Spark开发实例(SequoiaDB)
实验 1
搭建 Spark 实例应用开发环境
程序中会创建 JDBC 连接,并通过 JDBC 在 Spark SQL 中创建 jdbc_sample 集合的映射表,向映射表中插入一条记录后查询 jdbc_sample 记录打印到控制台,最终关闭 JDBC 的连接资源
// Call the predefined SdbUtil class to create a collection space and collection
SdbUtil.initCollectionSpace("sample");
SdbUtil.initCollection("sample", "jdbc_sample");
// Load Hive JDBC driver
Class.forName("org.apache.hive.jdbc.HiveDriver");
// Create a Hive JDBC connection
Connection connection = DriverManager.getConnection(
"jdbc:hive2://sdbserver1:10000/default",// Hive JDBC connection url
"sdbadmin",// Hive JDBC connection user name
""// Hive JDBC connection password (authentication is not enabled by default)
);
// Create Statement
Statement statement = connection.createStatement();
// Drop the existing table
String dropTable = "DROP TABLE IF EXISTS jdbc_sample";
// Execute the SQL statement of drop table
statement.execute(dropTable);
// Create a mapping table
String mapping =
"CREATE TABLE jdbc_sample ( id INT, val VARCHAR ( 10 ) )" +
"USING com.sequoiadb.spark " +
"OPTIONS(" +
"host 'sdbserver1:11810'," +
"collectionspace 'sample'," +
"collection 'jdbc_sample'" +
")";
// Execute the SQL statement of create a mapping table
statement.execute(mapping);
// Insert record
String insert = "INSERT INTO jdbc_sample VALUES ( 1, 'SequoiaDB' )";
// Execute the SQL statement of insert record
statement.executeUpdate(insert);
// Query record
String query = "SELECT * FROM jdbc_sample";
// Execute the SQL statement of query record to get result set
ResultSet resultSet = statement.executeQuery(query);
// Call the predefined result set to beautify the utility class and print the result set
ResultFormat.printResultSet(resultSet);
// Release JDBC sources
resultSet.close();
statement.close();
connection.close();
实验 2
数据库及表的创建
程序中会创建 MySQL JDBC 连接,并使用该连接创建 ScriptRunner 对象,调用 ScriptRunner 执行 sql 文件写入数据后,查询数据将结果集打印到控制台,最终关闭 JDBC 连接资源。为了更简洁地展示代码内容,程序中将异常抛出。
// Load MySQL JDBC Driver class
Class.forName("com.mysql.jdbc.Driver");
// Create MySQL connection
Connection connection = DriverManager.getConnection(
"jdbc:mysql://sdbserver1:3306/sample?useSSL=false",
"sdbadmin",
"sdbadmin");
// Create ScriptRunner
ScriptRunner runner = new ScriptRunner(connection, false, false);
// Turn off log printing
runner.setLogWriter(null);
// Execute sql file via ScriptRunner
runner.runScript(FileUtil.getFile("src/main/resources/sql/employee.sql"));
// Close connection
Statement statement = connection.createStatement();
// Query result set
ResultSet resultSet = statement.executeQuery("SELECT * FROM employee");
// Call the predefined result set to beautify the utility class and print the result set
ResultFormat.printResultSet(resultSet);
// Close ResultSet
resultSet.close();
// Close Statement
statement.close();
// Close Connection
connection.close();
Spark SQL 建库
获取 JDBC 连接代码:程序中将加载 Hive JDBC 驱动,指定 Hive JDBC 的连接地址、用户名和密码创建 JDBC 连接并返回连接,创建数据库和创建映射表的实验步骤中会调用方法获取 JDBC 连接。
try {
// Load Hive JDBC driver
Class.forName("org.apache.hive.jdbc.HiveDriver");
// Create Hive JDBC connection
connection = DriverManager.getConnection(
"jdbc:hive2://sdbserver1:10000/"+database,// Hive JDBC connection url
"sdbadmin",// Hive JDBC connection user name
""// Hive JDBC connection password (authentication is not enabled by default)
);
} catch (ClassNotFoundException e) {
e.printStackTrace();
} catch (SQLException e) {
e.printStackTrace();
}
释放 JDBC 资源代码:程序中将接收 ResultSet、Statement 和 Connection 对象,若对象不为空则将其关闭。在创建数据库或创建映射表完成后将调用方法释放 JDBC 资源。
try {
// Release ResultSet
if (resultSet != null) {
resultSet.close();
}
// Release Statement
if (statement != null) {
statement.close();
}
// Release Connection
if (connection != null) {
connection.close();
}
} catch (SQLException e) {
e.printStackTrace();
}
创建数据库代码
程序中将调用 getConnection 方法获取 JDBC 连接,并创建 Statement 对象执行创建sample 库的 SQL 语句。sample 库创建完成后程序将查询所有库并打印结果集。最终调用 releaseSource 释放 JDBC 资源
// Get Hive JDBC connection
Connection connection = getConnection("default");
// Initialize Statement
Statement statement = null;
// Initialize ResultSet
ResultSet resultSet = null;
try {
// SQL statement of create database
String createDatabaseSQL = "CREATE DATABASE IF NOT EXISTS " + databaseName;
// Create Statement
statement = connection.createStatement();
// Execute the SQL statement of create database
statement.execute(createDatabaseSQL);
// View the database statement
String showDatabases = "SHOW DATABASES";
// Execute the view database statement to get the result set
resultSet = statement.executeQuery(showDatabases);
// Call the predefined result set to beautify the utility class and print the result set
ResultFormat.printResultSet(resultSet);
} catch (SQLException e) {
e.printStackTrace();
} finally {
// Release Statement and Connection source
releaseSource(resultSet, statement, connection);
}
映射 SequoiaDB 集合

创建映射表程序代码。程序中将调用 getConnection 方法获取 JDBC 连接,使用 JDBC 连接创建 Statement 执行创建映射表 SQL 语句,建表完成后将查询映射表的表结构和数据内容,并将查询结果集打印至控制台。所有数据操作执行完毕后将释放 JDBC 资源。
// Get Hive JDBC connection
Connection connection = getConnection("sample");
// Initialize Statement
Statement statement = null;
// Initialize ResultSet
ResultSet resultSet = null;
try {
// Create Statement
statement = connection.createStatement();
// Drop the existing employee table
String dropTable =
"DROP TABLE IF EXISTS employee";
// Execute the SQL statement of drop table
statement.execute(dropTable);
// Create a mapping table for the employee collection
String mappingTable =
"CREATE TABLE employee " +
"USING com.sequoiadb.spark " +
"OPTIONS( " +
"host 'sdbserver1:11810', " +
"collectionspace 'sample', " +
"collection 'employee', " +
"user 'sdbadmin'," +
"password 'sdbadmin'" +
")";
// Execute the SQL statement of create mapping table
statement.execute(mappingTable);
// Get the structure of mapping table
String getDesc =
"DESC employee";
// Execute the SQL statement of getting mapping table structure to get the result set
resultSet = statement.executeQuery(getDesc);
// Call the predefined result set to beautify the utility class and print the result set
System.out.println("Printing table structure...");
ResultFormat.printResultSet(resultSet);
// Get the data of mapping table
String queryTable = "SELECT * FROM employee";
// Execute the SQL statement of get mapping table data to get the result set
resultSet = statement.executeQuery(queryTable);
// Call the predefined result set to beautify the utility class and print the result set
System.out.println("Printing query result set...");
ResultFormat.printResultSet(resultSet);
} catch (SQLException e) {
e.printStackTrace();
} finally {
// Release JDBC source
releaseSource(resultSet, statement, connection);
}
实验 3
数据类型
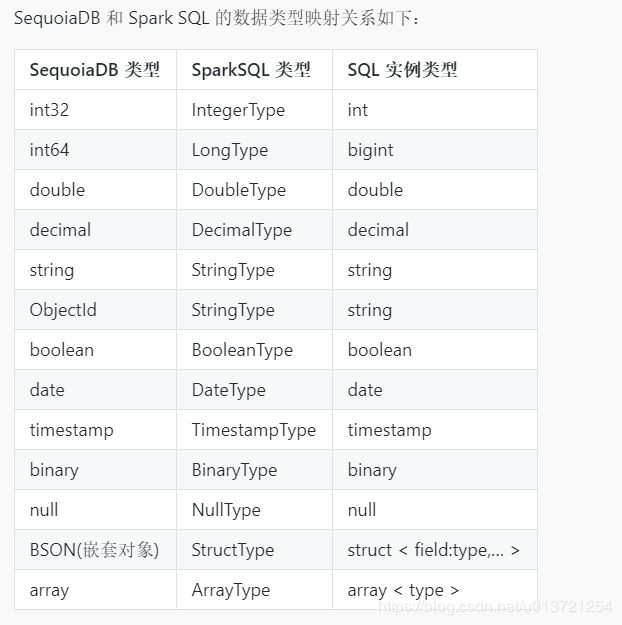
在上一章中介绍了 Spark 在在映射有数据的 SequoiaDB 集合时会自动生成表结构,实际上在映射无数据的 SequoiaDB 集合时也可以手动指定映射表的表结构。
CREATE TABLE typelist( -- 定义各个字段数据类型
IntegerType int,
LongType bigint,
DoubleType double,
DecimalType decimal(10,1),
StringType string,
BooleanType boolean,
DateType date,
TimestampType timestamp,
BinaryType binary,
ArrayType array,
StructType struct < key:int , val:array >
) USING com.sequoiadb.spark -- 使用 SequoiaDB 的 Spark 连接驱动
OPTIONS(
host 'sdbserver1:11810', -- 指定访问 SequoiaDB 使用的主机名(也可以是ip)和协调节点
collectionspace 'sample', -- 映射集合所在的集合空间名
collection 'typelist' -- 映射集合名
); * 由于 SequoiaDB 的连接鉴权默认是无密码的,用户名和密码在此可以省略

创建映射表代码。运行程序时会自动创建 SequoiaDB 中的 typelist 集合。程序中将调用封装好的类获取 JDBC 连接,使用 JDBC 连接创建 Statement 执行创建映射表 SQL 语句,建表完成后将查询映射表的表结构,并将查询结果集打印至控制台。所有数据操作执行完毕后将释放 JDBC 资源。
// Get Hive JDBC connection
Connection connection = HiveUtil.getConnection();
// Initialize Statement
Statement statement = null;
// Initialize ResultSet
ResultSet resultSet = null;
try {
// Create Statement
statement = connection.createStatement();
// Drop the existing typelist table
String dropTable = "DROP TABLE IF EXISTS typelist";
// Execute the SQL statement of drop table
statement.executeUpdate(dropTable);
// Create Spark Table and specify the data type of each field
String mappingCollection =
"CREATE TABLE typelist(" +
"IntegerType int," +
"LongType bigint," +
"DoubleType double," +
"DecimalType decimal(10,1)," +
"StringType string," +
"BooleanType boolean," +
"DateType date," +
"TimestampType timestamp," +
"BinaryType binary," +
"ArrayType array," +
"StructType struct>" +
") USING com.sequoiadb.spark " +
"OPTIONS(" +
"host 'sdbserver1:11810'," +
"collectionspace 'sample'," +
"collection 'typelist'" +
")";
// Execute the SQL statement of create table
System.out.println("Creating mapping table in Spark SQL...");
statement.execute(mappingCollection);
// Get the structure of mapping table
String getDesc =
"DESC typelist";
// Execute the SQL statement of getting mapping table structure to get the result set
resultSet = statement.executeQuery(getDesc);
// Call the predefined result set to beautify the utility class and print the result set
System.out.println("Printing table structure...");
ResultFormat.printResultSet(resultSet);
} catch (SQLException e) {
e.printStackTrace();
} finally {
// Release Hive JDBC source
HiveUtil.releaseSource(resultSet, statement, connection);
}
插入记录
插入记录程序代码。程序中将调用封装好的类获取 JDBC 连接,使用 JDBC 连接创建 Statement 执行插入记录 SQL 语句,插入数据完成后将分别查询 typelist 映射表和 typelist 集合中的数据内容,并将查询结果集打印至控制台。所有数据操作执行完毕后将释放 JDBC 资源。
// Get Hive JDBC connection
Connection connection = HiveUtil.getConnection();
// Initialize Statement
Statement statement = null;
// Initialize ResultSet
ResultSet resultSet = null;
try {
// Create Statement
statement = connection.createStatement();
// SQL of insert record
String insertRecord =
"INSERT INTO typelist " +
"VALUES(" +
"1," +
"9223372036854775807," +
"3.1415," +
"3.14," +
"'abc'," +
"true," +
"current_date()," +
"current_timestamp()," +
"encode('qazwsxedc','UTF-8')," +
"array(1,2,3)," +
"struct(123,array(1,2,3))" +
")";
// Execute the SQL statement of insert record
statement.executeUpdate(insertRecord);
// SQL of query the mapping table result set
String getRecord = "SELECT * FROM typelist";
// Execute the SQL of query result set
resultSet = statement.executeQuery(getRecord);
// Call the predefined result set to beautify the utility class and print the result set
System.out.println("Printing record in Spark table...");
ResultFormat.printResultSet(resultSet);
// Call the predefined utility class to print SequoiaDB collection
System.out.println("Printing record in SequoiaDB collection...");
SdbUtil.printCollection("sample", "typelist");
} catch (SQLException e) {
e.printStackTrace();
} finally {
// Release Hive JDBC source
HiveUtil.releaseSource(resultSet, statement, connection);
}
实验 4
数据操作
创建映射表程序代码。程序中将调用封装好的类获取 JDBC 连接,使用 JDBC 连接创建 Statement 执行创建映射表 SQL 语句,建表完成后将查询映射表的数据内容,并将查询结果集打印至控制台。所有数据操作执行完毕后将释放 JDBC 资源。
// Get Hive JDBC connection
Connection connection = HiveUtil.getConnection();
// Initialize Statement
Statement statement = null;
// Initialize ResultSet
ResultSet resultSet = null;
try {
// Create Statement
statement=connection.createStatement();
// Drop the existing department table
String dropDepartment = "DROP TABLE if EXISTS department";
// Execute the SQL statement of drop table
statement.execute(dropDepartment);
// Create department mapping table
String linkDepartment =
"CREATE TABLE department " +
"using com.sequoiadb.spark " +
"options( " +
"host 'sdbserver1:11810', " +
"collectionspace 'sample', " +
"collection 'department' " +
")";
// Execute the SQL statement of create mapping table
statement.execute(linkDepartment);
// Get the structure of mapping table
String showDesc = "desc department";
// Execute the SQL statement of getting mapping table structure to get the result set
resultSet=statement.executeQuery(showDesc);
// Call the predefined result set to beautify the utility class and print the result set
System.out.println("Printing table structure...");
ResultFormat.printResultSet(resultSet);
// Query the records of mapping table
String queryResultSet = "SELECT * FROM department";
// Execute the SQL statement of query mapping table record to get result set
resultSet=statement.executeQuery(queryResultSet);
// Call the predefined result set to beautify the utility class and print the result set
System.out.println("Printing result set...");
ResultFormat.printResultSet(resultSet);
} catch (SQLException e) {
e.printStackTrace();
}finally {
// Release Hive JDBC source
HiveUtil.releaseSource(resultSet,statement,connection);
}

查询记录代码。程序中将调用封装好的类获取 JDBC 连接,使用 JDBC 连接创建 Statement 执行查询 SQL 语句,并将查询结果集打印至控制台。所有数据操作执行完毕后将释放 JDBC 资源。
// Get Hive JDBC connection
Connection connection = HiveUtil.getConnection();
// Initialize Statement
Statement statement = null;
// Initialize ResultSet
ResultSet resultSet = null;
try {
// Create Statement
statement = connection.createStatement();
// Query the records of mapping table
String queryResultSet = "SELECT * FROM " + tableName;
// Execute the SQL statement of query mapping table record to get result set
resultSet = statement.executeQuery(queryResultSet);
// Call the predefined result set to beautify the utility class and print the result set
ResultFormat.printResultSet(resultSet);
} catch (SQLException e) {
e.printStackTrace();
} finally {
// Release Hive JDBC source
HiveUtil.releaseSource(resultSet, statement, connection);
}
插入单条记录代码。程序中将调用封装好的类获取 JDBC 连接,使用 JDBC 连接创建 Statement 执行插入记录 SQL 语句,并调用前文中定义的查询方法将查询结果集打印至控制台展示插入记录结果。所有数据操作执行完毕后将释放 JDBC 资源。
// Get Hive JDBC connection
Connection connection = HiveUtil.getConnection();
// Initialize Statement
Statement statement = null;
try {
// Create Statement
statement = connection.createStatement();
// Insert a single record
String insert = "INSERT INTO department VALUES (10,'Business Department')";
// Execute the SQL statement of insert a single record
statement.executeUpdate(insert);
// Call the query method to print the current department table result set
getAll("department");
} catch (SQLException e) {
e.printStackTrace();
} finally {
// Release Hive JDBC source
HiveUtil.releaseSource(null, statement, connection);
}
批量插入记录代码。程序会调用封装好的类初始化批量插入记录的目标集合 new_department。程序中将调用封装好的类获取 JDBC 连接,使用 JDBC 连接创建 Statement,通过 Statement 先执行创建映射表 SQL 语句,之后通过 Statement 执行批量插入记录 SQL 语句,将 department 表中数据插入到 new_department 表中,并调用前文中定义的查询方法将查询结果集打印至控制台展示批量插入结果。所有数据操作执行完毕后将释放 JDBC 资源。
// Call a predefined utility class to create a new_department collection in SequoiaDB
SdbUtil.initCollection("sample", "new_department");
// Get Hive JDBC connection
Connection connection = HiveUtil.getConnection();
// Initialize Statement
Statement statement = null;
try {
// Create Statement
statement = connection.createStatement();
// Drop the existing new_department mapping table
String dropTable = "DROP TABLE IF EXISTS new_department";
// Execute the SQL statement of drop mapping table
statement.execute(dropTable);
// Create new_department mapping table
String mapping =
"CREATE TABLE new_department(" +
"d_id int," +
"department string" +
") USING com.sequoiadb.spark " +
"OPTIONS( " +
"host 'sdbserver1:11810', " +
"collectionspace 'sample', " +
"collection 'new_department' " +
")";
// Execute the SQL statement of create mapping table
statement.execute(mapping);
// Bulk insert data from department table into new_department table
String bulkInsert =
"INSERT INTO new_department SELECT * FROM department";
// Execute the SQL statement of bulk insert
statement.executeUpdate(bulkInsert);
// Call the query method to print the current new_department table result set
getAll("new_department");
} catch (SQLException e) {
e.printStackTrace();
} finally {
// Release Hive JDBC source
HiveUtil.releaseSource(null, statement, connection);
}
实验 5
关联聚合操作
关联查询
关联查询代码。程序中将调用封装好的类获取 JDBC 连接,使用 JDBC 连接创建 Statement 执行关联查询 SQL 语句,并将查询结果集打印至控制台。所有数据操作执行完毕后将释放 JDBC 资源。
// Get Hive JDBC connection
Connection connection = HiveUtil.getConnection();
// Initialize Statement
Statement statement = null;
// Initialize ResultSet
ResultSet resultSet = null;
try {
// Create Statement
statement = connection.createStatement();
// joinQuery
String joinQuery =
"SELECT s.id,d.department,s.position,s.salary " +
"FROM " +
"department d,salary s " +
"WHERE s.department = d.d_id";
// Execute the SQL statement of joinQuery
resultSet = statement.executeQuery(joinQuery);
// Call the predefined result set to beautify the utility class and print the result set
ResultFormat.printResultSet(resultSet);
} catch (SQLException e) {
e.printStackTrace();
} finally {
// Release Hive JDBC source
HiveUtil.releaseSource(resultSet, statement, connection);
}
当前实验步骤中将通过 CREATE TABLE AS SELECT 的方式在 Spark SQL 中创建映射表写入聚合查询结果,以此来将聚合查询的结果生成为统计表。这种方式创建映射表会在 SequoiaDB 中自动创建指定的映射集合。集合查询内容为计算各个部门的人均工资并统计人数。
聚合查询生成统计表代码。程序中将调用封装好的类获取 JDBC 连接,使用 JDBC 连接创建 Statement 执行聚合查询建表 SQL 语句,并将查询结果集打印至控制台。所有数据操作执行完毕后将释放 JDBC 资源。
// Get Hive JDBC connection
Connection connection = HiveUtil.getConnection();
// Initialize Statement
Statement statement = null;
// Initialize ResultSet
ResultSet resultSet = null;
try {
// Create Statement
statement = connection.createStatement();
// Drop the existing table
String dropStatistic = "DROP TABLE IF EXISTS statistic";
// Execute the SQL statement of drop table
statement.execute(dropStatistic);
// Generate statistical tables of aggregate query results in SparkSQL using CTAS
String aggregate =
"CREATE TABLE statistic USING com.sequoiadb.spark " +
"OPTIONS( " +
"host 'sdbserver1:11810', " +
"collectionspace 'sample', " +
"collection 'statistic' " +
")AS( " +
"SELECT d.d_id,d.department,avg_table.salary_avg,avg_table.employee_num " +
"FROM( " +
"SELECT s.department as department_id,avg(s.salary) AS salary_avg,count(1) AS employee_num " +
"FROM employee e,salary s " +
"WHERE e.position = s.id " +
"GROUP BY s.department " +
")AS avg_table " +
"LEFT JOIN department d " +
"ON avg_table.department_id = d.d_id)";
// Execute the SQL statement to generate statistics table
statement.execute(aggregate);
// Query statistic
String queryStatistic = "SELECT * FROM statistic";
// Execute the SQL statement of query statistic table
resultSet = statement.executeQuery(queryStatistic);
// Call the predefined result set to beautify the utility class and print the result set
ResultFormat.printResultSet(resultSet);
} catch (SQLException e) {
e.printStackTrace();
} finally {
// Release Hive JDBC source
HiveUtil.releaseSource(resultSet, statement, connection);
}
实验 6
Spark RDD 应用开发
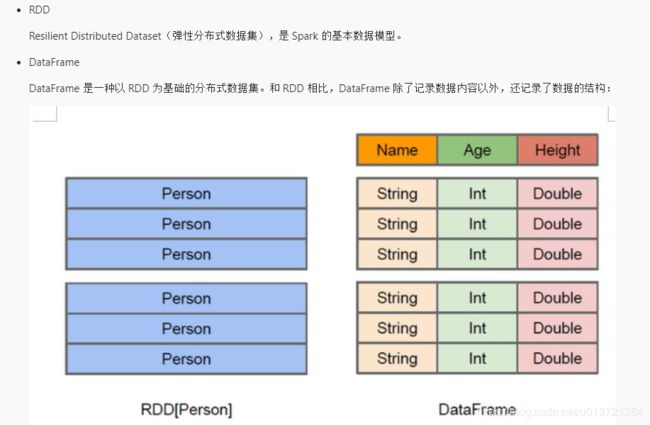
因此,Spark 在使用 DataFrame 时可以根据数据的 Schema 信息进行针对性的优化,提高运行效率
DataSet:
DataFrame 也可以叫 Dataset[Row] ,每一行的类型是 Row,不进行解析。而 Dataset 中,每一行是什么类型是不一定的。
创建 SparkSession 代码。SparkSession 为 Spark SQL DataSet API 的入口。在创建 SparkSession 时需要指定 master(当前实验环境中 Spark 为单机部署故设置为 local)、appName(自定义 app 名)、以及有关的 config(sequoiadb.host 为必须配置,指定为 SequoiaDB 的主机名和协调节点名)。
// Create SparkSession
sparkSession = SparkSession.builder()
.master("local[*]") // Specify master: local [*] means using available threads for calculation
.appName("word count") // Specify the app name
.config("spark.driver.allowMultipleContexts", true) // Configuration allows multiple SparkContext
.config("sequoiadb.host", "sdbserver1:11810") // Configure the host used by Spark to access SequoiaDB
.getOrCreate()
通过 RDD 统计单词数代码。程序中将文件读取为 RDD,经过 map、reduceby 等操作转化成新的保存有单词个数统计信息的 RDD。运行程序后会将最终 RDD 打印到控制台。
// Read RDD from file
var wordsRDD = sparkSession.sparkContext.textFile("src/main/resources/txt/words.txt")
// Convert RDD to key-value pair; key is word and value is 1
val wordsPairRDD = wordsRDD.map(f => (f, 1))
// Combine elements with the same key name in wordsPairRDD
wordsCountPair = wordsPairRDD.reduceByKey(_ + _)
将 RDD 写入 SequoiaDB 代码。程序中将获取上一实验步骤中保存有单词数信息的 RDD,将其转换成适合 SequoiaDB 存储的 BSON 类型格式后,调用 SequoiaDB 的 Spark 连接驱动中的方法将 BSON 类型的 RDD 写入到 SequoiaDB 的集合中。运行程序时会调用封装好的方法打印 SequoiaDB 集合中的数据。
// Convert RDD into a format that suitable for SequoiaDB storage (BSON)
var wordsCountBSON = wordsCountPair.map(f => {
var record: BSONObject = new BasicBSONObject()// Create BSONObject
.append("word", f._1.asInstanceOf[String])// Add word information to BSONObject
.append("count", f._2)// Add the number of words to BSONObject
record// Return record
})
// Write converted RDD to SequoiaDB
wordsCountBSON.saveToSequoiadb(
"sdbserver1:11810", // Specify the coord node
"sample", // Specify collection space
"wordcount"// Specify collection
)
读取 SequoiaDB 集合为 RDD 代码。程序中调用 SequoiaDB 的 Spark 连接驱动中的方法读取 SequoiaDB 集合为 RDD,并指定集合中需要的字段将其转换成新的 RDD。运行程序时将最终 RDD 到控制台。
// Read data from SequoiaDB to RDD
val sdbRDD = sparkSession.sparkContext.loadFromSequoiadb(
"sample", // Collection space
"wordcount"// Collection
)
// Reassemble the word and count information in RDD into a new RDD
sdbPairRDD = sdbRDD.map(f => (f.get("word"), f.get("count")))
实验 7
Spark Streaming 应用开发
Spark Streaming 持续统计端口输入的单词数
通过 Spark Streaming 统计指定端口输入单词数的程序代码。程序中将创建 StreamingContext 监听 sdbserver1 的 6789 端口,每间隔 10 秒收集一次时间段内端口输入的单词数生成 JavaDStream(相当于一个每次统计单词数的 RDD 的集合),和实验 6 中 RDD 的转化类似,可以将 JavaDStream 通过 map、reduce 等操作转化成最终的 JavaPairDStream(相当于保存有单词统计信息键值对 RDD 的集合)。程序运行期间会持续监听 6789 端口,持续打印 10 时间间隔内端口输入的单词数。
// Configure master and appname of spark
// Master must be local [n], n> 1, indicating that one thread receives data and n-1 threads process data
// local [*] means using available threads to process data
SparkConf sparkConf = new SparkConf().setMaster("local[*]").setAppName("streaming word count");
// Create sparkcontext
JavaSparkContext javaSparkContext = new JavaSparkContext(sparkConf);
// Create streamingcontext
// Durations are the time intervals calculated for the stream
JavaStreamingContext javaStreamingContext = new JavaStreamingContext(javaSparkContext, Durations.seconds(10));
// Creating stream gets the specified port input (nc -lk 6789) through socket.
JavaReceiverInputDStream<String> lines =
javaStreamingContext.socketTextStream("sdbserver1", 6789);
// Create matching style specified as spaces
Pattern SPACE = Pattern.compile(" ");
// Divide each line of the port input into words according to the Pattern
JavaDStream<String> words = lines.flatMap(x -> Arrays.asList(SPACE.split(x)).iterator());
// Words are converted into key-value pairs (key: words, value: 1) for merging easily.
JavaPairDStream<String, Integer> pairs = words.mapToPair(s -> new Tuple2<>(s, 1));
// Merge the same word count
JavaPairDStream<String, Integer> wordCounts = pairs.reduceByKey((i1, i2) -> i1 + i2);
// Print statistics (within 10 seconds) to the console
wordCounts.print();
try {
// Start the stream computing
javaStreamingContext.start();
// Wait for the end
javaStreamingContext.awaitTermination();
} catch (InterruptedException e) {
e.printStackTrace();
}