Hadoop之MapReduce编程模型
一、MapReduce编程模型
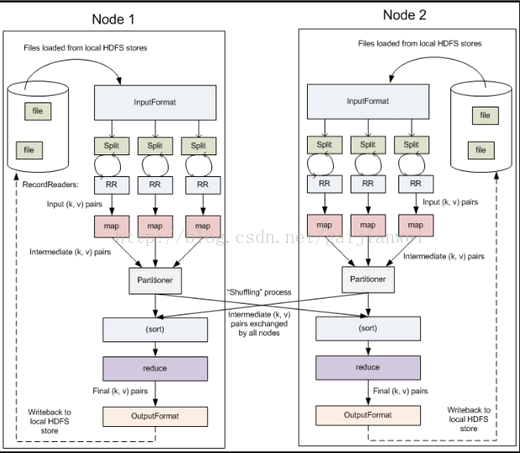
MapReduce将作业的整个运行过程分为两个阶段:Map阶段和Reduce阶段
Map阶段由一定数量的Map Task组成
输入数据格式解析:InputFormat
输入数据处理:Mapper
数据分组:Partitioner
Reduce阶段由一定数量的Reduce Task组成
数据远程拷贝
数据按照key排序
数据处理:Reducer
数据输出格式:OutputFormat
二、MapReduce工作原理图

三、MapReduce编程模型—内部逻辑

四、MapReduce编程模型—外部物理结构
五、MapReduce编程模型—InputFormat
5.1 InputFormat API

5.2 InputFormat 负责处理MR的输入部分.
有三个作用:
1验证作业的输入是否规范.
2把输入文件切分成InputSplit. (处理跨行问题)
3提供RecordReader 的实现类,把InputSplit读到Mapper中进行处理.
5.3 InputFormat类的层次结构

六、MapReduce编程模型—Split与Block
6.1 Split与Block简介
Block: HDFS中最小的数据存储单位,默认是64MB
Spit: MapReduce中最小的计算单元,默认与Block一一对应
Block与Split: Split与Block是对应关系是任意的,可由用户控制.
6.2 InputSplit
在执行mapreduce之前,原始数据被分割成若干split,每个split作为一个map任务的输入,在map执行过程中split会被分解成一个个记录(key-value对),map会依次处理每一个记录。
1.FileInputFormat只划分比HDFS block大的文件,所以FileInputFormat划分的结果是这个文件或者是这个文件中的一部分.
2.如果一个文件的大小比block小,将不会被划分,这也是Hadoop处理大文件的效率要比处理很多小文件的效率高的原因。
3. 当Hadoop处理很多小文件(文件大小小于hdfs block大小)的时候,由于FileInputFormat不会对小文件进行划分,所以每一个小文件都会被当做一个split并分配一个map任务,导致效率底下。例如:一个1G的文件,会被划分成16个64MB的split,并分配16个map任务处理,而10000个100kb的文件会被10000个map任务处理。
七、TextInputFormat
1.TextInputformat是默认的处理类,处理普通文本文件。
2.文件中每一行作为一个记录,他将每一行在文件中的起始偏移量作为key,每一行的内容作为value。
3.默认以\n或回车键作为一行记录。
4.TextInputFormat继承了FileInputFormat。
八、其他输入类
◆ CombineFileInputFormat
相对于大量的小文件来说,hadoop更合适处理少量的大文件。
CombineFileInputFormat可以缓解这个问题,它是针对小文件而设计的。
◆ KeyValueTextInputFormat
当输入数据的每一行是两列,并用tab分离的形式的时候,KeyValueTextInputformat处理这种格式的文件非常适合。
◆ NLineInputformat
NLineInputformat可以控制在每个split中数据的行数。
◆ SequenceFileInputformat
当输入文件格式是sequencefile的时候,要使用SequenceFileInputformat作为输入。
九、自定义输入格式
1)继承FileInputFormat基类。
2)重写里面的getSplits(JobContext context)方法。
3)重写createRecordReader(InputSplit split,TaskAttemptContext context)方法。
【研究下源代码】
十、MapReduce编程模型—Combiner

1 每一个map可能会产生大量的输出,combiner的作用就是在map端对输出先做一次合并,以减少传输到reducer的数据量。
2 combiner最基本是实现本地key的归并,combiner具有类似本地的reduce功能,合并相同的key对应的value(wordcount例子),通常与Reducer逻辑一样。
3 如果不用combiner,那么,所有的结果都是reduce完成,效率会相对低下。使用combiner,先完成的map会在本地聚合,提升速度。
好处:①减少Map Task输出数据量(磁盘IO)②减少Reduce-Map网络传输数据量(网络IO)
【注意:Combiner的输出是Reducer的输入,如果Combiner是可插拔(可有可无)的,添加Combiner绝不能改变最终的计算结果。所以Combiner只应该用于那种Reduce的输入key/value与输出key/value类型完全一致,且不影响最终结果的场景。比如累加,最大值等。】
十一、MapReduce编程模型—Partitioner
1.Partitioner决定了Map Task输出的每条数据交给哪个Reduce Task处理
2.默认实现:HashPartitioner是mapreduce的默认partitioner。计算方法是 reducer=(key.hashCode() & Integer.MAX_VALUE) % numReduceTasks,得到当前的目的reducer。(hash(key) mod R 其中R是Reduce Task数目)
3.允许用户自定义
很多情况需自定义Partitioner比如“hash(hostname(URL)) mod R”确保相同域名的网页交给同一个Reduce Task处理
十二、Reduce的输出
◆ TextOutputformat
默认的输出格式,key和value中间值用tab隔开的。
◆ SequenceFileOutputformat
将key和value以sequencefile格式输出。
◆ SequenceFileAsOutputFormat
将key和value以原始二进制的格式输出。
◆ MapFileOutputFormat
将key和value写入MapFile中。由于MapFile中的key是有序的,所以写入的时候必须保证记录是按key值顺序写入的。
◆ MultipleOutputFormat
默认情况下一个reducer会产生一个输出,但是有些时候我们想一个reducer产生多个输出,MultipleOutputFormat和MultipleOutputs可以实现这个功能。(还可以自定义输出格式,序列化会说到)
十三、MapReduce编程模型总结
1.Map阶段
InputFormat(默认TextInputFormat)
Mapper
Combiner(local reducer)
Partitioner
2.Reduce阶段
Reducer
OutputFormat(默认TextOutputFormat)