Java集成datax开发从hive到mysql的数据同步
系统要做一个数据同步的功能,在综合考虑了kettle,sqoop,datax等的优劣后(其实kettle是我们一直使用的,就是容易内存溢出.sqoop也在用,datax根本没用过),kettle的优点就是比较简单,但是操作起来也有些麻烦,基于java api操作kettle生成转换和文件也是异常的麻烦,因此这个方案放弃,sqoop的话是因为需要在集群上安装相应的环境,对于我们这种对外开放的系统来讲.这种方案显然不得行,而且sqoop漏洞也多.最后了解到的就剩下了datax,硬着头皮开干.
datax源码下载及文档
由于maven仓库上也并没有相应的依赖,因此需要将相关依赖安装到仓库中去.
datax目录结构

将lib目录下的部分jar包安装到maven仓库

安装命令
mvn install:install-file -Dfile=D:\datax\datax\lib\commons-cli-1.2.jar -DgroupId=com.alibaba.datax -DartifactId=commons-cli -Dversion=1.2 -Dpackaging=jar
只举例其中一个,其他的以此类推.
安装后在idea中引入依赖

系统集成
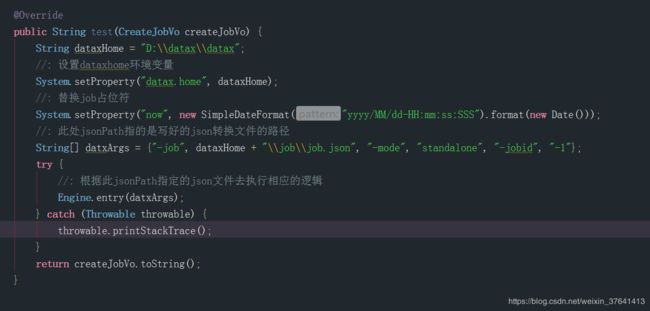
String dataxHome = "D:\\datax\\datax";
//: 设置dataxhome环境变量
System.setProperty("datax.home", dataxHome);
//: 替换job占位符
System.setProperty("now", new SimpleDateFormat("yyyy/MM/dd-HH:mm:ss:SSS").format(new Date()));
//: 此处jsonPath指的是写好的json转换文件的路径
String[] datxArgs = {"-job", dataxHome + "\\job\\job.json", "-mode", "standalone", "-jobid", "-1"};
try {
//: 根据此jsonPath指定的json文件去执行相应的逻辑
Engine.entry(datxArgs);
} catch (Throwable throwable) {
throwable.printStackTrace();
}
return createJobVo.toString();
启动项目后执行
此处的job.json是datax自带的测试的json
控制台打印
{
"content":[
{
"reader":{
"parameter":{
"column":[
{
"type":"string",
"value":"DataX"
},
{
"type":"long",
"value":19890604
},
{
"type":"date",
"value":"1989-06-04 00:00:00"
},
{
"type":"bool",
"value":true
},
{
"type":"bytes",
"value":"test"
}
],
"sliceRecordCount":100000
},
"name":"streamreader"
},
"writer":{
"parameter":{
"print":false,
"encoding":"UTF-8"
},
"name":"streamwriter"
}
}
],
"setting":{
"errorLimit":{
"record":0,
"percentage":0.02
},
"speed":{
"byte":10485760
}
}
}
2019-12-06 10:51:22.493 WARN 94968 --- [nio-7047-exec-3] com.alibaba.datax.core.Engine : prioriy set to 0, because NumberFormatException, the value is: null
2019-12-06 10:51:22.495 INFO 94968 --- [nio-7047-exec-3] c.a.datax.common.statistics.PerfTrace : PerfTrace traceId=job_-1, isEnable=false, priority=0
2019-12-06 10:51:22.495 INFO 94968 --- [nio-7047-exec-3] com.alibaba.datax.core.job.JobContainer : DataX jobContainer starts job.
2019-12-06 10:51:22.496 INFO 94968 --- [nio-7047-exec-3] com.alibaba.datax.core.job.JobContainer : Set jobId = 0
2019-12-06 10:51:22.510 INFO 94968 --- [ job-0] com.alibaba.datax.core.job.JobContainer : jobContainer starts to do prepare ...
2019-12-06 10:51:22.510 INFO 94968 --- [ job-0] com.alibaba.datax.core.job.JobContainer : DataX Reader.Job [streamreader] do prepare work .
2019-12-06 10:51:22.510 INFO 94968 --- [ job-0] com.alibaba.datax.core.job.JobContainer : DataX Writer.Job [streamwriter] do prepare work .
2019-12-06 10:51:22.510 INFO 94968 --- [ job-0] com.alibaba.datax.core.job.JobContainer : jobContainer starts to do split ...
2019-12-06 10:51:22.511 INFO 94968 --- [ job-0] com.alibaba.datax.core.job.JobContainer : Job set Max-Byte-Speed to 10485760 bytes.
2019-12-06 10:51:22.511 INFO 94968 --- [ job-0] com.alibaba.datax.core.job.JobContainer : DataX Reader.Job [streamreader] splits to [1] tasks.
2019-12-06 10:51:22.511 INFO 94968 --- [ job-0] com.alibaba.datax.core.job.JobContainer : DataX Writer.Job [streamwriter] splits to [1] tasks.
2019-12-06 10:51:22.516 INFO 94968 --- [ job-0] com.alibaba.datax.core.job.JobContainer : jobContainer starts to do schedule ...
2019-12-06 10:51:22.519 INFO 94968 --- [ job-0] com.alibaba.datax.core.job.JobContainer : Scheduler starts [1] taskGroups.
2019-12-06 10:51:22.522 INFO 94968 --- [ job-0] com.alibaba.datax.core.job.JobContainer : Running by standalone Mode.
2019-12-06 10:51:22.527 INFO 94968 --- [ taskGroup-0] c.a.d.core.taskgroup.TaskGroupContainer : taskGroupId=[0] start [1] channels for [1] tasks.
2019-12-06 10:51:22.530 INFO 94968 --- [ taskGroup-0] c.a.d.core.transport.channel.Channel : Channel set byte_speed_limit to -1, No bps activated.
2019-12-06 10:51:22.530 INFO 94968 --- [ taskGroup-0] c.a.d.core.transport.channel.Channel : Channel set record_speed_limit to -1, No tps activated.
2019-12-06 10:51:22.541 INFO 94968 --- [ taskGroup-0] c.a.d.core.taskgroup.TaskGroupContainer : taskGroup[0] taskId[0] attemptCount[1] is started
2019-12-06 10:51:22.842 INFO 94968 --- [ taskGroup-0] c.a.d.core.taskgroup.TaskGroupContainer : taskGroup[0] taskId[0] is successed, used[302]ms
2019-12-06 10:51:22.842 INFO 94968 --- [ taskGroup-0] c.a.d.core.taskgroup.TaskGroupContainer : taskGroup[0] completed it's tasks.
2019-12-06 10:51:32.539 INFO 94968 --- [ job-0] c.c.j.StandAloneJobContainerCommunicator : Total 100000 records, 2600000 bytes | Speed 253.91KB/s, 10000 records/s | Error 0 records, 0 bytes | All Task WaitWriterTime 0.016s | All Task WaitReaderTime 0.025s | Percentage 100.00%
2019-12-06 10:51:32.539 INFO 94968 --- [ job-0] c.a.d.c.job.scheduler.AbstractScheduler : Scheduler accomplished all tasks.
2019-12-06 10:51:32.539 INFO 94968 --- [ job-0] com.alibaba.datax.core.job.JobContainer : DataX Writer.Job [streamwriter] do post work.
2019-12-06 10:51:32.539 INFO 94968 --- [ job-0] com.alibaba.datax.core.job.JobContainer : DataX Reader.Job [streamreader] do post work.
2019-12-06 10:51:32.540 INFO 94968 --- [ job-0] com.alibaba.datax.core.job.JobContainer : DataX jobId [0] completed successfully.
2019-12-06 10:51:32.540 INFO 94968 --- [ job-0] c.a.d.core.container.util.HookInvoker : No hook invoked, because base dir not exists or is a file: D:\datax\datax\hook
2019-12-06 10:51:32.541 INFO 94968 --- [ job-0] com.alibaba.datax.core.job.JobContainer :
[total cpu info] =>
averageCpu | maxDeltaCpu | minDeltaCpu
-1.00% | -1.00% | -1.00%
[total gc info] =>
NAME | totalGCCount | maxDeltaGCCount | minDeltaGCCount | totalGCTime | maxDeltaGCTime | minDeltaGCTime
PS MarkSweep | 3 | 3 | 3 | 0.271s | 0.271s | 0.271s
PS Scavenge | 11 | 11 | 11 | 0.458s | 0.458s | 0.458s
2019-12-06 10:51:32.541 INFO 94968 --- [ job-0] com.alibaba.datax.core.job.JobContainer : PerfTrace not enable!
2019-12-06 10:51:32.541 INFO 94968 --- [ job-0] c.c.j.StandAloneJobContainerCommunicator : Total 100000 records, 2600000 bytes | Speed 253.91KB/s, 10000 records/s | Error 0 records, 0 bytes | All Task WaitWriterTime 0.016s | All Task WaitReaderTime 0.025s | Percentage 100.00%
2019-12-06 10:51:32.542 INFO 94968 --- [ job-0] com.alibaba.datax.core.job.JobContainer :
任务启动时刻 : 2019-12-06 10:51:22
任务结束时刻 : 2019-12-06 10:51:32
任务总计耗时 : 10s
任务平均流量 : 253.91KB/s
记录写入速度 : 10000rec/s
读出记录总数 : 100000
读写失败总数 : 0
系统集成方面到这里就算成功了,接下来针对hive–>mysql的过程,需要写相应的json文件来执行转换,具体的json的写法及详细的文档,在github上都有相应的说明.