Ribbon 是netflix 公司开源的基于客户端的负载均衡组件,是Spring Cloud大家庭中非常重要的一个模块;Ribbon应该也是整个大家庭中相对而言比较复杂的模块,直接影响到服务调度的质量和性能。全面掌握Ribbon可以帮助我们了解在分布式微服务集群工作模式下,服务调度应该考虑到的每个环节。
本文将详细地剖析Ribbon的设计原理,帮助大家对Spring Cloud 有一个更好的认知。
一. Spring集成下的Ribbon工作结构
先贴一张总览图,说明一下Spring如何集成Ribbon的,如下所示:

Spring Cloud集成模式下的Ribbon有以下几个特征:
- Ribbon 服务配置方式
每一个服务配置都有一个Spring ApplicationContext上下文,用于加载各自服务的实例。
比如,当前Spring Cloud 系统内,有如下几个服务:
| 服务名称 | 角色 | 依赖服务 |
|---|---|---|
order |
订单模块 | user |
user |
用户模块 | 无 |
mobile-bff |
移动端BFF | order,user |
mobile-bff服务在实际使用中,会用到order和user模块,那么在mobile-bff服务的Spring上下文中,会为order 和user 分别创建一个子ApplicationContext,用于加载各自服务模块的配置。也就是说,各个客户端的配置相互独立,彼此不收影响
- 和Feign的集成模式
在使用Feign作为客户端时,最终请求会转发成http://<服务名称>/的格式,通过LoadBalancerFeignClient, 提取出服务标识<服务名称>,然后根据服务名称在上下文中查找对应服务的负载均衡器FeignLoadBalancer,负载均衡器负责根据既有的服务实例的统计信息,挑选出最合适的服务实例
二、Spring Cloud模式下和Feign的集成实现方式
和Feign结合的场景下,Feign的调用会被包装成调用请求LoadBalancerCommand,然后底层通过Rxjava基于事件的编码风格,发送请求;Spring Cloud框架通过 Feigin 请求的URL,提取出服务名称,然后在上下文中找到对应服务的的负载均衡器实现FeignLoadBalancer,然后通过负载均衡器中挑选一个合适的Server实例,然后将调用请求转发到该Server实例上,完成调用,在此过程中,记录对应Server实例的调用统计信息。
/**
* Create an {@link Observable} that once subscribed execute network call asynchronously with a server chosen by load balancer.
* If there are any errors that are indicated as retriable by the {@link RetryHandler}, they will be consumed internally by the
* function and will not be observed by the {@link Observer} subscribed to the returned {@link Observable}. If number of retries has
* exceeds the maximal allowed, a final error will be emitted by the returned {@link Observable}. Otherwise, the first successful
* result during execution and retries will be emitted.
*/
public Observable submit(final ServerOperation operation) {
final ExecutionInfoContext context = new ExecutionInfoContext();
if (listenerInvoker != null) {
try {
listenerInvoker.onExecutionStart();
} catch (AbortExecutionException e) {
return Observable.error(e);
}
}
// 同一Server最大尝试次数
final int maxRetrysSame = retryHandler.getMaxRetriesOnSameServer();
//下一Server最大尝试次数
final int maxRetrysNext = retryHandler.getMaxRetriesOnNextServer();
// Use the load balancer
// 使用负载均衡器,挑选出合适的Server,然后执行Server请求,将请求的数据和行为整合到ServerStats中
Observable o =
(server == null ? selectServer() : Observable.just(server))
.concatMap(new Func1>() {
@Override
// Called for each server being selected
public Observable call(Server server) {
// 获取Server的统计值
context.setServer(server);
final ServerStats stats = loadBalancerContext.getServerStats(server);
// Called for each attempt and retry 服务调用
Observable o = Observable
.just(server)
.concatMap(new Func1>() {
@Override
public Observable call(final Server server) {
context.incAttemptCount();//重试计数
loadBalancerContext.noteOpenConnection(stats);//链接统计
if (listenerInvoker != null) {
try {
listenerInvoker.onStartWithServer(context.toExecutionInfo());
} catch (AbortExecutionException e) {
return Observable.error(e);
}
}
//执行监控器,记录执行时间
final Stopwatch tracer = loadBalancerContext.getExecuteTracer().start();
//找到合适的server后,开始执行请求
//底层调用有结果后,做消息处理
return operation.call(server).doOnEach(new Observer() {
private T entity;
@Override
public void onCompleted() {
recordStats(tracer, stats, entity, null);
// 记录统计信息
}
@Override
public void onError(Throwable e) {
recordStats(tracer, stats, null, e);//记录异常信息
logger.debug("Got error {} when executed on server {}", e, server);
if (listenerInvoker != null) {
listenerInvoker.onExceptionWithServer(e, context.toExecutionInfo());
}
}
@Override
public void onNext(T entity) {
this.entity = entity;//返回结果值
if (listenerInvoker != null) {
listenerInvoker.onExecutionSuccess(entity, context.toExecutionInfo());
}
}
private void recordStats(Stopwatch tracer, ServerStats stats, Object entity, Throwable exception) {
tracer.stop();//结束计时
//标记请求结束,更新统计信息
loadBalancerContext.noteRequestCompletion(stats, entity, exception, tracer.getDuration(TimeUnit.MILLISECONDS), retryHandler);
}
});
}
});
//如果失败,根据重试策略触发重试逻辑
// 使用observable 做重试逻辑,根据predicate 做逻辑判断,这里做
if (maxRetrysSame > 0)
o = o.retry(retryPolicy(maxRetrysSame, true));
return o;
}
});
// next请求处理,基于重试器操作
if (maxRetrysNext > 0 && server == null)
o = o.retry(retryPolicy(maxRetrysNext, false));
return o.onErrorResumeNext(new Func1>() {
@Override
public Observable call(Throwable e) {
if (context.getAttemptCount() > 0) {
if (maxRetrysNext > 0 && context.getServerAttemptCount() == (maxRetrysNext + 1)) {
e = new ClientException(ClientException.ErrorType.NUMBEROF_RETRIES_NEXTSERVER_EXCEEDED,
"Number of retries on next server exceeded max " + maxRetrysNext
+ " retries, while making a call for: " + context.getServer(), e);
}
else if (maxRetrysSame > 0 && context.getAttemptCount() == (maxRetrysSame + 1)) {
e = new ClientException(ClientException.ErrorType.NUMBEROF_RETRIES_EXEEDED,
"Number of retries exceeded max " + maxRetrysSame
+ " retries, while making a call for: " + context.getServer(), e);
}
}
if (listenerInvoker != null) {
listenerInvoker.onExecutionFailed(e, context.toFinalExecutionInfo());
}
return Observable.error(e);
}
});
}
从一组ServerList 列表中挑选合适的Server
/**
* Compute the final URI from a partial URI in the request. The following steps are performed:
*
* - 如果host尚未指定,则从负载均衡器中选定 host/port
*
- 如果host 尚未指定并且尚未找到负载均衡器,则尝试从 虚拟地址中确定host/port
*
- 如果指定了HOST,并且URI的授权部分通过虚拟地址设置,并且存在负载均衡器,则通过负载就均衡器中确定host/port(指定的HOST将会被忽略)
*
- 如果host已指定,但是尚未指定负载均衡器和虚拟地址配置,则使用真实地址作为host
*
- if host is missing but none of the above applies, throws ClientException
*
*
* @param original Original URI passed from caller
*/
public Server getServerFromLoadBalancer(@Nullable URI original, @Nullable Object loadBalancerKey) throws ClientException {
String host = null;
int port = -1;
if (original != null) {
host = original.getHost();
}
if (original != null) {
Pair schemeAndPort = deriveSchemeAndPortFromPartialUri(original);
port = schemeAndPort.second();
}
// Various Supported Cases
// The loadbalancer to use and the instances it has is based on how it was registered
// In each of these cases, the client might come in using Full Url or Partial URL
ILoadBalancer lb = getLoadBalancer();
if (host == null) {
// 提供部分URI,缺少HOST情况下
// well we have to just get the right instances from lb - or we fall back
if (lb != null){
Server svc = lb.chooseServer(loadBalancerKey);// 使用负载均衡器选择Server
if (svc == null){
throw new ClientException(ClientException.ErrorType.GENERAL,
"Load balancer does not have available server for client: "
+ clientName);
}
//通过负载均衡器选择的结果中选择host
host = svc.getHost();
if (host == null){
throw new ClientException(ClientException.ErrorType.GENERAL,
"Invalid Server for :" + svc);
}
logger.debug("{} using LB returned Server: {} for request {}", new Object[]{clientName, svc, original});
return svc;
} else {
// No Full URL - and we dont have a LoadBalancer registered to
// obtain a server
// if we have a vipAddress that came with the registration, we
// can use that else we
// bail out
// 通过虚拟地址配置解析出host配置返回
if (vipAddresses != null && vipAddresses.contains(",")) {
throw new ClientException(
ClientException.ErrorType.GENERAL,
"Method is invoked for client " + clientName + " with partial URI of ("
+ original
+ ") with no load balancer configured."
+ " Also, there are multiple vipAddresses and hence no vip address can be chosen"
+ " to complete this partial uri");
} else if (vipAddresses != null) {
try {
Pair hostAndPort = deriveHostAndPortFromVipAddress(vipAddresses);
host = hostAndPort.first();
port = hostAndPort.second();
} catch (URISyntaxException e) {
throw new ClientException(
ClientException.ErrorType.GENERAL,
"Method is invoked for client " + clientName + " with partial URI of ("
+ original
+ ") with no load balancer configured. "
+ " Also, the configured/registered vipAddress is unparseable (to determine host and port)");
}
} else {
throw new ClientException(
ClientException.ErrorType.GENERAL,
this.clientName
+ " has no LoadBalancer registered and passed in a partial URL request (with no host:port)."
+ " Also has no vipAddress registered");
}
}
} else {
// Full URL Case URL中指定了全地址,可能是虚拟地址或者是hostAndPort
// This could either be a vipAddress or a hostAndPort or a real DNS
// if vipAddress or hostAndPort, we just have to consult the loadbalancer
// but if it does not return a server, we should just proceed anyways
// and assume its a DNS
// For restClients registered using a vipAddress AND executing a request
// by passing in the full URL (including host and port), we should only
// consult lb IFF the URL passed is registered as vipAddress in Discovery
boolean shouldInterpretAsVip = false;
if (lb != null) {
shouldInterpretAsVip = isVipRecognized(original.getAuthority());
}
if (shouldInterpretAsVip) {
Server svc = lb.chooseServer(loadBalancerKey);
if (svc != null){
host = svc.getHost();
if (host == null){
throw new ClientException(ClientException.ErrorType.GENERAL,
"Invalid Server for :" + svc);
}
logger.debug("using LB returned Server: {} for request: {}", svc, original);
return svc;
} else {
// just fall back as real DNS
logger.debug("{}:{} assumed to be a valid VIP address or exists in the DNS", host, port);
}
} else {
// consult LB to obtain vipAddress backed instance given full URL
//Full URL execute request - where url!=vipAddress
logger.debug("Using full URL passed in by caller (not using load balancer): {}", original);
}
}
// end of creating final URL
if (host == null){
throw new ClientException(ClientException.ErrorType.GENERAL,"Request contains no HOST to talk to");
}
// just verify that at this point we have a full URL
return new Server(host, port);
}
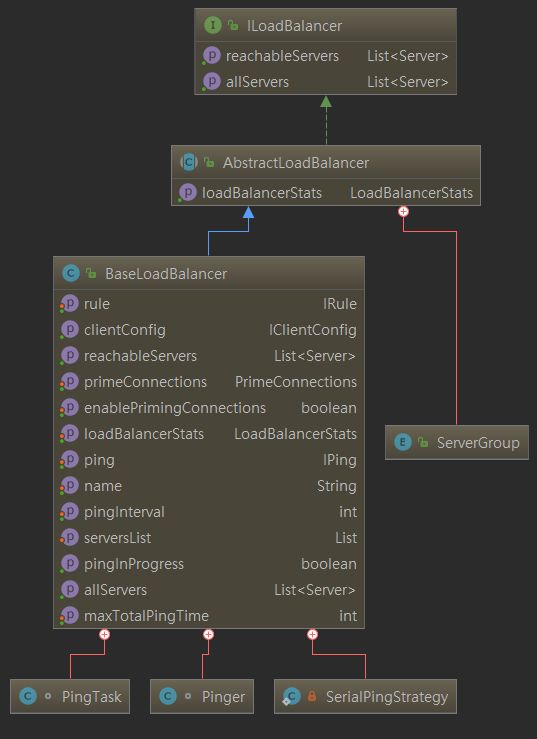
三. LoadBalancer--负载均衡器的核心
LoadBalancer 的职能主要有三个:
- 维护Sever列表的数量(新增、更新、删除等)
- 维护Server列表的状态(状态更新)
- 当请求Server实例时,能否返回最合适的Server实例
本章节将通过详细阐述着这三个方面。
3.1 负载均衡器的内部基本实现原理
先熟悉一下负载均衡器LoadBalancer的实现原理图:
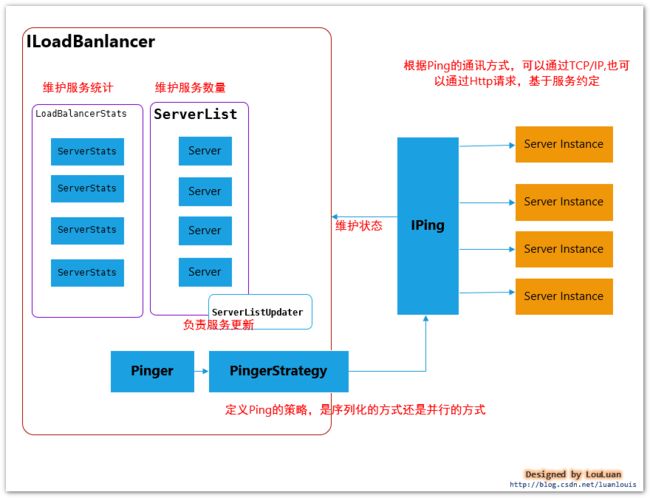
| 组成部分 | 职能 | 参考章节 |
|---|---|---|
| Server | Server 作为服务实例的表示,会记录服务实例的相关信息,如:服务地址,所属zone,服务名称,实例ID等 |
|
| ServerList | 维护着一组Server实例列表,在应用运行的过程中,Ribbon通过ServerList中的服务实例供负载均衡器选择。ServerList维护列表可能在运行的过程中动态改变 |
3.2 |
| ServerStats | 作为对应Server 的运行情况统计,一般是服务调用过程中的Server平均响应时间,累计请求失败计数,熔断时间控制等。一个ServerStats实例唯一对应一个Server实例 |
|
| LoadBalancerStats | 作为 ServerStats实例列表的容器,统一维护 |
|
| ServerListUpdater | 负载均衡器通过ServerListUpdater来更新ServerList,比如实现一个定时任务,每隔一段时间获取最新的Server实例列表 |
3.2 |
| Pinger | 服务状态检验器,负责维护ServerList列表中的服务状态注意:Pinger仅仅负责Server的状态,没有能力决定是否删除 |
|
| PingerStrategy | 定义以何种方式还检验服务是否有效,比如是按照顺序的方式还是并行的方式 | |
| IPing | Ping,检验服务是否可用的方法,常见的是通过HTTP,或者TCP/IP的方式看服务有无认为正常的请求 |
3.2 如何维护Server列表?(新增、更新、删除)
单从服务列表的维护角度上,Ribbon的结构如下所示:

Server列表的维护从实现方法上分为两类:
- 基于配置的服务列表
这种方式一般是通过配置文件,静态地配置服务器列表,这种方式相对而言比较简单,但并不是意味着在机器运行的时候就一直不变。netflix在做Spring cloud 套件时,使用了分布式配置框架netflix archaius,archaius框架有一个特点是会动态的监控配置文件的变化,将变化刷新到各个应用上。也就是说,当我们在不关闭服务的情况下,如果修改了基于配置的服务列表时, 服务列表可以直接刷新- 结合服务发现组件(如
Eureka)的服务注册信息动态维护服务列表
基于Spring Cloud框架下,服务注册和发现是一个分布式服务集群必不可少的一个组件,它负责维护不同的服务实例(注册、续约、取消注册),本文将介绍和Eureka集成模式下,如果借助Eureka的服务注册信息动态刷新ribbon的服务列表
Ribbon 通过配置项:
| 策略 | ServerList实现 |
|---|---|
| 基于配置 | com.netflix.loadbalancer.ConfigurationBasedServerList |
| 基于服务发现 | com.netflix.loadbalancer.DiscoveryEnabledNIWSServerList |
Server列表可能在运行的时候动态的更新,而具体的更新方式由
| 更新策略 | ServerListUpdater实现 |
|---|---|
| 基于定时任务的拉取服务列表 | com.netflix.loadbalancer.PollingServerListUpdater |
| 基于Eureka服务事件通知的方式更新 | com.netflix.loadbalancer.EurekaNotificationServerListUpdater |
- 基于定时任务拉取服务列表方式
这种方式的实现为:com.netflix.loadbalancer.PollingServerListUpdater,其内部维护了一个周期性的定时任务,拉取最新的服务列表,然后将最新的服务列表更新到ServerList之中,其核心的实现逻辑如下:
public class PollingServerListUpdater implements ServerListUpdater {
private static final Logger logger = LoggerFactory.getLogger(PollingServerListUpdater.class);
private static long LISTOFSERVERS_CACHE_UPDATE_DELAY = 1000; // msecs;
private static int LISTOFSERVERS_CACHE_REPEAT_INTERVAL = 30 * 1000; // msecs;
// 更新器线程池定义以及钩子设置
private static class LazyHolder {
private final static String CORE_THREAD = "DynamicServerListLoadBalancer.ThreadPoolSize";
private final static DynamicIntProperty poolSizeProp = new DynamicIntProperty(CORE_THREAD, 2);
private static Thread _shutdownThread;
static ScheduledThreadPoolExecutor _serverListRefreshExecutor = null;
static {
int coreSize = poolSizeProp.get();
ThreadFactory factory = (new ThreadFactoryBuilder())
.setNameFormat("PollingServerListUpdater-%d")
.setDaemon(true)
.build();
_serverListRefreshExecutor = new ScheduledThreadPoolExecutor(coreSize, factory);
poolSizeProp.addCallback(new Runnable() {
@Override
public void run() {
_serverListRefreshExecutor.setCorePoolSize(poolSizeProp.get());
}
});
_shutdownThread = new Thread(new Runnable() {
public void run() {
logger.info("Shutting down the Executor Pool for PollingServerListUpdater");
shutdownExecutorPool();
}
});
Runtime.getRuntime().addShutdownHook(_shutdownThread);
}
private static void shutdownExecutorPool() {
if (_serverListRefreshExecutor != null) {
_serverListRefreshExecutor.shutdown();
if (_shutdownThread != null) {
try {
Runtime.getRuntime().removeShutdownHook(_shutdownThread);
} catch (IllegalStateException ise) { // NOPMD
// this can happen if we're in the middle of a real
// shutdown,
// and that's 'ok'
}
}
}
}
}
// 省略部分代码
@Override
public synchronized void start(final UpdateAction updateAction) {
if (isActive.compareAndSet(false, true)) {
//创建定时任务,按照特定的实行周期执行更新操作
final Runnable wrapperRunnable = new Runnable() {
@Override
public void run() {
if (!isActive.get()) {
if (scheduledFuture != null) {
scheduledFuture.cancel(true);
}
return;
}
try {
//执行update操作 ,更新操作定义在LoadBalancer中
updateAction.doUpdate();
lastUpdated = System.currentTimeMillis();
} catch (Exception e) {
logger.warn("Failed one update cycle", e);
}
}
};
//定时任务创建
scheduledFuture = getRefreshExecutor().scheduleWithFixedDelay(
wrapperRunnable,
initialDelayMs, //初始延迟时间
refreshIntervalMs, //内部刷新时间
TimeUnit.MILLISECONDS
);
} else {
logger.info("Already active, no-op");
}
}
//省略部分代码
}
有上述代码可以看到,ServerListUpdator只是定义了更新的方式,而具体怎么更新,则是封装成UpdateAction来操作的:
/**
* an interface for the updateAction that actually executes a server list update
*/
public interface UpdateAction {
void doUpdate();
}
//在DynamicServerListLoadBalancer 中则实现了具体的操作:
public DynamicServerListLoadBalancer() {
this.isSecure = false;
this.useTunnel = false;
this.serverListUpdateInProgress = new AtomicBoolean(false);
this.updateAction = new UpdateAction() {
public void doUpdate() {
//更新服务列表
DynamicServerListLoadBalancer.this.updateListOfServers();
}
};
}
@VisibleForTesting
public void updateListOfServers() {
List servers = new ArrayList();
// 通过ServerList获取最新的服务列表
if (this.serverListImpl != null) {
servers = this.serverListImpl.getUpdatedListOfServers();
LOGGER.debug("List of Servers for {} obtained from Discovery client: {}", this.getIdentifier(), servers);
//返回的结果通过过滤器的方式进行过滤
if (this.filter != null) {
servers = this.filter.getFilteredListOfServers((List)servers);
LOGGER.debug("Filtered List of Servers for {} obtained from Discovery client: {}", this.getIdentifier(), servers);
}
}
//更新列表
this.updateAllServerList((List)servers);
}
protected void updateAllServerList(List ls) {
if (this.serverListUpdateInProgress.compareAndSet(false, true)) {
try {
Iterator var2 = ls.iterator();
while(var2.hasNext()) {
T s = (Server)var2.next();
s.setAlive(true);
}
this.setServersList(ls);
super.forceQuickPing();
} finally {
this.serverListUpdateInProgress.set(false);
}
}
}
- 基于Eureka服务事件通知的方式更新
基于Eureka的更新方式则有些不同, 当Eureka注册中心发生了Server服务注册信息变更时,会将消息通知发送到EurekaNotificationServerListUpdater上,然后此Updator触发刷新ServerList:
public class EurekaNotificationServerListUpdater implements ServerListUpdater {
//省略部分代码
@Override
public synchronized void start(final UpdateAction updateAction) {
if (isActive.compareAndSet(false, true)) {
//创建Eureka时间监听器,当Eureka发生改变后,将触发对应逻辑
this.updateListener = new EurekaEventListener() {
@Override
public void onEvent(EurekaEvent event) {
if (event instanceof CacheRefreshedEvent) {
//内部消息队列
if (!updateQueued.compareAndSet(false, true)) { // if an update is already queued
logger.info("an update action is already queued, returning as no-op");
return;
}
if (!refreshExecutor.isShutdown()) {
try {
//提交更新操作请求到消息队列中
refreshExecutor.submit(new Runnable() {
@Override
public void run() {
try {
updateAction.doUpdate(); // 执行真正的更新操作
lastUpdated.set(System.currentTimeMillis());
} catch (Exception e) {
logger.warn("Failed to update serverList", e);
} finally {
updateQueued.set(false);
}
}
}); // fire and forget
} catch (Exception e) {
logger.warn("Error submitting update task to executor, skipping one round of updates", e);
updateQueued.set(false); // if submit fails, need to reset updateQueued to false
}
}
else {
logger.debug("stopping EurekaNotificationServerListUpdater, as refreshExecutor has been shut down");
stop();
}
}
}
};
//EurekaClient 客户端实例
if (eurekaClient == null) {
eurekaClient = eurekaClientProvider.get();
}
//基于EeurekaClient注册事件监听器
if (eurekaClient != null) {
eurekaClient.registerEventListener(updateListener);
} else {
logger.error("Failed to register an updateListener to eureka client, eureka client is null");
throw new IllegalStateException("Failed to start the updater, unable to register the update listener due to eureka client being null.");
}
} else {
logger.info("Update listener already registered, no-op");
}
}
}
3.2.1 相关的配置项
| 配置项 | 说明 | 生效场景 | 默认值 |
|---|---|---|---|
|
ServerList的实现,实现参考上述描述 |
ConfigurationBasedServerList |
|
|
服务列表 hostname:port 形式,以逗号隔开 | 当ServerList实现基于配置时 |
|
|
服务列表更新策略实现,参考上述描述 | PollingServerListUpdater |
|
|
服务列表刷新频率 | 基于定时任务拉取时 | 30s |
3.2.2 ribbon的默认实现
ribbon在默认情况下,会采用如下的配置项,即,采用基于配置的服务列表维护,基于定时任务按时拉取服务列表的方式,频率为30s.
.ribbon.NIWSServerListClassName=com.netflix.loadbalancer.ConfigurationBasedServerList
.ribbon.listOfServers=,
.ribbon.ServerListUpdaterClassName=com.netflix.loadbalancer.EurekaNotificationServerListUpdater
.ribbon.ServerListRefreshInterval=30
### 更新线程池大小
DynamicServerListLoadBalancer.ThreadPoolSize=2
3.2.3 Spring Cloud集成下的配置
ribbon在默认情况下,会采用如下的配置项,即,采用基于配置的服务列表维护,基于定时任务按时拉取服务列表的方式,频率为30s.
.ribbon.NIWSServerListClassName=com.netflix.loadbalancer.DiscoveryEnabledNIWSServerList
.ribbon.ServerListUpdaterClassName=com.netflix.loadbalancer.EurekaNotificationServerListUpdater
### 更新线程池大小
EurekaNotificationServerListUpdater.ThreadPoolSize=2
###通知队列接收大小
EurekaNotificationServerListUpdater.queueSize=1000
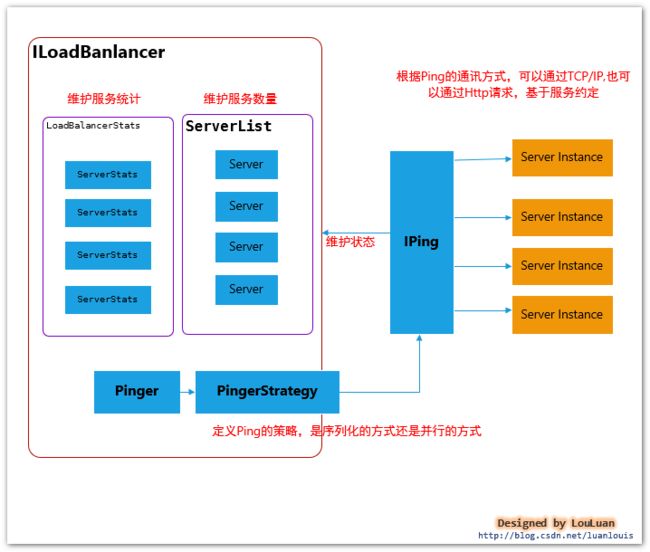
3.3 负载均衡器如何维护服务实例的状态?
Ribbon负载均衡器将服务实例的状态维护托交给Pinger、 PingerStrategy、IPing 来维护,具体交互模式如下所示:

/**
* 定义Ping服务状态是否有效的策略,是序列化顺序Ping,还是并行的方式Ping,在此过程中,应当保证相互不受影响
*
*/
public interface IPingStrategy {
boolean[] pingServers(IPing ping, Server[] servers);
}
/**
* 定义如何Ping一个服务,确保是否有效
* @author stonse
*
*/
public interface IPing {
/**
* Checks whether the given Server is "alive" i.e. should be
* considered a candidate while loadbalancing
* 校验是否存活
*/
public boolean isAlive(Server server);
}
3.3.1 创建Ping定时任务
默认情况下,负载均衡器内部会创建一个周期性定时任务
| 控制参数 | 说明 | 默认值 |
|---|---|---|
| Ping定时任务周期 | 30 s | |
| Ping超时时间 | 2s | |
| IPing实现类 | DummyPing,直接返回true |
默认的PingStrategy,采用序列化的实现方式,依次检查服务实例是否可用:
/**
* Default implementation for IPingStrategy , performs ping
* serially, which may not be desirable, if your IPing
* implementation is slow, or you have large number of servers.
*/
private static class SerialPingStrategy implements IPingStrategy {
@Override
public boolean[] pingServers(IPing ping, Server[] servers) {
int numCandidates = servers.length;
boolean[] results = new boolean[numCandidates];
logger.debug("LoadBalancer: PingTask executing [{}] servers configured", numCandidates);
for (int i = 0; i < numCandidates; i++) {
results[i] = false; /* Default answer is DEAD. */
try {
// 按序列依次检查服务是否正常,并返回对应的数组表示
if (ping != null) {
results[i] = ping.isAlive(servers[i]);
}
} catch (Exception e) {
logger.error("Exception while pinging Server: '{}'", servers[i], e);
}
}
return results;
}
}
3.3.2 Ribbon默认的IPing实现:DummyPing
默认的IPing实现,直接返回为true:
public class DummyPing extends AbstractLoadBalancerPing {
public DummyPing() {
}
public boolean isAlive(Server server) {
return true;
}
@Override
public void initWithNiwsConfig(IClientConfig clientConfig) {
}
}
除此之外,IPing还有如下几种实现:
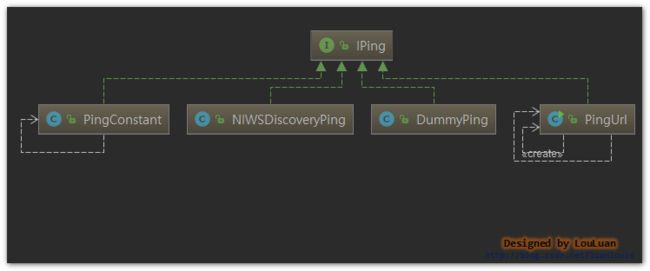
3.3.3 Spring Cloud集成下的IPing实现:NIWSDiscoveryPing
而和Spring Cloud 集成后,IPing的默认实现,是
NIWSDiscoveryPing,其使用Eureka作为服务注册和发现,则校验服务是否可用,则通过监听Eureka 服务更新来更新Ribbon的Server状态,而具体的实现就是NIWSDiscoveryPing:
/**
* "Ping" Discovery Client
* i.e. we dont do a real "ping". We just assume that the server is up if Discovery Client says so
* @author stonse
*
*/
public class NIWSDiscoveryPing extends AbstractLoadBalancerPing {
BaseLoadBalancer lb = null;
public NIWSDiscoveryPing() {
}
public BaseLoadBalancer getLb() {
return lb;
}
/**
* Non IPing interface method - only set this if you care about the "newServers Feature"
* @param lb
*/
public void setLb(BaseLoadBalancer lb) {
this.lb = lb;
}
public boolean isAlive(Server server) {
boolean isAlive = true;
//取 Eureka Server 的Instance实例状态作为Ribbon服务的状态
if (server!=null && server instanceof DiscoveryEnabledServer){
DiscoveryEnabledServer dServer = (DiscoveryEnabledServer)server;
InstanceInfo instanceInfo = dServer.getInstanceInfo();
if (instanceInfo!=null){
InstanceStatus status = instanceInfo.getStatus();
if (status!=null){
isAlive = status.equals(InstanceStatus.UP);
}
}
}
return isAlive;
}
@Override
public void initWithNiwsConfig(
IClientConfig clientConfig) {
}
}
Spring Cloud下的默认实现入口:
@Bean
@ConditionalOnMissingBean
public IPing ribbonPing(IClientConfig config) {
if (this.propertiesFactory.isSet(IPing.class, serviceId)) {
return this.propertiesFactory.get(IPing.class, config, serviceId);
}
NIWSDiscoveryPing ping = new NIWSDiscoveryPing();
ping.initWithNiwsConfig(config);
return ping;
}
3.4 如何从服务列表中挑选一个合适的服务实例?
3.4.1 服务实例容器:ServerList的维护
负载均衡器通过 ServerList来统一维护服务实例,具体模式如下:
基础的接口定义非常简单:
/**
* Interface that defines the methods sed to obtain the List of Servers
* @author stonse
*
* @param
*/
public interface ServerList {
//获取初始化的服务列表
public List getInitialListOfServers();
/**
* Return updated list of servers. This is called say every 30 secs
* (configurable) by the Loadbalancer's Ping cycle
* 获取更新后的的服务列表
*/
public List getUpdatedListOfServers();
}
在Ribbon的实现中,在ServerList中,维护着Server的实例,并返回最新的List集合,供LoadBalancer使用
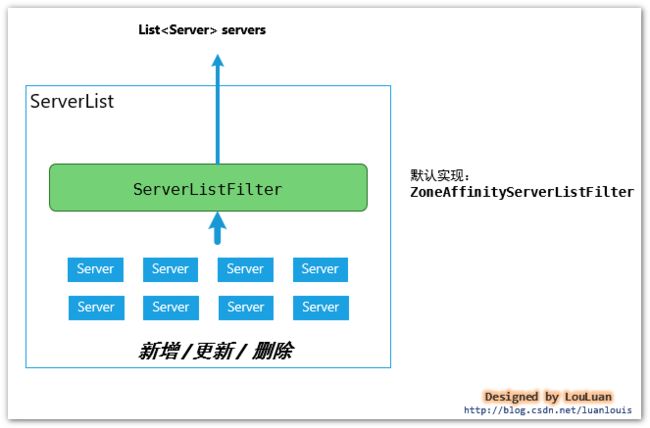
ServerList
的职能 :
负责维护服务实例,并使用ServerListFilter过滤器过滤出符合要求的服务实例列表List
3.4.2 服务实例列表过滤器ServerListFilter
服务实例列表过滤器
ServerListFilter的职能很简单:
传入一个服务实例列表,过滤出满足过滤条件的服务列表
public interface ServerListFilter {
public List getFilteredListOfServers(List servers);
}
3.4.2.1 Ribbon 的默认ServerListFilter实现:ZoneAffinityServerListFilter
Ribbon默认采取了区域优先的过滤策略,即当Server列表中,过滤出和当前实例所在的区域(zone)一致的server列表
与此相关联的,Ribbon有两个相关得配置参数:
| 控制参数 | 说明 | 默认值 |
|---|---|---|
| 是否开启区域优先 | false | |
| 是否采取区域排他性,即只返回和当前Zone一致的服务实例 | false | |
| 每个Server上的最大活跃请求负载数阈值 | 0.6 | |
| 最大断路过滤的百分比 | 0.8 | |
| 最少可用的服务实例阈值 | 2 |
其核心实现如下所示:
public class ZoneAffinityServerListFilter extends
AbstractServerListFilter implements IClientConfigAware {
@Override
public List getFilteredListOfServers(List servers) {
//zone非空,并且开启了区域优先,并且服务实例数量不为空
if (zone != null && (zoneAffinity || zoneExclusive) && servers !=null && servers.size() > 0){
//基于断言过滤服务列表
List filteredServers = Lists.newArrayList(Iterables.filter(
servers, this.zoneAffinityPredicate.getServerOnlyPredicate()));
//如果允许区域优先,则返回过滤列表
if (shouldEnableZoneAffinity(filteredServers)) {
return filteredServers;
} else if (zoneAffinity) {
overrideCounter.increment();
}
}
return servers;
}
// 判断是否应该使用区域优先过滤条件
private boolean shouldEnableZoneAffinity(List filtered) {
if (!zoneAffinity && !zoneExclusive) {
return false;
}
if (zoneExclusive) {
return true;
}
// 获取统计信息
LoadBalancerStats stats = getLoadBalancerStats();
if (stats == null) {
return zoneAffinity;
} else {
logger.debug("Determining if zone affinity should be enabled with given server list: {}", filtered);
//获取区域Server快照,包含统计数据
ZoneSnapshot snapshot = stats.getZoneSnapshot(filtered);
//平均负载,此负载的意思是,当前所有的Server中,平均每台机器上的活跃请求数
double loadPerServer = snapshot.getLoadPerServer();
int instanceCount = snapshot.getInstanceCount();
int circuitBreakerTrippedCount = snapshot.getCircuitTrippedCount();
// 1. 如果Server断路的比例超过了设置的上限(默认`0.8`)
// 2. 或者当前负载超过了设置的负载上限
// 3. 如果可用的服务小于设置的服务上限`默认为2`
if (((double) circuitBreakerTrippedCount) / instanceCount >= blackOutServerPercentageThreshold.get()
|| loadPerServer >= activeReqeustsPerServerThreshold.get()
|| (instanceCount - circuitBreakerTrippedCount) < availableServersThreshold.get()) {
logger.debug("zoneAffinity is overriden. blackOutServerPercentage: {}, activeReqeustsPerServer: {}, availableServers: {}",
new Object[] {(double) circuitBreakerTrippedCount / instanceCount, loadPerServer, instanceCount - circuitBreakerTrippedCount});
return false;
} else {
return true;
}
}
}
}
具体判断流程如下所示:

3.4.2.2 Ribbon 的ServerListFilter实现2:ZonePreferenceServerListFilter
ZonePreferenceServerListFilter 集成自 ZoneAffinityServerListFilter,在此基础上做了拓展,在 ZoneAffinityServerListFilter返回结果的基础上,再过滤出和本地服务相同区域(zone)的服务列表。
核心逻辑-什么时候起作用?
当指定了当前服务的所在Zone,并且ZoneAffinityServerListFilter没有起到过滤效果时,ZonePreferenceServerListFilter会返回当前Zone的Server列表。
public class ZonePreferenceServerListFilter extends ZoneAffinityServerListFilter {
private String zone;
@Override
public void initWithNiwsConfig(IClientConfig niwsClientConfig) {
super.initWithNiwsConfig(niwsClientConfig);
if (ConfigurationManager.getDeploymentContext() != null) {
this.zone = ConfigurationManager.getDeploymentContext().getValue(
ContextKey.zone);
}
}
@Override
public List getFilteredListOfServers(List servers) {
//父类的基础上,获取过滤结果
List output = super.getFilteredListOfServers(servers);
//没有起到过滤效果,则进行区域优先过滤
if (this.zone != null && output.size() == servers.size()) {
List local = new ArrayList<>();
for (Server server : output) {
if (this.zone.equalsIgnoreCase(server.getZone())) {
local.add(server);
}
}
if (!local.isEmpty()) {
return local;
}
}
return output;
}
public String getZone() {
return zone;
}
public void setZone(String zone) {
this.zone = zone;
}
3.4.2.3 Ribbon 的ServerListFilter实现3:ServerListSubsetFilter
这个过滤器作用于当Server数量列表特别庞大时(比如有上百个Server实例),这时,长时间保持Http链接也不太合适,可以适当地保留部分服务,舍弃其中一些服务,这样可使释放没必要的链接。
此过滤器也是继承自 ZoneAffinityServerListFilter,在此基础上做了拓展,在实际使用中不太常见,这个后续再展开介绍,暂且不表。
3.4.3 LoadBalancer选择服务实例 的流程
LoadBalancer的核心功能是根据负载情况,从服务列表中挑选最合适的服务实例。LoadBalancer内部采用了如下图所示的组件完成:

LoadBalancer 选择服务实例的流程
- 通过
ServerList获取当前可用的服务实例列表;- 通过
ServerListFilter将步骤1 得到的服务列表进行一次过滤,返回满足过滤器条件的服务实例列表;- 应用
Rule规则,结合服务实例的统计信息,返回满足规则的某一个服务实例;通过上述的流程可以看到,实际上,在服务实例列表选择的过程中,有两次过滤的机会:第一次是首先通过ServerListFilter过滤器,另外一次是用过IRule 的选择规则进行过滤
通过ServerListFilter进行服务实例过滤的策略上面已经介绍得比较详细了,接下来将介绍Rule是如何从一堆服务列表中选择服务的。
在介绍Rule之前,需要介绍一个概念:Server统计信息
当LoadBalancer在选择合适的Server提供给应用后,应用会向该Server发送服务请求,则在请求的过程中,应用会根据请求的相应时间或者网络连接情况等进行统计;当应用后续从LoadBalancer选择合适的Server时,LoadBalancer 会根据每个服务的统计信息,结合Rule来判定哪个服务是最合适的。
3.4.3.1 负载均衡器LoaderBalancer 都统计了哪些关于服务实例Server相关的信息?
| ServerStats | 说明 | 类型 | 默认值 |
|---|---|---|---|
| zone | 当前服务所属的可用区 | 配置 | 可通过 eureka.instance.meta.zone 指定 |
| totalRequests | 总请求数量,client每次调用,数量会递增 | 实时 | 0 |
| activeRequestsCountTimeout | 活动请求计数时间窗niws.loadbalancer.serverStats.activeRequestsCount.effectiveWindowSeconds,如果时间窗范围之内没有activeRequestsCount值的改变,则activeRequestsCounts初始化为0 |
配置 | 60*10(seconds) |
| successiveConnectionFailureCount | 连续连接失败计数 | 实时 | |
| connectionFailureThreshold | 连接失败阈值通过属性niws.loadbalancer.default.connectionFailureCountThreshold 进行配置 |
配置 | 3 |
| circuitTrippedTimeoutFactor | 断路器超时因子,niws.loadbalancer.default.circuitTripTimeoutFactorSeconds |
配置 | 10(seconds) |
| maxCircuitTrippedTimeout | 最大断路器超时秒数,niws.loadbalancer.default.circuitTripMaxTimeoutSeconds |
配置 | 30(seconds) |
| totalCircuitBreakerBlackOutPeriod | 累计断路器终端时间区间 | 实时 | milliseconds |
| lastAccessedTimestamp | 最后连接时间 | 实时 | |
| lastConnectionFailedTimestamp | 最后连接失败时间 | 实时 | |
| firstConnectionTimestamp | 首次连接时间 | 实时 | |
| activeRequestsCount | 当前活跃的连接数 | 实时 | |
| failureCountSlidingWindowInterval | 失败次数统计时间窗 | 配置 | 1000(ms) |
| serverFailureCounts | 当前时间窗内连接失败的数量 | 实时 | |
| responseTimeDist.mean | 请求平均响应时间 | 实时 | (ms) |
| responseTimeDist.max | 请求最大响应时间 | 实时 | (ms) |
| responseTimeDist.minimum | 请求最小响应时间 | 实时 | (ms) |
| responseTimeDist.minimum | 请求最小响应时间 | 实时 | (ms) |
| responseTimeDist.stddev | 请求响应时间标准差 | 实时 | (ms) |
| dataDist.sampleSize | QoS服务质量采集点大小 | 实时 | |
| dataDist.timestamp | QoS服务质量最后计算时间点 | 实时 | |
| dataDist.timestampMillis | QoS服务质量最后计算时间点毫秒数,自1970.1.1开始 | 实时 | |
| dataDist.mean | QoS 最近的时间窗内的请求平均响应时间 | 实时 | |
| dataDist.10thPercentile | QoS 10% 处理请求的时间 | 实时 | ms |
| dataDist.25thPercentile | QoS 25% 处理请求的时间 | 实时 | ms |
| dataDist.50thPercentile | QoS 50% 处理请求的时间 | 实时 | ms |
| dataDist.75thPercentile | QoS 75% 处理请求的时间 | 实时 | ms |
| dataDist.95thPercentile | QoS 95% 处理请求的时间 | 实时 | ms |
| dataDist.99thPercentile | QoS 99% 处理请求的时间 | 实时 | ms |
| dataDist.99.5thPercentile | QoS 前99.5% 处理请求的时间 | 实时 | ms |
3.4.3.2 服务断路器的工作原理
当有某个服务存在多个实例时,在请求的过程中,负载均衡器会统计每次请求的情况(请求相应时间,是否发生网络异常等),当出现了请求出现累计重试时,负载均衡器会标识当前
服务实例,设置当前服务实例的断路的时间区间,在此区间内,当请求过来时,负载均衡器会将此服务实例从可用服务实例列表中暂时剔除,优先选择其他服务实例。
相关统计信息如下:
| ServerStats | 说明 | 类型 | 默认值 |
|---|---|---|---|
| successiveConnectionFailureCount | 连续连接失败计数 | 实时 | |
| connectionFailureThreshold | 连接失败阈值通过属性niws.loadbalancer.default.connectionFailureCountThreshold 进行配置,当successiveConnectionFailureCount 超过了此限制时,将计算熔断时间 |
配置 | 3 |
| circuitTrippedTimeoutFactor | 断路器超时因子,niws.loadbalancer.default.circuitTripTimeoutFactorSeconds |
配置 | 10(seconds) |
| maxCircuitTrippedTimeout | 最大断路器超时秒数,niws.loadbalancer.default.circuitTripMaxTimeoutSeconds |
配置 | 30(seconds) |
| totalCircuitBreakerBlackOutPeriod | 累计断路器终端时间区间 | 实时 | milliseconds |
| lastAccessedTimestamp | 最后连接时间 | 实时 | |
| lastConnectionFailedTimestamp | 最后连接失败时间 | 实时 | |
| firstConnectionTimestamp | 首次连接时间 | 实时 |
@Monitor(name="CircuitBreakerTripped", type = DataSourceType.INFORMATIONAL)
public boolean isCircuitBreakerTripped() {
return isCircuitBreakerTripped(System.currentTimeMillis());
}
public boolean isCircuitBreakerTripped(long currentTime) {
//断路器熔断的时间戳
long circuitBreakerTimeout = getCircuitBreakerTimeout();
if (circuitBreakerTimeout <= 0) {
return false;
}
return circuitBreakerTimeout > currentTime;//还在熔断区间内,则返回熔断结果
}
//获取熔断超时时间
private long getCircuitBreakerTimeout() {
long blackOutPeriod = getCircuitBreakerBlackoutPeriod();
if (blackOutPeriod <= 0) {
return 0;
}
return lastConnectionFailedTimestamp + blackOutPeriod;
}
//返回中断毫秒数
private long getCircuitBreakerBlackoutPeriod() {
int failureCount = successiveConnectionFailureCount.get();
int threshold = connectionFailureThreshold.get();
// 连续失败,但是尚未超过上限,则服务中断周期为 0 ,表示可用
if (failureCount < threshold) {
return 0;
}
//当链接失败超过阈值时,将进行熔断,熔断的时间间隔为:
int diff = (failureCount - threshold) > 16 ? 16 : (failureCount - threshold);
int blackOutSeconds = (1 << diff) * circuitTrippedTimeoutFactor.get();
if (blackOutSeconds > maxCircuitTrippedTimeout.get()) {
blackOutSeconds = maxCircuitTrippedTimeout.get();
}
return blackOutSeconds * 1000L;
}
熔断时间的计算
- 计算累计连接失败计数
successiveConnectionFailureCount是否超过 链接失败阈值connectionFailureThreshold。如果successiveConnectionFailureCount<connectionFailureThreshold,即尚未超过限额,则熔断时间为 0 ;反之,如果超过限额,则进行步骤2的计算; - 计算失败基数,最大不得超过 16:
diff = (failureCount - threshold) > 16 ? 16 : (failureCount - threshold) - 根据超时因子
circuitTrippedTimeoutFactor计算超时时间:int blackOutSeconds = (1 << diff) * circuitTrippedTimeoutFactor.get(); - 超时时间不得超过最大超时时间`maxCircuitTrippedTimeout 上线,
当有链接失败情况出现断路逻辑时,将会最多:1<<16 * 10 =320s、最少1<<1 * 10 =100s 的请求熔断时间,再此期间内,此Server将会被忽略。
即:
熔断时间最大值:1<<16 * 10 =320s
熔断时间最小值:1<<1 * 10 =100s
熔断统计何时清空?
熔断的统计有自己的清除策略,当如下几种场景存在时,熔断统计会清空归零:
- 当请求时,发生的异常不是
断路拦截类的异常(Exception)时(至于如何节点是否是断路拦截类异常,可以自定义)- 当请求未发生异常,切且有结果返回时
3.4.3.3 定义IRule,从服务实例列表中,选择最合适的Server实例

由上图可见,IRule会从服务列表中,根据自身定义的规则,返回最合适的Server实例,其接口定义如下:
public interface IRule{
/*
* choose one alive server from lb.allServers or
* lb.upServers according to key
*
* @return choosen Server object. NULL is returned if none
* server is available
*/
public Server choose(Object key);
public void setLoadBalancer(ILoadBalancer lb);
public ILoadBalancer getLoadBalancer();
}
Ribbon定义了一些常见的规则
| 实现 | 描述 | 备注 |
|---|---|---|
| RoundRobinRule | 通过轮询的方式,选择过程会有最多10次的重试机制 | |
| RandomRule | 随机方式,从列表中随机挑选一个服务 | |
| ZoneAvoidanceRule | 基于ZoneAvoidancePredicate断言和AvailabilityPredicate断言的规则。ZoneAvoidancePredicate计算出哪个Zone的服务最差,然后将此Zone的服务从服务列表中剔除掉;而AvaliabitiyPredicate是过滤掉正处于熔断状态的服务;上述两个断言过滤出来的结果后,再通过RoundRobin轮询的方式从列表中挑选一个服务 | |
| BestAvailableRule | 最优匹配规则:从服务列表中给挑选出并发数最少的Server | |
| RetryRule | 采用了装饰模式,为Rule提供了重试机制 | |
| WeightedResponseTimeRule | 基于请求响应时间加权计算的规则,如果此规则没有生效,将采用 RoundRobinRule的的策略选择服务实例 |

3.4.3.3.1 RoundRobinRule 的实现
public class RoundRobinRule extends AbstractLoadBalancerRule {
private AtomicInteger nextServerCyclicCounter;
private static final boolean AVAILABLE_ONLY_SERVERS = true;
private static final boolean ALL_SERVERS = false;
private static Logger log = LoggerFactory.getLogger(RoundRobinRule.class);
public RoundRobinRule() {
nextServerCyclicCounter = new AtomicInteger(0);
}
public RoundRobinRule(ILoadBalancer lb) {
this();
setLoadBalancer(lb);
}
public Server choose(ILoadBalancer lb, Object key) {
if (lb == null) {
log.warn("no load balancer");
return null;
}
Server server = null;
int count = 0;
//10次重试机制
while (server == null && count++ < 10) {
List reachableServers = lb.getReachableServers();
List allServers = lb.getAllServers();
int upCount = reachableServers.size();
int serverCount = allServers.size();
if ((upCount == 0) || (serverCount == 0)) {
log.warn("No up servers available from load balancer: " + lb);
return null;
}
// 生成轮询数据
int nextServerIndex = incrementAndGetModulo(serverCount);
server = allServers.get(nextServerIndex);
if (server == null) {
/* Transient. */
Thread.yield();
continue;
}
if (server.isAlive() && (server.isReadyToServe())) {
return (server);
}
// Next.
server = null;
}
if (count >= 10) {
log.warn("No available alive servers after 10 tries from load balancer: "
+ lb);
}
return server;
}
/**
* Inspired by the implementation of {@link AtomicInteger#incrementAndGet()}.
*
* @param modulo The modulo to bound the value of the counter.
* @return The next value.
*/
private int incrementAndGetModulo(int modulo) {
for (;;) {
int current = nextServerCyclicCounter.get();
int next = (current + 1) % modulo;
if (nextServerCyclicCounter.compareAndSet(current, next))
return next;
}
}
@Override
public Server choose(Object key) {
return choose(getLoadBalancer(), key);
}
}
3.4.3.3.2 ZoneAvoidanceRule的实现
ZoneAvoidanceRule的处理思路:
- ZoneAvoidancePredicate 计算出哪个Zone的服务最差,然后将此Zone的服务从服务列表中剔除掉;
- AvailabilityPredicate 将处于熔断状态的服务剔除掉;
- 将上述两步骤过滤后的服务通过RoundRobinRule挑选一个服务实例返回
ZoneAvoidancePredicate 剔除最差的Zone的过程:
public static Set getAvailableZones(
Map snapshot, double triggeringLoad,
double triggeringBlackoutPercentage) {
if (snapshot.isEmpty()) {
return null;
}
Set availableZones = new HashSet(snapshot.keySet());
if (availableZones.size() == 1) {
return availableZones;
}
Set worstZones = new HashSet();
double maxLoadPerServer = 0;
boolean limitedZoneAvailability = false;
for (Map.Entry zoneEntry : snapshot.entrySet()) {
String zone = zoneEntry.getKey();
ZoneSnapshot zoneSnapshot = zoneEntry.getValue();
int instanceCount = zoneSnapshot.getInstanceCount();
if (instanceCount == 0) {
availableZones.remove(zone);
limitedZoneAvailability = true;
} else {
double loadPerServer = zoneSnapshot.getLoadPerServer();
//如果负载超过限额,则将用可用区中剔除出去
if (((double) zoneSnapshot.getCircuitTrippedCount())
/ instanceCount >= triggeringBlackoutPercentage
|| loadPerServer < 0) {
availableZones.remove(zone);
limitedZoneAvailability = true;
} else {
//计算最差的Zone区域
if (Math.abs(loadPerServer - maxLoadPerServer) < 0.000001d) {
// they are the same considering double calculation
// round error
worstZones.add(zone);
} else if (loadPerServer > maxLoadPerServer) {
maxLoadPerServer = loadPerServer;
worstZones.clear();
worstZones.add(zone);
}
}
}
}
// 如果最大负载没有超过上限,则返回所有可用分区
if (maxLoadPerServer < triggeringLoad && !limitedZoneAvailability) {
// zone override is not needed here
return availableZones;
}
// 从最差的可用分区中随机挑选一个剔除,这么做是保证服务的高可用
String zoneToAvoid = randomChooseZone(snapshot, worstZones);
if (zoneToAvoid != null) {
availableZones.remove(zoneToAvoid);
}
return availableZones;
}
四. Ribbon的配置参数
| 控制参数 | 说明 | 默认值 |
|---|---|---|
| Ping定时任务周期 | 30 s | |
| Ping超时时间 | 2s | |
| IRule实现类 | RoundRobinRule,基于轮询调度算法规则选择服务实例 | |
| IPing实现类 | DummyPing,直接返回true | |
| 负载均衡器实现类 | 2s | |
| ServerList实现类 | ConfigurationBasedServerList,基于配置的服务列表 | |
| 服务列表更新类 | PollingServerListUpdater, | |
| 服务实例过滤器 | 2s | |
| 服务列表刷新频率 | 2s | |
| 自定义负载均衡器实现类 | 2s | |
| 自定义负载均衡器实现类 | 2s | |
| 自定义负载均衡器实现类 | 2s |
五. 结语
Ribbon是Spring Cloud框架中相当核心的模块,负责着服务负载调用,Ribbon也可以脱离SpringCloud单独使用。
另外Ribbon是客户端的负载均衡框架,即每个客户端上,独立维护着自身的调用信息统计,相互隔离;也就是说:Ribbon的负载均衡表现在各个机器上变现并不完全一致
Ribbon 也是整个组件框架中最复杂的一环,控制流程上为了保证服务的高可用性,有很多比较细节的参数控制,在使用的过程中,需要深入理清每个环节的处理机制,这样在问题定位上会高效很多。
