HDFS 读写分离(总体架构介绍)
文章目录
- 为什么HDFS需要读写分离
- 当前架构:
- HA同步机制简单介绍:
- 读写的全局锁
- 怎么改善全局锁限制
- 1. 拆锁,把锁的粒度拆的更细。
- 1.1 采用分段锁,把全局锁分段,如下图所示:
- 2. 从Standby Namenode进行读
- 一致性读实现面临的挑战
- 一致性模型介绍
- 脏读的例子:
- 实现需求和实现细节:
- 一致性读基本需求:
- 1. 读客户端自己写的内容:
- 2. 第三方读取:
- 优化点
- 3.实现细节
为什么HDFS需要读写分离
当前架构:
目前HDFS在HA模式下的架构图如如下:

HA同步机制简单介绍:
客户端读写都通过RPC连接Active Namenode进行操作,Standby Namenode不具有读写的功能只负责同步操作记录(Editlog)。Editlog是Active Namenode通过RPC写到由PAXOS协议实现的一组Journalnode,然后Standby Namenode通过HTTP协议去拉Journalnode的Editlog进行同步的。
读写的全局锁
上面介绍了客户端只能通过RPC从Active Namenode,那么Active Namenode既承载了读的压力,又承载了写的压力。感性上我们会觉得它的压力很大,那么我们根据事实进行分析一下。
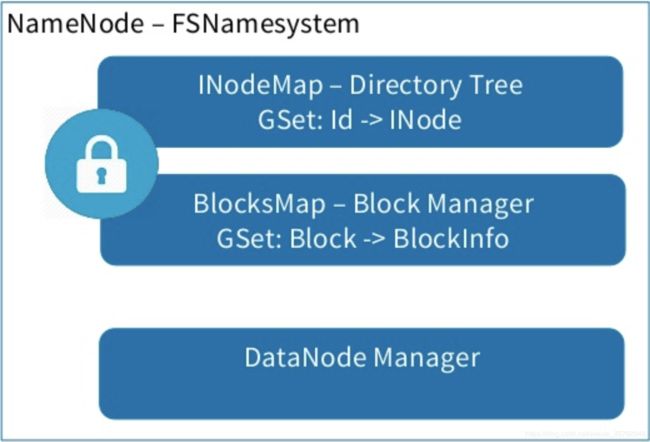
如上图所示,Namenode的FSNamesystem类中主要有三块。
- INodeMap中存着目录树的映射关系:Id -> INode
- BlocksMap中存着块和块位置信息的映射信息。Block -> BlockInfo
- DataNode Manager : 用于对DataNode进行管理。
(GSet是一种高效的HashMap实现)
而这三种数据结构都在全局锁读写锁的锁范围内:
全局读写锁类(暂时不对读写锁的进行实现分析,封装了常见的读写锁实现类ReentrantReadWriteLock):

虽然写的场景在集群中可能只占10%左右,读的场景占90%左右。但是无论是目录树还是块管理的更新,都在全局锁的写锁范围内,而写锁是排他锁,会对集群的整体读写延迟等性能和集群整体的吞吐量产生较大的影响。所以为了提升读写性能,和集群的吞吐量,社区等对HDFS读写分离展开了讨论和开发。
怎么改善全局锁限制
针对怎么改善全局锁限制,社区有很多的讨论,主要分为两大块:
1. 拆锁,把锁的粒度拆的更细。
1.1 采用分段锁,把全局锁分段,如下图所示:

该架构NameNode中数据结构与全局锁不同,分段锁具有两层映射关系:
- RangeMap: keyRange -> GSet
- RangeSet: key -> INode
好处显而易见: 首先,锁的范围减小了,避免了全局锁限制。其次,每个锁之间的操作都是独立的,各个锁区间的操作,可以并行进行。
2. 从Standby Namenode进行读
社区HDFS-12943的issues针对这个功能进行讨论和开发中。我们详细跟进并且分析该读写分离模式的实现原理和源码分析。
如果理想的情况,读写各50%,那么这种模式好像能够将整体的吞吐量提升100%。但是实际情况是读差不多有90%,但是也能提升很大一部分整体的读写吞吐量,以及相当可观的读写性能提升。
一致性读实现面临的挑战
社区提出了State ID的概念作为读一致性的标志ID,当前这个ID是用Namenode的Transaction ID实现的。
需要实现从Standby Namenode持续性读,必须保持ANN(Acitve Namenode)和SBN(Standby Namenode)之间State ID一致性,即按照目前的实现,Transaction ID必须一致。但是ANN和 SBN之间的Transaction ID是具有延迟的,ANN作为Transaction ID的生产者,SBN作为Transaction ID的消费者。所以从客户端的角度如果从SBN进行可持续性的读,必须解决怎么样才能够读到新写入的文件。
一致性模型介绍
假设obj.modId表示对象obj最后一次的state id,对象obj表示一个文件或者目录的INode表示。
要实现一致性,必须遵循如下原则:
如果一个用户在 t1时刻修改了对象标记为modId1操作,那么在 t2时刻的操作modId2必须满足 modId2 >= modId1
因为从SBN读的时候,可能读到的数据是ANN的旧数据,而非最新的写入数据。
脏读的例子:
- 用户通过ANN创建了一个文件,但是由于延迟,该用户不能从SBN读创建的文件。
- 用户通过SBN打开了一个文件准备进行读操作,但是由于延迟,该文件已经被ANN端的RPC操作删除(可能是:renamed, appended, truncated):
2.1 可能是同一个用户的删除操作。(renamed, appended, truncated)
2.2 可能是其他用户的删除操作。(renamed, appended, truncated) - 以计算任务的作业为例子: 比如Mapreduce作业提交的时候需要一个提交目录,提交job的配置信息和job的jar程序等信息,然后其他客户端需要对这些文件进行读取。但是由于ANN和SBN之间的延迟,这些需要读取的客户端没有读到,就会导致作业失败。
实现需求和实现细节:
一致性读基本需求:
1. 读客户端自己写的内容:
客户端自己在ANN写操作,需要能在SBN上面进行读取,而不出现读不到新写入内容的情况。
NameNode用LastWrittenId标志它最新的状态,相对应的也是对应的namespace的最近一次的更新,也是写入NN对应journal的最新transaction。
社区为HDFS client引入了LastSeenId字段,客户端每次请求ANN或者SBN都会对其进行更新,且和LastWrittenId字段是独立的。假设client c向ANN发起请求,然后执行后就会设置 c.LastSeenId = ANN.LastWrittenId。然后client c向SBN,SBN将会等到 c.LastSeenId <= SBN.LastWrittenId,然后执行读的请求。
如果ANN和SBN之间journal的transactions延迟很小,那么从SBN读的方案是可行的,但是如果延迟很大,那么只能回滚到从ANN去读。
2. 第三方读取:
某个客户端在ANN写操作,第三方其他客户端要能够在SBN上面读取对应的内容,而不出现读不到新写入内容的情况。
问题:
我们假设,HDFS的两个客户端,读客户端cR和写客户端cW在两台不同的服务器上。cW写了大量的数据到ANN,然后cR准备读SBN,但是SBN还没来得及同步,然后读取就失败了。
当同一个用户读写的时候,可以等待SBN同步最近的state id达到可以读的需求。但是第三方的读取,即非同一个用户的读写,其他用户根本得不到写用户client c的c.LastSeenId。
解决方法:
似乎第三方的读取在这种情况下,只能回滚到从ANN上面去读才能保持一致性读。
社区提出了新的API:
提出的新的API是:FileSystem.msync(), 这个方法保证了当前客户端对应的state id 是和SBN的state id是完全一致的。这个方法和hflush()很相似,后者保证了写入的数据可以被其他用户进行读取了,而FileSystem.msync()
保证了元数据的可读取。
msync()既能被用于ANN的客户端cW写操作,也能被用于SBN的客户端cR读操作:
- cW.msync()保证了SBN.LastWrittenId可以追上写操作对应的最新状态cW.LastSeenId。这样cW写完后的这个操作,就能使cR向 SBN发起读请求。
- cR.msync()会先获取ANN.LastWrittenId的值,然后等SBN.LastWrittenId追上ANN。
两种情况,都能保证cR能读取cW最新的写操作。
优化点
我们可以预计msync()的代价比较大,一方面是延迟增加,另一方面是同步加重了ANN的负载。
比如Mapreduce作业提交的job.xml文件,如果已经被某个客户从SBN读取过,那么其他客户从SBN读取的时候,就没有必要再去做一致性操作了。所以可以对已经从SBN读取过的文件做个标记,最直接的做法是加个字段,“never-read”表示没有读过,读完以后变成“read”,但是这样会让namespace的内存占用整体加大。为此我们采用如下方法:
我们使用已有的字段mTime和aTime, 来避免增加INode的大小,当文件被创建没有进行读取操作的时候,mTime == aTime, 当文件第一次被读取以后,aTime就会增加了。
代价就在第一次读取的时候,需要持久化读取操作,进行INode的更新。之后的读取就不需要该操作了。
3.实现细节
HDFS客户端服务端的通信,目前通过FailoverProxyProvider类作为一个插件。这个类实现类,客户端访问ANN和SBN之间的client的failover,如果访问了SBN则会重试到ANN。如果我们需要从SBN上面取读,而在ANN写操作,那么客户端从一个namenode切换到另一个将会是频繁的操作,我们必须实现一个新的proxy provider插件。
提出Observer Node的概念,和SBN一样,它会消费journal transaction来同步操作日志,但是它不参与checkpoint操作。ObserverNode用新的启动命令进行启动: hdfs namenode -observer
而CheckPoint由另一个SBN进行实现,也就是说需要支持多个SBN,目前HDFS-6440已经实现了多个SBN的功能。