地址:https://arxiv.org/pdf/2007.04242.pdf
github:https://github.com/zhuogege1943/dgc/
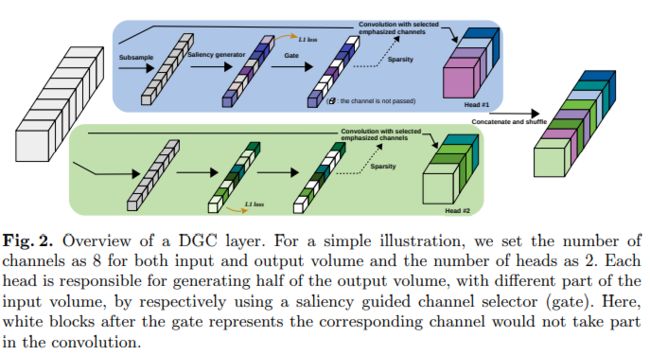
from __future__ import absolute_import from __future__ import unicode_literals from __future__ import print_function from __future__ import division import torch import torch.nn as nn import torch.nn.functional as F class DynamicMultiHeadConv(nn.Module): global_progress = 0.0 def __init__(self, in_channels, out_channels, kernel_size, stride=1, padding=0, dilation=1, heads=4, squeeze_rate=16, gate_factor=0.25): super(DynamicMultiHeadConv, self).__init__() self.norm = nn.BatchNorm2d(in_channels) self.relu = nn.ReLU(inplace=True) self.avg_pool = nn.AdaptiveAvgPool2d(1) self.in_channels = in_channels self.out_channels = out_channels self.heads = heads self.squeeze_rate = squeeze_rate self.gate_factor = gate_factor self.stride = stride self.padding = padding self.dilation = dilation self.is_pruned = True self.register_buffer('_inactive_channels', torch.zeros(1)) ### Check if arguments are valid assert self.in_channels % self.heads == 0, \ "head number can not be divided by input channels" assert self.out_channels % self.heads == 0, \ "head number can not be divided by output channels" assert self.gate_factor <= 1.0, "gate factor is greater than 1" for i in range(self.heads): self.__setattr__('headconv_%1d' % i, HeadConv(in_channels, out_channels // self.heads, squeeze_rate, kernel_size, stride, padding, dilation, 1, gate_factor)) def forward(self, x): """ The code here is just a coarse implementation. The forward process can be quite slow and memory consuming, need to be optimized. """ if self.training: progress = DynamicMultiHeadConv.global_progress # gradually deactivate input channels if progress < 3.0 / 4 and progress > 1.0 / 12: self.inactive_channels = round(self.in_channels * (1 - self.gate_factor) * 3.0 / 2 * (progress - 1.0 / 12)) elif progress >= 3.0 / 4: self.inactive_channels = round(self.in_channels * (1 - self.gate_factor)) _lasso_loss = 0.0 x = self.norm(x) x = self.relu(x) x_averaged = self.avg_pool(x) x_mask = [] weight = [] for i in range(self.heads): i_x, i_lasso_loss= self.__getattr__('headconv_%1d' % i)(x, x_averaged, self.inactive_channels) x_mask.append(i_x) weight.append(self.__getattr__('headconv_%1d' % i).conv.weight) _lasso_loss = _lasso_loss + i_lasso_loss x_mask = torch.cat(x_mask, dim=1) # batch_size, 4 x C_in, H, W weight = torch.cat(weight, dim=0) # 4 x C_out, C_in, k, k out = F.conv2d(x_mask, weight, None, self.stride, self.padding, self.dilation, self.heads) b, c, h, w = out.size() out = out.view(b, self.heads, c // self.heads, h, w) out = out.transpose(1, 2).contiguous().view(b, c, h, w) return [out, _lasso_loss] @property def inactive_channels(self): return int(self._inactive_channels[0]) @inactive_channels.setter def inactive_channels(self, val): self._inactive_channels.fill_(val) class HeadConv(nn.Module): def __init__(self, in_channels, out_channels, squeeze_rate, kernel_size, stride=1, padding=0, dilation=1, groups=1, gate_factor=0.25): super(HeadConv, self).__init__() self.conv = nn.Conv2d(in_channels, out_channels, kernel_size, stride, padding, dilation, groups=1, bias=False) self.target_pruning_rate = gate_factor if in_channels < 80: squeeze_rate = squeeze_rate // 2 self.fc1 = nn.Linear(in_channels, in_channels // squeeze_rate, bias=False) self.relu_fc1 = nn.ReLU(inplace=True) self.fc2 = nn.Linear(in_channels // squeeze_rate, in_channels, bias=True) self.relu_fc2 = nn.ReLU(inplace=True) nn.init.kaiming_normal_(self.fc1.weight) nn.init.kaiming_normal_(self.fc2.weight) nn.init.constant_(self.fc2.bias, 1.0) def forward(self, x, x_averaged, inactive_channels): b, c, _, _ = x.size() x_averaged = x_averaged.view(b, c) y = self.fc1(x_averaged) y = self.relu_fc1(y) y = self.fc2(y) mask = self.relu_fc2(y) # b, c _lasso_loss = mask.mean() mask_d = mask.detach() mask_c = mask if inactive_channels > 0: mask_c = mask.clone() topk_maxmum, _ = mask_d.topk(inactive_channels, dim=1, largest=False, sorted=False) clamp_max, _ = topk_maxmum.max(dim=1, keepdim=True) mask_index = mask_d.le(clamp_max) mask_c[mask_index] = 0 mask_c = mask_c.view(b, c, 1, 1) x = x * mask_c.expand_as(x) return x, _lasso_loss class Conv(nn.Sequential): def __init__(self, in_channels, out_channels, kernel_size, stride=1, padding=0, groups=1): super(Conv, self).__init__() self.add_module('norm', nn.BatchNorm2d(in_channels)) self.add_module('relu', nn.ReLU(inplace=True)) self.add_module('conv', nn.Conv2d(in_channels, out_channels, kernel_size=kernel_size, stride=stride, padding=padding, bias=False, groups=groups))