kmp算法完成的任务是:给定两个字符串O和f,长度分别为n和 m,判断f是否在O中出现,如果出现则返回出现的位置。常规方法是遍历O的每一个位置,然后从该位置开始和f进行匹配,但是这种方法的复杂度是 O(nm)。kmp算法通过一个O(m)的预处理,使匹配的复杂度降为O(n+m)。
kmp算法思想
我们首先用一个图来描述kmp算法的思想。在字符串O中寻 找f,当匹配到位置i时两个字符串不相等,这时我们需要将字符串f向前移动。常规方法是每次向前移动一位,但是它没有考虑前i-1位已经比较过这个事实, 所以效率不高。事实上,如果我们提前计算某些信息,就有可能一次前移多位。假设我们根据已经获得的信息知道可以前移k位,我们分析移位前后的f有什么特点。我们可以得到如下的结论:
- A段字符串是f的一个前缀。
- B段字符串是f的一个后缀。
- A段字符串和B段字符串相等。
所以前移k位之后,可以继续比较位置i的前提是f的前i-1个位置满足:长度为i-k-1的前缀A和后缀B相同。只有这样,我们才可以前移k位后从新的位置继续比较。

所以kmp算法的核心即是计算字符串f每一个位置之前的字 符串的前缀和后缀公共部分的最大长度(不包括字符串本身,否则最大长度始终是字符串本身)。获得f每一个位置的最大公共长度之后,就可以利用该最大公共长 度快速和字符串O比较。当每次比较到两个字符串的字符不同时,我们就可以根据最大公共长度将字符串f向前移动(已匹配长度-最大公共长度)位,接着继续比 较下一个位置。事实上,字符串f的前移只是概念上的前移,只要我们在比较的时候从最大公共长度之后比较f和O即可达到字符串f前移的目的。
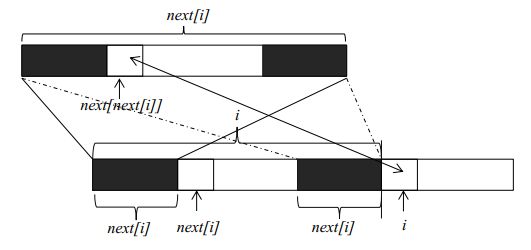
next数组计算
理解了kmp算法的基本原理,下一步就是要获得字符串f每一个位置的最大公共长度。这个最大公共长度在算法导论里面被记为next数组。在这里要注意一点, next 数组表示的是长度,下标从 1 开始;但是在遍历原字符串时,下标还是从 0 开始。假设我们现在已经求得next[1]、next[2]、……next[i],分别表示长度为1到i的字符串的前缀和后缀最大公共长度,现在要求next[i+1]。由上图我们可以看到,如果位置i和位置next[i]处的两个字符相同(下标从零开始), 则next[i+1]等于next[i]加1。如果两个位置的字符不相同,我们可以将长度为next[i]的字符串继续分割,获得其最大公共长度 next[next[i]],然后再和位置i的字符比较。这是因为长度为next[i]前缀和后缀都可以分割成上部的构造,如果位置 next[next[i]]和位置i的字符相同,则next[i+1]就等于next[next[i]]加1。如果不相等,就可以继续分割长度为 next[next[i]]的字符串,直到字符串长度为0为止。由此我们可以写出求next数组的代码( Java版):
上述代码需要注意的问题是,我们求取的next数组表示长度为1 到m的字符串f前缀的最大公共长度,所以需要多分配一个空间。而在遍历字符串f的时候,还是从下标0开始(位置0和1的next值为0,所以放在循环外 面),到m-1为止。代码的结构和上面的讲解一致,都是利用前面的next值去求下一个next值。
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
|
public
int
[] getNext(String b)
{
int
len=b.length();
int
j=
0
;
int
next[]=
new
int
[len+
1
];
//next表示长度为i的字符串前缀和后缀的最长公共部分,从1开始
next[
0
]=next[
1
]=
0
;
for
(
int
i=
1
;i
{
//j在每次循环开始都表示next[i]的值,同时也表示需要比较的下一个位置
while
(j>
0
&&b.charAt(i)!=b.charAt(j))j=next[j];
if
(b.charAt(i)==b.charAt(j))j++;
next[i+
1
]=j;
}
return
next;
}
|
字符串匹配
计算完成next数组之后,我们就可以利用next数组在 字符串O中寻找字符串f的出现位置。匹配的代码和求next数组的代码非常相似,因为匹配的过程和求next数组的过程其实是一样的。假设现在字符串f的 前i个位置都和从某个位置开始的字符串O匹配,现在比较第i+1个位置。如果第i+1个位置相同,接着比较第i+2个位置;如果第i+1个位置不同,则出 现不匹配,我们依旧要将长度为i的字符串分割,获得其最大公共长度next[i],然后从next[i]继续比较两个字符串。这个过程和求next数组一 致,所以可以匹配代码如下(java版):
上述代码需要注意的一点是,每次我们得到一个匹配之后都要对j重新赋值。
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
|
public
void
search(String original, String find,
int
next[]) {
int
j =
0
;
for
(
int
i =
0
; i < original.length(); i++) {
while
(j >
0
&& original.charAt(i) != find.charAt(j))
j = next[j];
if
(original.charAt(i) == find.charAt(j))
j++;
if
(j == find.length()) {
System.out.println(
"find at position "
+ (i - j));
System.out.println(original.subSequence(i - j +
1
, i +
1
));
j = next[j];
}
}
}
|
2、哈夫曼树只有度为2的结点和叶子结点,并且n0=n2+1
&&、n&=(n-1),就是去掉二进制表示最右边的1
&&、如何构造霍夫曼树
先从数组中选出两个最小的数1,1作为两个路径的权值,然后将这两个数相加放到数组中就是2,3,2,5,然后在从中选出最小的两个数2,2作为两个路径的权值。再将这两个数相加放到数组中得到4,3,5.然后在选出两个最小的数4,3作为两个路径的权值。在将这两个数的和放到数组中,得到7,5这就是最后的两个权值