步骤
- 词法分析
- 语法分析
- 语义分析与中间代码产生
- 优化
- 目标代码生成
文法
- 3型文法:正则文法,用于描述程序设计语言词法的有效工具
- 2型文法:上下型无关文法,描述程序语法的有效工具
产生式
A -> B
B -> BC|C
C -> 0|1|2|3|4|5|6|7|8|9
推导与规约
A -> aBc
B -> b
==================
aBc是abc的归约
abc是aBc的推导
规范推导/规约
规范推导:最右推导
规范规约:最左规约
无符号串
=》数字串
=》数字串+数字
=》数字串6
=》数字6
=》56
句型
由产生式到最终状态之间的中间串
例如<数字>9
句子
产生式最终匹配的终态
例如56是文法无符号整数的一个句子
词法分析
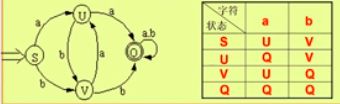
有限自动机
DFA
确定有限自动机:每个状态在接收下一个输入,只会转移到唯一一个下一个状态
L(M):代表由FA能够识别的所有字符串的总体
NFA
非确定有限自动机,自动机中含有某些状态,在接收下一个输入后,会转移到多于一个的状态

NFA确定化
每个NFA都存在一个DFA,使得L(NFA) = L(DFA),也就是说等价
NFA的确定化就是,从NFA转变为DFA的过程
- c-closure(state):c-闭包,从一个状态转移不需要通过输入可以直接转移到下一个状态的集合
- move(state, action):从状态state,通过action,转换到的下一个状态的集合
- a弧转换的闭包:I = c-closure(move(state, action))
子集构造法

然后把I列表标记为状态,并画出DFA
在NFA->DFA后,得到的DFA并不是最简的,必须通过DFA最简化处理,来提高分析的效率
DFA最简化
- 多余状态:从开始状态出发无法到达的状态
- 死状态:从此状态出发无法到达最终状态的状态
- 无关状态:多余状态+死状态
- 等价状态(不可区别状态):当两个状态,输入任意action,都转移到相同的状态时,代表这两个状态是等价的。
简化步骤为:
- 消除无关状态
- 合并等价状态
正则与NFA的转换
R->NFA
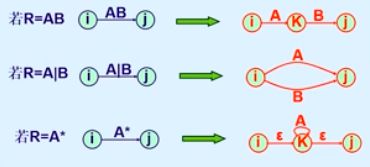
例子

NFA-R
逆过程
语法分析
自顶向下语法分析
消除左递归
直接左递归
P->Pa|b => ba+
P ->bM
M -> aM|空
间接左递归
A -> Bc|d
B -> aA|Ab
=>
A -> aAc|Abc|d
=>
A -> (aAc|d)M
M -> bcM|空
First集
若X->a....则a加入X的First集中,如果X->空,则空加入到X的First集中
X->amm|bk|空
=> First(X) = {a,b,空}
X->Ym|b
Y->a|d|空
=> First(X) = {a, d, m, b}
Follow集
- 若A->aBC,则First(C)加入Follow(B)
- 若A->aB,则Follow(A)加入Follow(B)
LL(1)语法分析

L:从左向由扫描
L:最左推导
1:向前看1个字符
对文法G的句子进行确定的自顶向下语法分析的充要条件是
产生式A->B|C满足
- 如果B和C都不能推导出空,则FIrst(B)交First(C)为空集
- B和C最多只有一个可以推导出空
- 如果B可以推导出空,则First(C)交Follow(A为空
LL(1)文法不能由二义性,也不能含有左递归,对LL(1)文法的所有句子都可以进行自顶向下的语法分析
并不是所有语言都可以用LL(1)来描述
自下而上的语法分析
FirstVT(T)
非终结符T的最左终结符集合
- If T->a or T->Ra => a属于FirstVt(T)
- if b belongs to FirstVt(R) => b and T->R... 属于FirstVt(T)
LastVt(T)
非终结符T的最右终结符集合
- if T->....a or T->....aR => a属于LastVt(T)
- if b belongs to LastVt(R) and T->...R => b属于LastVt(T)
最左素语

- 建立一个栈
- 从左到右扫描表达式
- 通过出栈比较相邻两个个操作符的优先级
- 如果如果两个操作符优先级相等或者前一个后一个优先级高则规约前一个操作符
- 出栈比较相邻两个操作符
- 如果第一个操作符比第二个操作符低,则再取一个操作符,如果第二个操作符等于或者高于第三个操作符,则规约第二个操作符,否则继续入栈
产生式->NFA
E->aA|bB
A->cA|d
B->cB|d
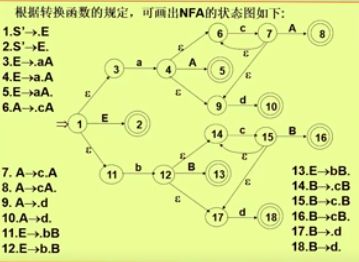
NFA->DFA
通过子集构造法
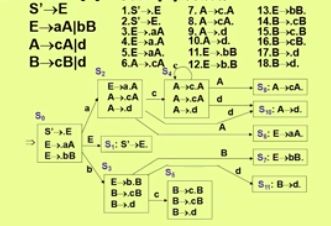
LR(0)语法分析
- 移进项目:圆点之后为终结符的项目,A->a.bc
- 待约项目:圆点之后为非终结符,A->a.Bb
- 归约项目:圆点之后没有远点,A->a.
- 接受项目:对于文法G(S),有S->Q.
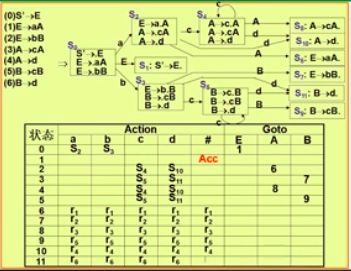
通过从左向右扫描句子,通过下一输入,决定从Si归约到Sj,并最终到达终态
SLR(1)语法分析
LR(0)文法,如果遇到在一个状态中,同时出现移进和规约的冲突,则会让LR(0)无法判断此步骤应该如何处理

S3状态,已经满足归约条件,则无论下一个字符是什么,都需要进行归约操作;但是如果下一个字符是‘,’,则应该i进行移进操作
SLR(1)为了解决移进归约冲突,则遇到冲突时向前看一个字符,来解决冲突
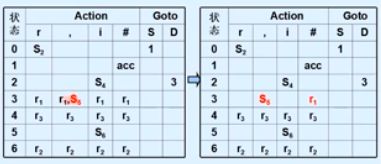
LR(1)语法分析

当某个状态遇到移进归约冲突,并且下一个移进的符号,与归约符号的下一个符号相同,则无法使用SLR(1)进行分析
SLR(1)通过Follow(A)来计算,而LR(1)通过First(A.next)来决定来缩小范围

LR(1)过程:
- 如果A->a.BM, B->r,m=First(M),则记为B->r,m
中间代码
优点
- 编译程序的逻辑结构更加简单明确
- 利于再不同的目标机器上实现同一种语言
- 利于进行与机器无关的优化
- 可以用于解析
形式
- 后缀式
- 图表示:抽象语法树/DAG图
- 三地址代码:三元式/四元式/间接三元式
后缀式
a+b*(c-d)+e/(c-d)
=>
abcd-*+ecd-/+
抽象语法树
内部节点代表操作符,叶子节点为操作数

DAG图
把抽象语法树的公共部分进行合并,可以减少公共表达式的计算
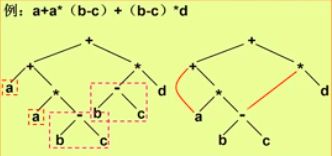
三地址码
可以看作抽象语法树或者DAG的一种线性表示

三地址码详解
四元式
特点
- 占用空间多
- 易于优化
result = arg1 op arg2
=>
(op, arg1 arg2, result)
三元式
特点
- 占用空间少
- 由于临时变量跟i紧密关联,导致难以优化
result = arg1 op arg2
=>
(i) (op, arg1, arg2)
用i位置来保存临时结果
左值与右值
x[i]=y =>
(0) ([]=, x, i)
(1) (assign, (0), y)
y=x[i] =>
(0) (=[], x, i)
(1) (assign, y, (0))
间接三元式
特点
- 占用空间多
- 易于优化

数组翻译
LOC(A[i]) = base + (i-low)*w
= (base-low*w) + i*w
= conspart + varpart
Loc(A[i][j]) = base + ((i-low1)*n2+j-low)*w
= (base-(low1*n2+low2)*w)+(i*n2+j)*w
可见任意维度的数组元素的计算都可以分为不变计算和可变计算组成,在编译时首先计算出conspart,可以达到优化的目的
条件语句的翻译
文法
S -> if(E) S1|if(E) S1 else S2

拉链回填
对于E.true的未来地址,在三地址码中,先通过打标志的方式,在后续确定下地址后,再回填到标志的位置
循环语句的翻译
文法
S -> while(E) S1

符号表

存储
变长字段通过指针链接到另外的内存区存储
查找
线性查找
通过顺序查找
自适应线性表:通过新增一列,通过LRU算法,构成链表,最新访问的元素会出现在链头
二叉树
建立树索引
hash
建立hash索引
名字作用域

嵌套结构的符号表特征
- 由于函数的执行是先执行,后结束,所以适合用栈的方式来存储
- 在函数对应的符号表中指定display表,代表此函数可用符号表的首地址
- 在符号表中引入指针previous,来连接上一个符号的首地址
运行时存储空间组织

活动记录
用于管理函数变量的信息
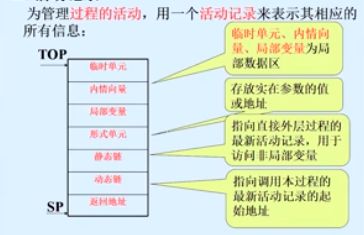
栈式存储
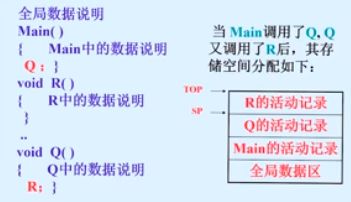
过程进入和返回
通过变更top和sp指针,实现活动记录的栈式处理
静态链实现局部变量的访问

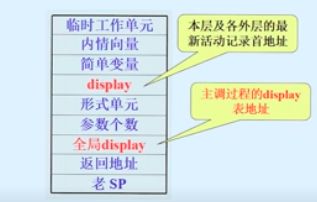
静态链
指向直接外层函数的首地址
动态链
指向上一层函数的首地址
display表
所有外层函数的首地址
优化
局部优化
基于基本块范围内的优化
- 删除公共子表达式
- 删除无用代码
- 合并已知变量
- 交换语句位置
- 代数变换/强度削弱
DAG优化
- 三地址码转换为DAG

2. DAG重写三地址码

3. 删除无用变量

循环优化
代码外提
- 求出循环L的所有不变运算
- 检查步骤1的不变运算A=const是否满足:
- s是否是L的所有出口必经节点,或者A在离开L后不再活跃
- A在L的其他地方没有再赋值
- 对S涉及的A的引用都是在此A赋值后才到达
- 对满足以上条件的A=const进行外提
强度消弱
- 对于循环L有I = I+C,且有T=K*I+C2,其中C,K,C2为不变量,则T可以进行强度削弱,把乘法转换为加法
- 削弱后,循环中会出现无用赋值,可删除
- 下标变量的地址计算很耗时,可以使用强度削弱
删除归纳变量
对于循环变量i,由于L中有其他变量A是跟I有线性关系的,可以用A来代替i在循环的控制,以减少对循环变量的计算