MySQL索引使用的数据结构:B-Tree和B+Tree
MyISAM是MySQL 5.5之前版本默认的存储引擎,从5.5之后,InnoDB开始成为MySQL默认的存储引擎。
MyISAM使用B-Tree实现主键索引、唯一索引和非主键索引。
InnoDB中非主键索引使用的是B-Tree数据结构,而主键索引使用的是B+Tree。
本文就是对这两种数据结构做简单的介绍。
1. Hash索引
Hash 索引结构的特殊性,其检索效率非常高,索引的检索可以一次定位,不像B-Tree 索引需要从根节点到枝节点,最后才能访问到页节点这样多次的IO访问,所以 Hash 索引的查询效率要远高于 B-Tree 索引。
可能很多人又有疑问了,既然 Hash 索引的效率要比 B-Tree 高很多,为什么大家不都用 Hash 索引而还要使用 B-Tree 索引呢?任何事物都是有两面性的,Hash 索引也一样,虽然 Hash 索引效率高,但是 Hash 索引本身由于其特殊性也带来了很多限制和弊端,主要有以下这些。
(1)Hash 索引仅仅能满足"=","IN"和"<=>"查询,不能使用范围查询。
由于 Hash 索引比较的是进行 Hash 运算之后的 Hash 值,所以它只能用于等值的过滤,不能用于基于范围的过滤,因为经过相应的 Hash 算法处理之后的 Hash值的大小关系,并不能保证和Hash运算前完全一样。(2)Hash 索引无法被用来避免数据的排序操作。
由于 Hash 索引中存放的是经过 Hash 计算之后的 Hash 值,而且Hash值的大小关系并不一定和 Hash 运算前的键值完全一样,所以数据库无法利用索引的数据来避免任何排序运算;(3)Hash 索引不能利用部分索引键查询。
对于组合索引,Hash 索引在计算 Hash 值的时候是组合索引键合并后再一起计算 Hash 值,而不是单独计算 Hash 值,所以通过组合索引的前面一个或几个索引键进行查询的时候,Hash 索引也无法被利用。(4)Hash 索引在任何时候都不能避免表扫描。
前面已经知道,Hash 索引是将索引键通过 Hash 运算之后,将 Hash运算结果的 Hash 值和所对应的行指针信息存放于一个 Hash 表中,由于不同索引键存在相同 Hash 值,所以即使取满足某个 Hash 键值的数据的记录条数,也无法从 Hash 索引中直接完成查询,还是要通过访问表中的实际数据进行相应的比较,并得到相应的结果。(5)Hash 索引遇到大量Hash值相等的情况后性能并不一定就会比B-Tree索引高。
对于选择性比较低的索引键,如果创建 Hash 索引,那么将会存在大量记录指针信息存于同一个 Hash 值相关联。这样要定位某一条记录时就会非常麻烦,会浪费多次表数据的访问,而造成整体性能低下。
2. B-Tree
B-Tree不是“B减树”,而是“B树”。
这里参考了严蔚敏《数据结构》对B-Tree的定义:
一棵m阶的B-Tree,或者为空树,或者满足下列特性:
1.树中每个结点至多有m棵子树;
2.若根结点不是叶子结点,则至少有两棵子树;
3.除根节点之外的所有非终端结点至少有[m/2]棵子树;
4.所有非终端结点中包含下列信息数据:
(n,A0,K1,A1,K2,A2……Kn,An)
其中,n为关键字的数目,K(i)为关键字,且K(i) < K(i+1), Ai为指向子树根结点的指针,且指针A(i-1)所指子树中所有结点的关键字均小于Ki,Ai所指子树中所有结点的关键字均大于Ki;
5.所有叶子结点都出现在同一层次上;
下面通过一个例子解释一下B-Tree的查找过程。 
这是一棵4阶的B-Tree,深度为4。
假如在该图中查找关键字47,首先从根结点开始,根据根结点指针t找到*a结点,因为47大于 *a 结点的关键字35,所以会去A1指针指向的 *c结点继续寻找,因为 *c的关键字 43 < 要查找的47 < *c结点的关键字78,所以去 *c结点A1指针指向的 *g结点去寻找,结果在 *g结点中找到了关键字47,查找成功。
3. B+Tree
不同的存储引擎可能使用不同的数据结构存储,InnoDB使用的是B+Tree;那什么是B+Tree呢?
B+Tree是应文件系统所需而出的一种B-Tree的变型树,一棵m阶的B+树和m阶的B-树的差异在于:
1.有n棵子树的结点中含有n个关键字;
2.所有的叶子结点中包含了全部关键字的信息,及指向含这些关键字的记录的指针,且叶子结点本身依关键字的大小自小而大顺序链接;
3.所有的非终端结点可以看成是索引部分,结点中仅含有其子树(根结点)中的最大(或最小)关键字;
还是通过一个例子来说明。 
这个例子中,所有非终端结点仅含有子树中最大的关键字。
因为叶子节点本身依据关键字的大小自小而大顺序链接,所以可以从最小关键字起顺序查找。也可以从根结点开始,进行随机查找。
在B+树中随机差找和在B-树中类似,以上图为例。假设要查找关键字51,现在根节点中比较,发现51<59,因为这里使用的是非终端结点的关键字是子树中最大的关键字,所以进入最大值为59的子结点(15\44\59)中查找,同理,因为44<51<59,所以进入P3指向的结点(51\59)中查找,然后命中关键字51,因为此结点(51\59)是叶子结点,所以查找终止,该结点包含指向数据的指针。
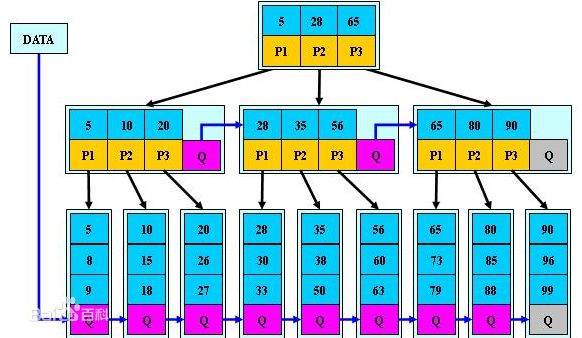
3.索引如何在B+Tree中组织数据存储
假设有如下表: 
对于表中的每一行数据,索引中包含了last_name、first_name和dob列的值,下图展示索引是如何组织数据存储的: 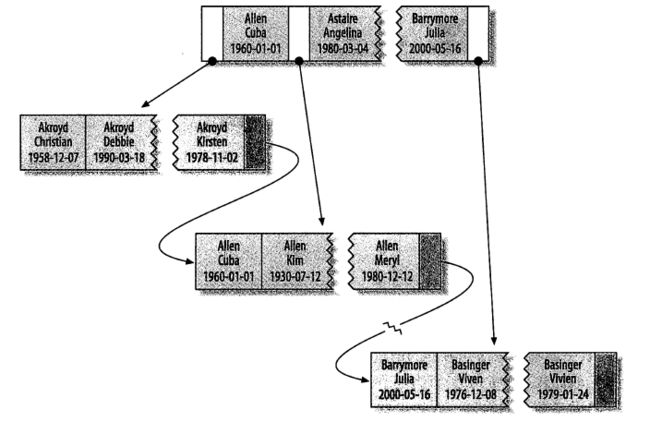
索引对多个值进行排序的依据是定义索引时列的顺序。
(Allen Cuba 1960-01-01)结点左侧的指针指向[?,Allen Cuba 1960-01-01)的叶子页,(Allen Cuba 1960-01-01)和(Astaire,Angelina,1980-03-04)之间的指针指向[Allen Cuba 1960-01-01,Astaire Angelina 1980-03-04)的叶子页,以此类推。总之,每个指针指向的结点中的最小值就是该指针左侧的的值。
这种存储结构也说明了在定义多个列组成的多列索引中,为什么需要把重复率最低的列放到最左侧,因为这会减少比较的次数,查找起来更加高效。
4.索引为什么选用B树这种数据结构?
因为使用B树查找时,所用的磁盘IO操作次数比平衡二叉树更少,效率也更高。
为什么使用B树查找所用的磁盘IO操作次数比平衡二叉树更少?
大规模数据存储中,树节点存储的元素数量是有限的(如果元素数量非常多的话,查找就退化成节点内部的线性查找了),这样导致二叉查找树结构由于树的高度过大而造成磁盘I/O读写过于频繁,进而导致查询效率低下。那么我们就需要减少树的高度以提高查找效率。而平衡多路查找树结构B树就满足这样的要求。B树的各种操作能使B树保持较低的高度,从而达到有效减少磁盘IO操作次数。