JML简介及相关工具链使用
1.JML规格描述语言介绍
本单元学习的内容是JML规格描述语言。我们知道,面向对象方法是一个抽象过程,需求者仅需关注方法的规格。规格是对一个方法/类/程序的外部可感知行为(语义)的抽象表示,内部细节无需在规格中表示 , 同时需保证规格实现的无二义性。JML规格描述语言使用javadoc注释的方式,为严格的程序设计提供了一套行之有效的方法。
JML每行都以@起头。有两种注释方式,行注释和块注释。其中行注释的表示方式为 //@annotation ,块注释的方式为 /* @ annotation @*/ 。方法规格的核心内容包括三个方面,前置条件、后置条件和副作用约定。其中前置条件是对方法输入参数的限制, 如果不满足前置条件,方法执行结果不可预测,或者说不保证方法执行结果的正确性;后置条件是对方法执行结果的限制,如果执行结果满足后置条件,则表示方法执行正确,否则执行错误。副作用指方法 在执行过程中对指定的对象进行了修改(对其成员变量进行了赋值,或者调用其修改方法)。每个条件中由若干不可分割的原子表达式组成,而其中原子表达式最重要的是谓词以及量词的使用,这样可以使得规格得到无二义的形式化表述。如下表格中给出了本单元作业中涉及到的JML的基本术语使用。
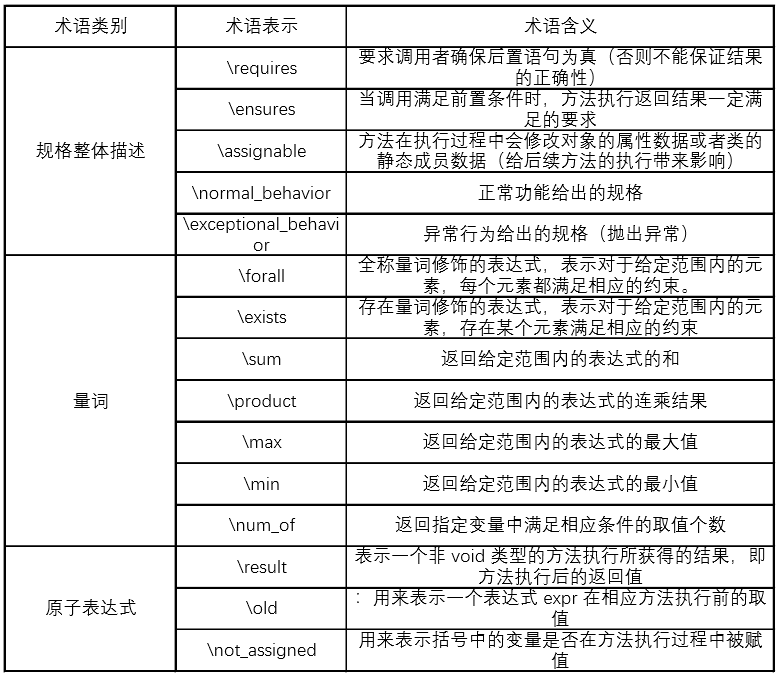
当然,JML术语还有很多,由于本单元并未涉及,故在此不作介绍。
2.openJML的使用
openJML是一款检查JML语法的工具,可以检查常见JML中的语法错误。由于在本地idea中配置该插件一直出现问题,因此只能尝试从命令行中使用该工具。经过一番资料查询及环境变量配置后,该包终于能够成功运行。但是当我用其检查作业中的Network类时,让我意外的是报出了很多莫名奇妙的错误,经过询问后才知道原来该插件对很多高级表达(例如\forall)均不支持。因此我在本地编写了一个极其其简单的类,并尝试自己编写一段jml,并使用该工具检查,如图:
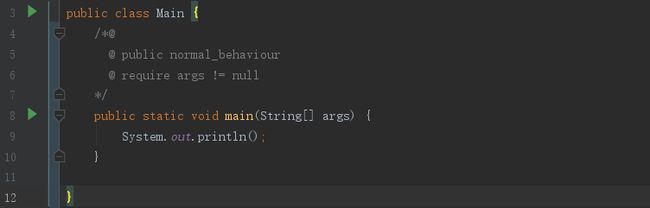
在使用网上的教程,在命令行进行了一些我自己都看不懂的操作后,检测出了结果:

从反馈结果可以看出,编写的JML少了一个分号,并且\requires写成了require。
总体来说,openJML的应用很局限(至少对我来说),对复杂一些的JML报错信息很难看懂,还不如肉眼检查,这可能是由于openJML工具多年未维护所致。
3.JMLunitNG自动生成测试数据
按照课程组给出的链接,下载JMLunitNG包并更新jdk后,编写简单方法,并在命令行使用如下命令,得到生成的测试数据(实际上命令我并不能看懂):
java -jar jmlunitng-1_4.jar test/Main.java java -jar openjml.jar -rac test/Main.java javac -cp jmlunitng-1_4.jar test/Main_JML_Test.java java -cp jmlunitng-1_4.jar test.Main_JML_Test


从生成的数据可以看出,几乎所有的数据都落在了Integer.MAX_VALUE、Integer.MIN_VALUE、0等数据上,基本没有普遍性,覆盖范围很小,在实际使用时,很难靠该数据检测出bug。
总之,这两个工具使用的体验并不好,第一是我对工具链的使用不够熟练,只会在命令行中运行;第二可能是因为工具本身比较小众,长时间未维护,导致用户体验不是很友好(第二个工具甚至不能在高版本的jdk上使用),实际使用是可能人工生成数据的效率更高。
作业设计分析
本单元的作业是设计实现支持多种功能的社交网络接口(Network),同时实现基本成员Person、Group接口。绝大多数方法已经给出规格,按照约定,只要实现规格描述就能实现需求,因此本单元的作业不需要特别注重的架构,关键是方法的正确实现。由于大体架构由课程组给出,因此本次作业的架构就不再列出,以下分析主要概括对关键成员及方法的分析。
1.第一次作业
本次作业没有特别难的方法,主要是让我们熟悉JML,以及采用合理的容器。一个稍微难一点的方法是isCircle,用于查询两人的社交关系是否可达,用BFS或DFS即可实现。容器选择主要是在ArrayList和Hashmap中选择(这里解释一下,由于经常涉及从容器中间取元素,以及从尾部增删元素,使用LinkedList的效率低于ArrayList)。ArrayList在存储和遍历操作时较有优势,同时空间开销小;HashMap则在获取某一元素时效率较高。但需要注意的是,由于HashMap底层实现比ArrayList复杂,方法调用较多,因此当容量较小时,ArrayList在大多数操作上都是有优势的。对于Person的acquiantance,由测试数据的addRelation条数限制可知每个人的熟人数量不会太多,因此采用ArrayList保存;对于Network,由于总人数较多,并且经常需要遍历操作,因此同时使用HashMap和ArrayList(牺牲一定的空间换取效率)。
该次作业没有难以读懂的规格,但有不少细节需要注意,我在addRelation方法时就栽了坑,由于分类情况较多,并且每个情况有一定的交集(如id1 == id2时,getPerson(id1).isLinked(getPerson(id2))返回值为真),同时满足两种情况(这在JML中是允许的),但我没有注意判断的顺序,导致出现了很大的bug。
2.第二次作业
第二次作业相比第一次作业跨度很小,主要增加了Group类以及相应的方法。一个Group中人数不会太多,因此使用ArrayList保存组内人员。本次作业的重点是在于时间复杂度的控制。该次作业有getRelationSum和getValueSum操作,而这两项操作的描述在规格中是用二重循环给出的。需要注意的是,规格描述并不指定方法实现的过程,因此在设计时需要关注方法的性能。如果采用规格给出的二重循环操作进行遍历,那么在强测时会导致TLE。因此本次作业我在Group中加入缓冲变量,接受到相应操作时进行修改,询问的时间复杂度为O(1)。
使用缓冲机制有一定的弊端,就是必须周全的考虑到所有可能改变变量值的操作并执行更新,而我在设计时就少考虑一种情况导致在一种特定的情况下会出现Bug。
3.第三次作业
第三次作业在第二次作业的基础上,增加了一些较为复杂的方法(最短路径、连通块的个数、双连通分量)。本次作业难点就在于这些方法的实现,需要用到图论以及数据结构的知识。之前学的最短路径都是用Dijskra算法,而本次作业我尝试使用了Floyd算法(最终结果表明,这是一大败笔)。连通块的个数我采用缓冲机制实现,效果比较理想。双连通分量我开始采用Tarjan算法,但后来发现有bug并且迟迟不能发现,因此最终重写,采用寻找环的方法(这也是一大败笔)。本次作业还有一个需要注意的点就是由于有了距离矩阵,iscircle的判断只需判断距离是否为无穷大即可,不需要额外的计算。
本次作业的另一大难点是读懂规格。与前两次作业相比,第三次作业规格的复杂度显著提升,直接读会有些困难,但是好在有一个现成的提示——方法名。通过方法名来辅助理解JML是完成本次作业的一个重要手段。这也提示我们在书写规格时,一个恰当的方法名可以让方法实现者更好地理解规格。(相比于java单词组合的命名规则,之前学的C语言单词简写+下划线的命名手段理解起来简直是噩梦)
总的来说,三次作业是层层递进的,但每次作业的侧重点不同,跨度比较合理。
评测结果及bug分析
如上所说,第一次作业由于其中一个方法分支判断的失误,在id1 == id2时应该直接return,但我却抛出了pinf,而该方法又经常使用,导致我强测最终炸穿,只过了两个点,互测都没进。(第一次这么惨,嘤嘤嘤)
第二次作业本身难度不大,并且我吸取了前一次的教训,积极使用Junit单元测试,并且使用自动生成测试数据程序,和其他人的程序输出结果进行对拍,因此强测结果比较好,虽然最终在互测中被发现一个小bug,但影响不大,很容易修复。
第三次作业,由于我采用了时间复杂度为O(n^3)的Floyd算法,并且没有很好的优化,导致部分数据点因为最短路径TLE,修复时改用堆优化的Dijskra算法很快就过了。。另一大败笔就是采用了时间复杂度高达O(n!)的判断双连通分量的算法,导致部分数据因queryStrongLink TLE。后来经过提醒,即使不用Tarjan算法,采用“删点遍历”的方式也完全能够实现时间复杂度O(n^2)。这表明了我对数据结构的知识掌握不牢,同时不能很好的设计算法。不过好在我所在的互测屋叫C屋,屋里的人个个都有bug,我通过hack他们挽回了一些分数。
总结
本单元掌握的最重要的知识就是规格描述语言,以及对方法采用形式化验证。Junit是我掌握的一项重要工具,在今后的设计中应当经常使用它。JML语言目前虽然应用不是很广泛,但是我掌握了形式化描述规格方法的过程。在设计新的需求时,可以采用本单元的方法,先给出接口以及方法的规格,再想办法去实现,这样非常有利于迭代和扩展。我在之前的设计中,往往不会完整地提前设计好架构,而是机械地逐个实现方法,这样既不利于扩展,也容易设计失败,从一开始就误入歧途。这是本单元给我的最大收获。