MyBatis源码实现之解析器
解析器
在MyBatis 中涉及多个XML 配置文件,因此我们首先介绍XML 解析的相关内容。XML
解析常见的方式有三种, 分别是: DOM ( Document Object Model )解析方式和SAX ( Simple API
for XML )解析方式,以及从JDK6.0 版本开始, JDK 开始支持的StAX ( Streaming API for XML)
解析方式。在开始介绍My Batis 的XML 解析功能之前,先介绍这几种常见的XML 处理方式。
DOM
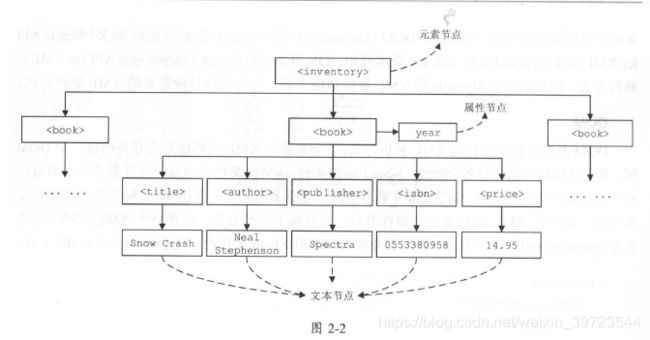
DOM是基于树形结构的XML 解析方式,它会将整个XML 文档读入内存并构建一个DOM
树,基于这棵树形结构对各个节点( Node )进行操作。XML 文档中的每个成分都是一个节点:
整个文档是一个文档节点, 每个X扣E 标签对应一个元素节点,包含在X岛1L 标签中的文本是文
本节点,每一个XML 属性是一个属性节点,注释属于注释节点。现有一个X扎在L 文档(文件
名是inventory. xml )如下所示,在后面介绍DOM 和XPath 使用时,还会使用到该XML 文件:
Snow Crash
Neal Stephenson
Spectra
0553380958
14.95
Burning Tower
Larry Niven
Jerry Pournelle
Pocke
074341691
5.99
Zodiac
Neal Stephenson
Spectra
0553573862
7.50
经过DOM 解析后得到的树形结构如图2-2 所示。
DOM解析方式最主要的好处是易于编程,可以根据需求在树形结构的各节点之间导航。例
如导航到当前节点的父节点、兄弟节点、子节点等都是比较方便的,这样就可以轻易地获取到
自己需要的数据,也可以很容易地添加和修改树中的元素。因为要将整个XML 文档加载到内
存中井构造树形结构,当XML 文档的数据量较大时,会造成较大的资源消耗。
SAX
SAX 是基于事件模型的XML 解析方式,它并不需要将整个XML 文档加载到内存中,而
只需将XML 文档的一部分加载到内存中,即可开始解析,在处理过程中井不会在内存中记录
XML 中的数据,所以占用的资源比较小。当程序处理过程中满足条件时,也可以立即停止解析
过程,这样就不必解析剩余的XML内容。
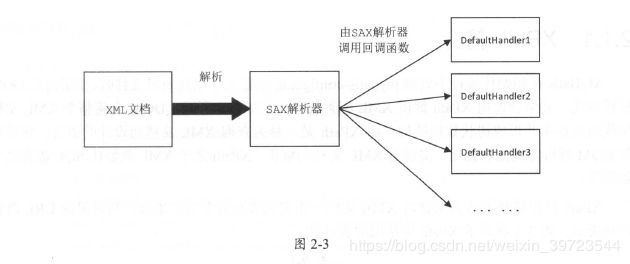
当SAX 解析器解析到某类型节点时,会触发注册在该类型节点上的回调函数,开发人员可
以根据自己感兴趣的事件注册相应的回调函数。一般情况下,开发人员只需继承SAX 提供的
DefaultHandler 基类,重写相应事件的处理方法并进行注册即可。如图2-3 所示,事件是由解析
器产生并通过回调函数发送给应用程序的,这种模式我们也称为“推模式”。
SAX 的缺点也非常明显,因为不存储XML 文挡的结构,所以需要开发人员自己负责维护
业务逻辑涉及的多层节点之间的关系,例如,某节点与其父节点之间的父子关系、与其子节点
之间的父子关系。当XML 文档非常复杂时,维护节点间关系的复杂度较高,工作量也就会比
较大。另一方面,因为是流式处理,所以处理过程只能从XML 文档开始向后单向进行, 无法
像DOM 方式那样, 自由导航到之前处理过的节点上重新处理,也无法支持XPath 。SAX 没有
提供写XML 文档的功能。
StAX
JAXP 是JDK 提供的一套用于解析XML 的API , 它很好地支持DOM 和SAX 解析方式,
JAXP 是JavaSE 的一部分,它由javax.xml 、org.w3c . dom 、org 且nl.sax 包及其子包组成。从JDK
6 . 0 开始, JAXP 开始支持另一种XML 解析方式,也就是下面要介绍的S 民X 解析方式。
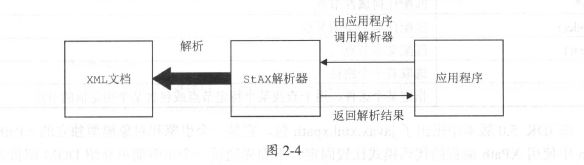
StAX解析方式与SAX 解析方式类似,它也是把XML 文档作为一个事件流进行处理,但
不同之处在于StAX 采用的是“拉模式” 。所谓唯模式”是应用程序通过调用解析器推进解析
的进程,如图2-4 所示。在StAX 解析方式中,应用程序控制着整个解析过程的推进,可以简
化应用处理XML 文档的代码,并且决定何时停止解析,而且StAX 可以同时处理多个XML 文
档。
StAX 实际上包括两套处理XML 文档的API ,分别提供了不同程度的抽象。一种是基于指
针的API ,这是一种低层API ,效率高但抽象程度较低。另一种API 是基于迭代器的API ,它
允许应用程序把XML 文档作为一系列事件对象来处理,效率较略低但抽象程度较高。
本节只是对常见的XML 解析方式做简单介绍,帮助读者快速入门,感兴趣的读者可以查
阅相关材料进行学习。
2.1.1 XPath 简介
MyBatis 在初始化过程中处理mybatis-config.xml配置文件以及映射文件时,使用的是DOM
解析方式,井结合使用XPath 解析XML 配置文件。正如前文所述, DOM 会将整个XML 文档
加载到内存中并形成树状数据结构,而XPath 是一种为查询XML 文档而设计的语言,它可以
与DOM 解析方式配合使用,实现对XML 文档的解析。XPath 之于XML 就好比SQL 语言之于
数据库。
XPath 使用路径表达式来选取XML 文档中指定的节点或者节点集合,与常见的URL 路径
有些类似。表2 -1 展示了XPath 中常用的表达式。

在JDK 5.0 版本中推出了javax.xml.xpath 包,它是一个引擎和对象模型独立的XPath 库。
Java 中使用XPath 编程的代码模式比较固定,下面先通过一个示例简单介绍DOM 解析方式和
XPath 库的使用方式。在该示例中,解析前面介绍的inventory.xml 文挡,井查找作者为Neal
Stephenson 所有书籍的标题。
首先,我们需要构造该查询对应的XPath 表达式。查找所有书籍的XPath 表达式是:”//book” 。
查找作者为Neal Stephenson 的所有图书需要指定<author>节点的值,得到表达式:
” //book[author= ’Neal Stephenson ’]” 。为了找出这些图书的标题,需要选取<title >节点,得到表达
式:”//book[author=’Neal Stephenson’]/title” 。最后,真正需要的信息是<title >节点中的文本节点,
得到的完整XPath 表达式是:”//book[author=”Neal Stephenson ”]/title/text” 。
实例如下:
public static void main(String[] args) throws Exception {
DocumentBuilderFactory documentBuilderFactory = DocumentBuilderFactory.newInstance();
// 开启验证
documentBuilderFactory.setValidating(true);
documentBuilderFactory.setNamespaceAware(false);
documentBuilderFactory.setIgnoringComments(true);
documentBuilderFactory.setIgnoringElementContentWhitespace(false);
documentBuilderFactory.setCoalescing(false);
documentBuilderFactory.setExpandEntityReferences(true);
DocumentBuilder documentBuilder = documentBuilderFactory.newDocumentBuilder();
documentBuilder.setErrorHandler(new ErrorHandler() {
@Override
public void warning(SAXParseException exception) throws SAXException {
System.out.println("error : " + exception.getMessage());
}
@Override
public void error(SAXParseException exception) throws SAXException {
System.out.println("error : " + exception.getMessage());
}
@Override
public void fatalError(SAXParseException exception) throws SAXException {
System.out.println("error : " + exception.getMessage());
}
});
// 將一个文档添加到document对象中去
Document document = documentBuilder.parse("src/main/java/com/gyoomi/base/xpath/inventory.xml");
XPathFactory xPathFactory = XPathFactory.newInstance();
XPath xPath = xPathFactory.newXPath();
// 编译XPath表达式
XPathExpression expr = xPath.compile("//book[author='Neal Stephenson']/title/text()");
// 通过XPath 表达式得到结采,第一个参数指定了XPath 表达式进行查询的上下文节点,也就是在指定
// 节点下查找符合XPath 的节点。本例中的上下文节点是整个文档;第二个参数指定了XPath 表达式
// 的返回类型
Object result = expr.evaluate(document, XPathConstants.NODESET);
System.out.println("查询作者为Neal Stephenson 的图书的标题:");
NodeList list = (NodeList) result;
for (int i = 0; i < list.getLength(); i++) {
System.out.println(list.item(i).getNodeValue());
}
}
注意XPathExpression.evaluate()方法的第二参数,它指定了XPath表达式查找的结果类型,
在XPathConstants类中提供了nodeset、boolean 、number、string 和Node 五种类型。
另外,如果XPath表达式只使用一次, 可以跳过编译步骤直接调用XPath 对象的evaluate()
方法进行查询。但是如果同一个XPath 表达式要重复执行多次,则建议先进行编译,然后进行
查询,这样性能会好一点。
2.1.2 XPathParse
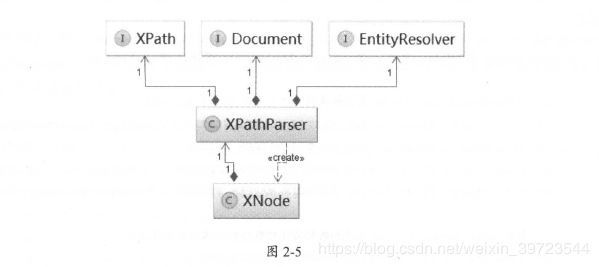
MyBatis 提供的XPathParser类封装了前面涉及的XPath、Document和EntityResolver ,如图
2-5 所示。
XPathParser 中各个字段的含义和功能如下所示。
// Document對象
private final Document document;
// 是否开启验证
private boolean validation;
// 用于加载本地DTD约束文件
private EntityResolver entityResolver;
// mybatis-config.xml中<propteries> 标签定义的键位对集合
private Properties variables;
// XPath 对象
private XPath xpath;
EntityResolver
默认情况下,对XML文档进行验证时,会根据XML 文档开始位置指定的网址加载对应的
DTD 文件或XSD 文件。如果解析mybatis-config.xml 配置文件,默认联网加载
http://mybatis.org/dtd/mybatis-3-config.dtd 这个DTD 文档,当网络比较慢时会导致验证过程缓慢。
在实践中往往会提前设置EntityResolver 接口对象加载本地的DTD 文件,从而避免联网加载
DTD 文件。XMLMapperEntityResolver 是My Batis提供的EntityResolver 接口的实现类,如图2-6
所示。
Entity Resolver 接口的核心是resolveEntity()方法, XMLMapperEntityResolver 的实现如下
所示。
public class XMLMapperEntityResolver implements EntityResolver {
// 指定mybatis-config.xml文件和映射文件对反的DTD的Systemid
private static final String IBATIS_CONFIG_SYSTEM = "ibatis-3-config.dtd";
private static final String IBATIS_MAPPER_SYSTEM = "ibatis-3-mapper.dtd";
private static final String MYBATIS_CONFIG_SYSTEM = "mybatis-3-config.dtd";
private static final String MYBATIS_MAPPER_SYSTEM = "mybatis-3-mapper.dtd";
//指定mybatis - config.xm 文件和映射文件对应的DTD文件的具体位置
private static final String MYBATIS_CONFIG_DTD = "org/apache/ibatis/builder/xml/mybatis-3-config.dtd";
private static final String MYBATIS_MAPPER_DTD = "org/apache/ibatis/builder/xml/mybatis-3-mapper.dtd";
// resolveEntity是EntityResolver接口中定义的方法,具体实现如下:
@Override
public InputSource resolveEntity(String publicId, String systemId) throws SAXException {
try {
if (systemId != null) {
// 查找SystemId指定的DTD文件,并调用getInputStream()来读取文件
String lowerCaseSystemId = systemId.toLowerCase(Locale.ENGLISH);
if (lowerCaseSystemId.contains(MYBATIS_CONFIG_SYSTEM) || lowerCaseSystemId.contains(IBATIS_CONFIG_SYSTEM)) {
return getInputSource(MYBATIS_CONFIG_DTD, publicId, systemId);
} else if (lowerCaseSystemId.contains(MYBATIS_MAPPER_SYSTEM) || lowerCaseSystemId.contains(IBATIS_MAPPER_SYSTEM)) {
return getInputSource(MYBATIS_MAPPER_DTD, publicId, systemId);
}
}
return null;
} catch (Exception e) {
throw new SAXException(e.toString());
}
}
// 负责读取DTD文档并生成InputStream对象
private InputSource getInputSource(String path, String publicId, String systemId) {
InputSource source = null;
if (path != null) {
try {
InputStream in = Resources.getResourceAsStream(path);
source = new InputSource(in);
source.setPublicId(publicId);
source.setSystemId(systemId);
} catch (IOException e) {
// ignore, null is ok
}
}
return source;
}
}
XPathParser
介绍完XMLMapperEntityResolver 之后,回到对XPathParser 的分析。在XPathParser.
createDocument()方法中封装了前面介绍的创建Document 对象的过程并触发了加载XML 文挡的
过程,具体实现如下:
public XPathParser(InputStream inputStream) {
commonConstructor(false, null, null);
this.document = createDocument(new InputSource(inputStream));
}
private void commonConstructor(boolean validation, Properties variables, EntityResolver entityResolver) {
this.validation = validation;
this.entityResolver = entityResolver;
this.variables = variables;
XPathFactory factory = XPathFactory.newInstance();
this.xpath = factory.newXPath();
}
// 调用createDocument()方法之前一定要先调用commonConstructor()方法完成初始化
private Document createDocument(InputSource inputSource) {
try {
// 创建DocumentBuilderFactory对象
DocumentBuilderFactory factory = DocumentBuilderFactory.newInstance();
// ...对DocumentBuilderFactory对象进行一系列配置,省略代码
DocumentBuilder builder = factory.newDocumentBuilder();
// 设置EntityResolver接口对象
builder.setEntityResolver(entityResolver);
// 实现其中的ErrorHandler,大部分都是空实现
builder.setErrorHandler(new ErrorHandler() {
@Override
public void error(SAXParseException exception) throws SAXException {
throw exception;
}
@Override
public void fatalError(SAXParseException exception) throws SAXException {
throw exception;
}
@Override
public void warning(SAXParseException exception) throws SAXException {
}
});
return builder.parse(inputSource);
} catch (Exception e) {
throw new BuilderException("Error creating document instance. Cause: " + e, e);
}
}
XPathParser 中提供了一系列的eval *()方法用于解析boolean 、short、long 、int 、String 、Node
等类型的信息,它通过调用前面介绍的XPath.evaluate()方法查找指定路径的节点或属性,并进
行相应的类型装换。具体代码比较简单,就不贴出来了。这里需要注意的是
XPathParser.evalString()方法,其中会调用PropertyParser.parse()方法处理节点中相应的默认值。
具体实现如下:
public String evalString(Object root, String expression) {
String result = (String) evaluate(expression, root, XPathConstants.STRING);
result = PropertyParser.parse(result, variables);
return result;
}
PropertyParser
在PropertyParser 中指定了是否开启使用默认值的功能以及默认的分隔符,相关字段如下
所示。
public class PropertyParser {
private static final String KEY_PREFIX = "org.apache.ibatis.parsing.PropertyParser.";
// 在mybatis-config.xml中节点下配置是否开启默认功能相应的配置项
public static final String KEY_ENABLE_DEFAULT_VALUE = KEY_PREFIX + "enable-default-value";
// 配置占位符和默认值之间的分隔符对应的配置项
public static final String KEY_DEFAULT_VALUE_SEPARATOR = KEY_PREFIX + "default-value-separator";
// 默认情况下,关闭默认值功能
private static final String ENABLE_DEFAULT_VALUE = "false";
// 默认分割符是冒号
private static final String DEFAULT_VALUE_SEPARATOR = ":";
}
PropertyParser.parse()方法如下:
public static String parse(String string, Properties variables) {
VariableTokenHandler handler = new VariableTokenHandler(variables);
// 创建GenericTokenParser对象,并指定处理${}样式的占位符
GenericTokenParser parser = new GenericTokenParser("${", "}", handler);
return parser.parse(string);
}
GenericTokenParser
GenericTokenParser 是一个通用的的占位符解析器,其宇段的含义如下:
// 占位符开始的标记
private final String openToken;
// 占位符结束的标记
private final String closeToken;
// TokenHandler会按照一定的逻辑解析占位符
private final TokenHandler handler;
public GenericTokenParser(String openToken, String closeToken, TokenHandler handler) {
this.openToken = openToken;
this.closeToken = closeToken;
this.handler = handler;
}
GenericTokenParser.parse()方法的逻辑并不复杂,它会顺序查找openToken 和closeToken,
解析得到占位符的字面值,并将其交给TokenHandler处理,然后将解析结果重新拼装成字符串
井返回。该方法的实现如下:
public String parse(String text) {
// .... 检测text是否为空(略)
// 查找开始标志
int start = text.indexOf(openToken, 0);
if (start == -1) {
return text;
}
char[] src = text.toCharArray();
int offset = 0;
// 用来记录解析后的字符串结果
final StringBuilder builder = new StringBuilder();
// 用来记录一个占位符的字面值
StringBuilder expression = null;
while (start > -1) {
if (start > 0 && src[start - 1] == '\\') {
// this open token is escaped. remove the backslash and continue.
// 遇到转义的开始标记,则直接将前面的字符串以及开始标记追加到builder中
builder.append(src, offset, start - offset - 1).append(openToken);
offset = start + openToken.length();
} else {
// 查找到开始标志,且未转义
if (expression == null) {
expression = new StringBuilder();
} else {
expression.setLength(0);
}
// 将前面的字符追加到builder中
builder.append(src, offset, start - offset);
offset = start + openToken.length();
int end = text.indexOf(closeToken, offset);
while (end > -1) {
if (end > offset && src[end - 1] == '\\') {
// 处理转义的结束标记
// this close token is escaped. remove the backslash and continue.
expression.append(src, offset, end - offset - 1).append(closeToken);
offset = end + closeToken.length();
end = text.indexOf(closeToken, offset);
} else {
// 将开始标志和结束标志之间的内容拼接到expression中去
expression.append(src, offset, end - offset);
offset = end + closeToken.length();
break;
}
}
// 未找到结束标记
if (end == -1) {
// close token was not found.
builder.append(src, start, src.length - start);
offset = src.length;
} else {
// 将占位符的字面值交给TokenHandler 处理,并将处理结果追加到builder 中保存,/最终拼凑出解析后的完整内容
builder.append(handler.handleToken(expression.toString()));
offset = end + closeToken.length();
}
}
// 移动start的位置
start = text.indexOf(openToken, offset);
}
if (offset < src.length) {
builder.append(src, offset, src.length - offset);
}
return builder.toString();
}
占位符由TokenHandler 接口的实现进行解析, TokenHandler 接口总共有四个实现,图2-7
所示。

通过对PropertyParser.parse()方法的介绍,我们知道PropertyParser是使用VariableTokenHandler与GenericTokenParser 配合完成占位符解析的。VariableTokenHandler 是PropertyParser
中的一个私有静态内部类,其字段的含义如下:
// mybatis-config.xml中节点下定义的键位对,用于替换占位符
private final Properties variables;
// 是否支持占位符中使用默认值的功能
private final boolean enableDefaultValue;
// 指定占位符和默认值之间的分隔符
private final String defaultValueSeparator;
VariableTokenHandler 实现了TokenHandler 接口中的handleToken ()方法,该实现首先会按照
defaultValueSeparator 宇段指定的分隔符对整个占位符切分, 得到占位符的名称和默认值,然后
按照切分得到的占位符名称查找对应的值, 如果在<properties>节点下未定义相应的键值对,则
将切分得到的默认值作为解析结果返回。
@Override
public String handleToken(String content) {
// 检测variables集合是否为null
if (variables != null) {
String key = content;
// 检测是否支持占位符中使用默认值的功能
if (enableDefaultValue) {
final int separatorIndex = content.indexOf(defaultValueSeparator);
String defaultValue = null;
if (separatorIndex >= 0) {
key = content.substring(0, separatorIndex);
// 获取默认值
defaultValue = content.substring(separatorIndex + defaultValueSeparator.length());
}
if (defaultValue != null) {
return variables.getProperty(key, defaultValue);
}
}
// 如果已配置该变量,则会覆盖默认值
if (variables.containsKey(key)) {
return variables.getProperty(key);
}
}
return "${" + content + "}";
}
这里通过一个示例解释PropertyParser 的工作原理,在该示例中配置的数据库用户名为
‘${username:root}’,其中,是占位符和默认值的分隔符。PropertyParser会在解析后使用username在variables 集合中查找相应的值,如果查找不到,则使用root作为数据库用户名的默
认值。
需要注意的是,GenericTokenParser 不仅仅用于这里的默认值解析,还会用于后面对动态
SQL语句的解析。很明显, GenericTokenParser 只是查找到指定的占位符, 而具体的解析行为会
根据其持有的TokenHandler 实现的不同而有所不同, 这有点策略模式的意思,策略模式在后面
会详细介绍。
回到对XPathParser的分析, XPathParser.evalNode()方法返回值类型是XNode ,它对
org.w3c.dom.Node 对象做了封装和解析,其各个字段的含义如下:
public class XNode {
// org.w3c.dom.Node 对象
private final Node node;
// Node 节点名称
private final String name;
// 节点的内容
private final String body;
// 节点属性集合
private final Properties attributes;
// mybatis-config.xml配置文件中< properties>节点下定义的键位对
private final Properties variables;
// 前面介绍的XPathParser 对象,该XNode对象由此XPathParser 对象生成
private final XPathParser xpathParser;
public XNode(XPathParser xpathParser, Node node, Properties variables) {
this.xpathParser = xpathParser;
this.node = node;
this.name = node.getNodeName();
this.variables = variables;
this.attributes = parseAttributes(node);
this.body = parseBody(node);
}
private Properties parseAttributes(Node n) {
Properties attributes = new Properties();
NamedNodeMap attributeNodes = n.getAttributes();
if (attributeNodes != null) {
for (int i = 0; i < attributeNodes.getLength(); i++) {
Node attribute = attributeNodes.item(i);
String value = PropertyParser.parse(attribute.getNodeValue(), variables);
attributes.put(attribute.getNodeName(), value);
}
}
return attributes;
}
private String parseBody(Node node) {
String data = getBodyData(node);
if (data == null) {
NodeList children = node.getChildNodes();
for (int i = 0; i < children.getLength(); i++) {
Node child = children.item(i);
data = getBodyData(child);
if (data != null) {
break;
}
}
}
return data;
}
private String getBodyData(Node child) {
if (child.getNodeType() == Node.CDATA_SECTION_NODE
|| child.getNodeType() == Node.TEXT_NODE) {
String data = ((CharacterData) child).getData();
data = PropertyParser.parse(data, variables);
return data;
}
return null;
}
// ...省略其他无关代码
}
XNode的构造函数中会调用其parseAttributes() 方法和parseBody()方法解析org.w3 c.dom.Node 对象中的信息,初始化attributes 集合和body 字段,具体初始化过程如下:
private Properties parseAttributes(Node n) {
Properties attributes = new Properties();
// 获取节点的属性集合
NamedNodeMap attributeNodes = n.getAttributes();
if (attributeNodes != null) {
for (int i = 0; i < attributeNodes.getLength(); i++) {
Node attribute = attributeNodes.item(i);
// 使用PropertyParser 处理每个属性中的占位符
String value = PropertyParser.parse(attribute.getNodeValue(), variables);
attributes.put(attribute.getNodeName(), value);
}
}
return attributes;
}
private String parseBody(Node node) {
String data = getBodyData(node);
// 当前节点不是文本节点
if (data == null) {
// 处理子节点
NodeList children = node.getChildNodes();
for (int i = 0; i < children.getLength(); i++) {
Node child = children.item(i);
data = getBodyData(child);
if (data != null) {
break;
}
}
}
return data;
}
private String getBodyData(Node child) {
if (child.getNodeType() == Node.CDATA_SECTION_NODE
|| child.getNodeType() == Node.TEXT_NODE) { // 只处理文本内容
String data = ((CharacterData) child).getData();
// 使用PropertyParser 处理文本节点中的占位符
data = PropertyParser.parse(data, variables);
return data;
}
return null;
}
XNode中提供了多种get*O 方法获取所需的节点信息,这些信息主要来自上面介绍的
attribute 集合、body 字段、node 字段,这些方法比较简单,就不再贴出来了, 请读者参考源码。
另外,我们也可以使用XNode.eval *()方法结合XPath 查询需要的信息, eval *()系列方法是通过
调用其封装的XPathParser 对象的eval *()方法实现的。这里要注意的是, eval *()系列方法的上下
文节点是当前的刀叫XNode.node ,也就是查找该节点下的符合XPath 表达式的信息。