2019独角兽企业重金招聘Python工程师标准>>> 
简介ELK
需求背景
业务发展越来越庞大,服务器越来越多
各种访问日志、应用日志、错误日志量越来越多
开发人员排查问题,需要到服务器上查日志,不方便
运营人员需要一些数据,需要我们运维到服务器上分析日志
说白了就是日志那么多我要给你们搞牛逼的系统
如果有机会再搞日志系统加消息列队es+kafka消化来的数据
ELK包含ElasticSearch、Logstash、Kibana(不过这早都是过去式了现在加入很多新东西)
-
ElasticSearch是一个搜索引擎,用来搜索、分析、存储日志。它是分布式的,也就是说可以横向扩容,可以自动发现,索引自动分片,总之很强大。(这个可以做集群哟一个主节点剩下的全是数据节点,数据节点啊当然是存储数据咯)
文档https://www.elastic.co/guide/cn/elasticsearch/guide/current/index.html
-
Logstash用来采集日志,把日志解析为json格式交给ElasticSearch。
-
Kibana是一个数据可视化组件,把处理后的结果通过web界面展示
-
Beats在这里是一个轻量级日志采集器,其实Beats家族有5个成员(重点说一下这次项目最后采集日志的前端采用Beats后导入kafka再进入logstash和es及kibana成图)
早期的ELK架构中使用Logstash收集、解析日志,但是Logstash对内存、cpu、io等资源消耗比较高。相比 Logstash,Beats所占系统的CPU和内存几乎可以忽略不计
x-pack对Elastic Stack提供了安全、警报、监控、报表、图表于一身的扩展包,是收费的

再贴一下相关内容:消息列队
消息队列中间件是分布式系统中重要的组件,主要解决应用耦合,异步消息,流量削锋等问题。实现高性能,高可用,可伸缩和最终一致性架构。是大型分布式系统不可缺少的中间件。
目前在生产环境,使用较多的消息队列有ActiveMQ,RabbitMQ,ZeroMQ,Kafka,MetaMQ,RocketMQ等。
这里重点说一下后期我们要加入的kafka来解决日志处理相关问题:
日志处理是指将消息队列用在日志处理中,比如Kafka的应用,解决大量日志传输的问题
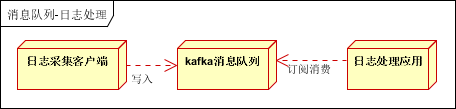
- 日志采集客户端,负责日志数据采集,定时写受写入Kafka队列;
- Kafka消息队列,负责日志数据的接收,存储和转发;
- 日志处理应用:订阅并消费kafka队列中的日志数据;
以下是新浪kafka日志处理应用案例(这个很经典的):
转自(http://cloud.51cto.com/art/201507/484338.htm)
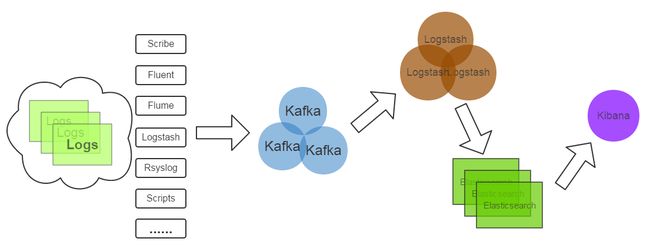
(1)Kafka:接收用户日志的消息队列。
(2)Logstash:做日志解析,统一成JSON输出给Elasticsearch。
(3)Elasticsearch:实时日志分析服务的核心技术,一个schemaless,实时的数据存储服务,通过index组织数据,兼具强大的搜索和统计功能。
(4)Kibana:基于Elasticsearch的数据可视化组件,超强的数据可视化能力是众多公司选择ELK stack的重要原因。
这里强调一下kafka+es可实现的功能远大于此,kafka的功能后期一定要涉足无线期待
进入正题
角色划分搞三台机器
130安装es+kibana+jdk1.8(主节点上安装可视化组件来搞web展示界面)
132安装es+logstash+jdk1.8(这个数据节点上用来采集日志)
133安装es+jdk1.8(这个上只有es用来存储数据,后面安装beats)
好了打断一下先说说今天出现的问题,安装要聊的还长
jdk安装,测试了老半天yum安装的open-jdk还是靠谱,自己官网下载rz过来的因为变量PATH无法识别/var/log/messages次次报错,搞成open-jdk就解决了没有办法后期需要再深究
附上jdk安装命令:yum install -y java-1.8.0-openjdk
项目中搞Elasticsearch时出现的问题使期始终无法启动,浪费一下午时间研究log才意识到是启动后ps aux可以看到进程后几秒又没了,但是相对应的日志已经生产,思来想去考虑了内存等一系列问题在度娘那也搜了很多解决方案,都算是学习吧,因为。。。因为是自己粗心把配置信息加错了,结果天天跑log里面跟字迹过不去,以后一定用心哇,老哥以后拜托了周末一下午啊心疼。。。