master |
master |
| Worker |
master、master1、sparkworker1 |
3.2 提前工作:
1. 准备好测试数据(1G,两个文件,由上述genData_MicroBenchmarks.sh生成)
2. 在每台主机中进行NMON监控(采集60分钟内数据,2秒采集一次):
输入命令:nmon -s2 -c1800 -f -m~/code/tmp/benchmark
3. 准备好时间登记
时间安排(2016年8月1日10:59 - 11:59)
| 10:59:00 |
三台主机启动nmon监控 |
| 11:00:00 |
Master启动Hadoop集群 |
| 11:01:00 |
Hadoop集群启动完毕 |
| 11:03:00 |
启动tachyon集群(SudoMount方式) |
| 11:03:40 |
Tachyon集群启动完成 |
| 11:05:00 |
启动spark集群 |
| 11:05:15 |
Spark集群启动完毕 |
| 11:06:50 |
启动spark-shell(集群方式) |
| 11:07:45 |
Spark-shell启动完成 |
| 11:15:00 |
HDFS中删除1G的文件 |
| 11:15:10 |
删除完成 |
| 11:20:00 |
Spark集群排序Sort测试 |
| 11:20:20 |
程序报错(环境变量未设置好) |
| 11:21:30 |
Spark集群排序Sort测试 |
| 11:26:15 |
排序完成 |
| 11:34:00 |
打开FireFox浏览器进行查看HDFS及集群情况 |
| 11:36:10 |
关闭FireFox |
| 11:41:00 |
Spark集群Grep测试 |
| 11:43:30 |
Grep测试完毕 |
| 11:45:00 |
Spark集群WordCount测试 |
| 11:46:30 |
WordCount测试完成 |
| 11:49:00 |
Spark-shell集群退出 |
| 11:50:00 |
关闭Spark集群 |
| 11:51:00 |
关闭tachyon |
| 11:52:00 |
关闭Hadoop集群 |
3.3 集群启动:
1. 启动Hadoop集群
2. 启动tachyon集群
3. 启动spark集群
3.4 Sort、Grep、WordCount测试:
在BigDataBench中的MicroBenchmarks内运行run_MicroBnechmarks.sh:
shrun_MicroBnechmarks.sh
选择相应函数进行测试即可,如下图:

3.5 生成性能报告文档:
1. 从集群中的~/code/tmp/benchmark中提取出已生成的监控文档
2. 使用nmon analyser_v34a.xls生成集群中全部主机的1h性能报表
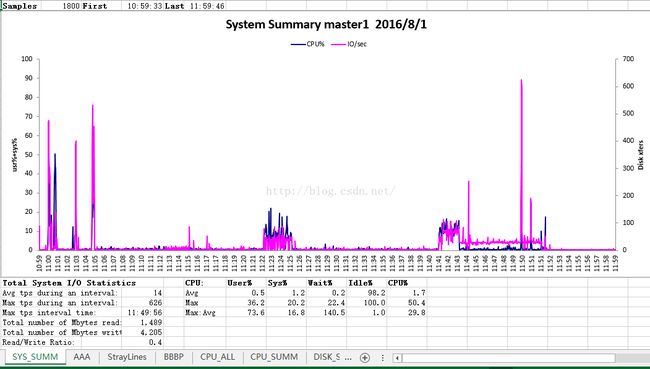
Master兼 Worker:主机master报表

Worker:主机master1 报表
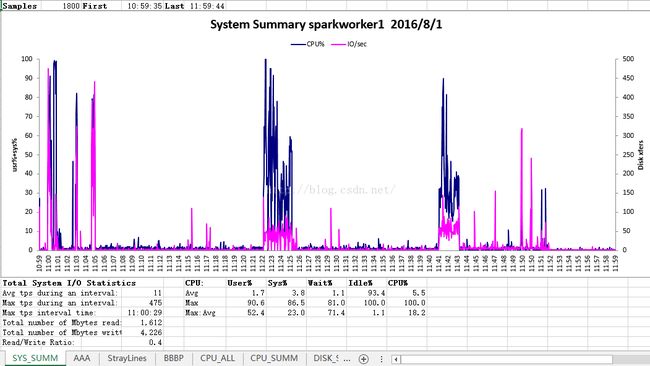
Worker : 主机sparkworker1 报表:
四、 测试分析:
4.1 集群启动与关闭分析:
当启动或者关闭hadoop、spark、tachyon集群之一时,Master的cpu占有率突变而IO读写速度不大,Worker的IO读写速度突变而cpu占有率不大。
4.2 Sort、Grep、WordCount分析
4.3.1 Sort操作
Sort操作是在11:21-11:26期间运行的.
1. 由Master监控文件知,整个Sort操作中,cpu占有率基本在80%-100%,而I/O则在第1/5至2/5时间左右维持在高峰2M/s以上,而其他时间维持在500kb/s内。
在网络IO的读写中,在11:22分左右产生读写爆发期(读写均在50MB/s-60MB/s,在23分-26分间,网络IO读写维持在较低水平上(读10MB/s上下、写30MB/s上下)。
2. 由sparkworker1监控文件知:整个sort操作中,cpu在前半段占用率很高,达70-100%,而后半段占用率40%左右。 而I/O则在较低的水平(相比master),在50kb/s上下波动。
3. 而master1(Worker之一),在整个sort操作用,cpu占用在15%,I/O维持在100kb/s
网络IO中,在整个阶段,读在7MB/s,写在11:23分后爆发,达17MBkb/s
4.3.1 Grep操作
Grep操作是在11:41-11:43执行的
1. Master中,cpu占有率突变到90%,而IO读写在300kb/s,网络IO读写速率在20MB/s到40MB/s上下
2. Worker中的master1的cpu占有率在10%,IO读写在100kb/s,网络IO读速度在7MB/s,写速度在17MB/s; sparkworker1的cpu占有率突变到70%,IO读写在70kb/s,网络IO读速度在7MB/s,写速率只在前期,达17MB/s
4.3.1 WordCount操作
Wordcount操作是在11:45-11:46执行的:
1. Master中cpu占有率突变到100%,IO读写在300kb/s,网络IO读写速度在20MB/s。
2. Worker中的主机master1和sparkworker1的cpu和IO均无太大变化,而网络读写IO无显示(几乎为0kb/s),尚不清楚为何。
五、 总结:
1. 了解并学习了基于spark的Benchmark,以及NMON监测的操作。
2. 发现了一些问题,比如master的负担太大,下次应尝试将Worker不包括master、两个Worker的负担有差别,应该设法让两个Worker分配的任务一样或相近。
3. NMON的性能报告表中含有很多参数信息,目前只能部分了解。
4. BigDataBench中还有很多测试例子,比如PageRank等,均尚未运行测试。