HA高可用hadoop3.1.1集群搭建
有了前面全分布式部署的基础:https://blog.csdn.net/weixin_40096730/article/details/88692579
现在开始进行HA高可用集群搭建!
背景
在Hadoop 2.0.0之前,NameNode是HDFS集群中的单点故障(SPOF)。每个群集都有一个NameNode,如果该机器或进程变得不可用,整个群集将无法使用,直到NameNode重新启动或在单独的计算机上启动。
这在两个主要方面影响了HDFS集群的总体可用性:
-
对于计划外事件(例如计算机崩溃),在操作员重新启动NameNode之前,群集将不可用。
-
计划维护事件(如NameNode计算机上的软件或硬件升级)将导致群集停机时间窗口。
HDFS高可用性功能通过提供在具有热备用的主动/被动配置中的同一群集中运行两个(以及3.0.0多于两个)冗余NameNode的选项来解决上述问题。这允许在机器崩溃的情况下快速故障转移到新的NameNode,或者为了计划维护而优雅地管理员启动的故障转移。
架构
在典型的HA群集中,两个或多个单独的计算机配置为NameNode。在任何时间点,其中一个NameNode处于活动状态,而其他NameNode 处于待机状态。Active NameNode负责集群中的所有客户端操作,而Standbys只是充当工作者,维持足够的状态以在必要时提供快速故障转移。
为了使备用节点保持其状态与Active节点同步,两个节点都与一组称为“JournalNodes”(JN)的单独守护进程通信。当Active节点执行任何名称空间修改时,它会将修改记录持久地记录到大多数这些JN中。待机节点能够从JN读取编辑,并且不断观察它们对编辑日志的更改。当备用节点看到编辑时,它会将它们应用到自己的命名空间。如果发生故障转移,Standby将确保在将自身升级为Active状态之前已从JournalNodes读取所有编辑内容。这可确保在发生故障转移之前完全同步命名空间状态。
为了提供快速故障转移,备用节点还必须具有关于群集中块的位置的最新信息。为了实现这一点,DataNode配置了所有NameNode的位置,并向所有人发送块位置信息和心跳。
对于HA群集的正确操作而言,一次只有一个NameNode处于活动状态至关重要。否则,命名空间状态将在两者之间快速分歧,冒着数据丢失或其他不正确结果的风险。为了确保这个属性并防止所谓的“裂脑情景”,JournalNodes只允许一个NameNode一次成为一个作家。在故障转移期间,要激活的NameNode将简单地接管写入JournalNodes的角色,这将有效地阻止其他NameNode继续处于Active状态,从而允许新的Active安全地进行故障转移。
硬件资源
要部署HA群集,您应准备以下内容:
-
NameNode计算机 - 运行Active和Standby NameNode的计算机应具有彼此相同的硬件,以及与非HA集群中使用的硬件等效的硬件。
-
JournalNode计算机 - 运行JournalNodes的计算机。JournalNode守护程序相对轻量级,因此这些守护程序可以合理地与其他Hadoop守护程序并置在机器上,例如NameNodes,JobTracker或YARN ResourceManager。注意:必须至少有3个JournalNode守护进程,因为编辑日志修改必须写入大多数JN。这将允许系统容忍单个机器的故障。您也可以运行3个以上的JournalNodes,但为了实际增加系统可以容忍的失败次数,您应该运行奇数个JN(即3,5,7等)。请注意,当使用N JournalNodes运行时,系统最多可以容忍(N-1)/ 2个故障并继续正常运行。
请注意,在HA群集中,备用NameNode还会执行命名空间状态的检查点,因此无需在HA群集中运行Secondary NameNode,CheckpointNode或BackupNode。事实上,这样做会是一个错误。这还允许正在重新配置启用HA的HDFS群集的人员启用HA,以重用他们之前专用于Secondary NameNode的硬件。
配置
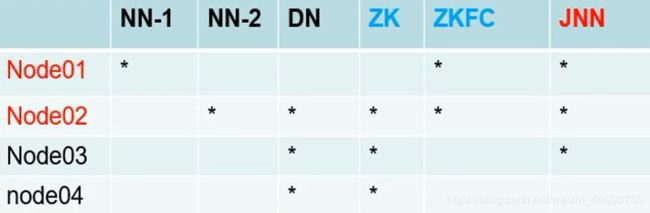
配置规则:
node01:namenode、ZKFC(与namenode绑定在一起)
node02:namenode、datanode、zookeeper、ZKFC(与namenode绑定在一起)、journalnode
node03:datanode、zookeeper、journalnode
node04:datanode、zookeeper、journalnode
Hadoop配置:
一.在/usr/local/hadoop/hadoop-3.1.1/etc/hadoop目录修改vim hadoop-env.sh添加以下几行:
export JAVA_HOME=/usr/java/default
export HADOOP_HOME=/usr/local/hadoop/hadoop-3.1.1
HDFS_DATANODE_USER=root
HDFS_NAMENODE_USER=root
export HDFS_ZKFC_USER=root
export HDFS_JOURNALNODE_USER=root
二.在/usr/local/hadoop/hadoop-3.1.1/etc/hadoop目录修改vim hdfs-site.xml修改配置文件:
dfs.replication
2
dfs.nameservices
mycluster
dfs.ha.namenodes.mycluster
nn1,nn2
dfs.namenode.rpc-address.mycluster.nn1
node01:8020
dfs.namenode.rpc-address.mycluster.nn2
node02:8020
dfs.namenode.http-address.mycluster.nn1
node01:9870
dfs.namenode.http-address.mycluster.nn2
node02:9870
dfs.namenode.shared.edits.dir
qjournal://node01:8485;node02:8485;node03:8485/mycluster
dfs.client.failover.proxy.provider.mycluster
org.apache.hadoop.hdfs.server.namenode.ha.ConfiguredFailoverProxyProvider
dfs.ha.fencing.methods
sshfence
dfs.ha.fencing.ssh.private-key-files
/root/.ssh/id_rsa
dfs.journalnode.edits.dir
/var/log/hadoop/ha/journalnode
dfs.ha.automatic-failover.enabled
true
三.在/usr/local/hadoop/hadoop-3.1.1/etc/hadoop目录修改vim core-site.xml修改配置文件:
fs.defaultFS
hdfs://mycluster
hadoop.tmp.dir
/var/log/hadoop/ha
ha.zookeeper.quorum
node02:2181,node03:2181,node04:2181
hadoop.http.staticuser.user
root
四.在/usr/local/hadoop/hadoop-3.1.1/etc/hadoop目录查看cat workers配置文件是否添加好节点:
node02
node03
node04
至此可以将配置好的这三个配置文件分发至其他节点了。
ZooKeeper安装:node02、node03、node04
1.下载zookeeper安装包,我下的版本是zookeeper-3.4.6.tar.gz
2.解压到/usr/local/zookeeper目录下
3.修改环境变量vim /etc/profile
export JAVA_HOME=/usr/java/default
export HADOOP_HOME=/usr/local/hadoop/hadoop-3.1.1
export ZOOKEEPER_HOME=/usr/local/zookeeper/zookeeper-3.4.6
export PATH=$PATH:JAVA_HOME/bin:$HADOOP_HOME/bin:$HADOOP_HOME/sbin:$ZOOKEEPER_HOME/bin
4.分发给node03、node04
5.配置后,执行source /etc/profile使配置生效
6.修改ZooKeeper配置项,在 /usr/local/zookeeper/zookeeper-3.4.6/conf/ 下,将 zoo_sample.cfg 改名为 zoo.cfg
7.vim zoo.cfg
# 将保存路径从临时目录变更自定义目录
dataDir=/usr/local/zkdata
# 最后再添加以下配置
server.1=node02:2888:3888
server.2=node03:2888:3888
server.3=node04:2888:3888
8.配置好了之后将 /usr/local/zookeeper/zookeeper-3.4.6/分发给node03、node04
9.在四个节点(至少在node02,node03,node04上要有)上创建ZooKeeper数据保存目录mkdir /usr/local/zkdata
10.创建myid
node02:执行echo 1 > /usr/local/zkdata/myid
node03:执行echo 2 > /usr/local/zkdata/myid
node04:执行echo 3 > /usr/local/zkdata/myid
11.运行ZooKeeper
zkServer.sh start 启动
zkServer.sh stop 停止
zkServer.sh status 查看状态如下图即成功了!
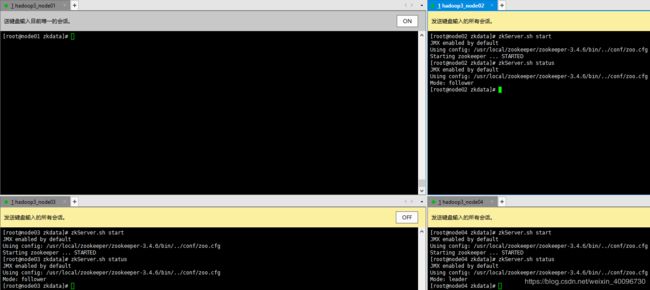
其中node04的Mode:leader。node03和node04的Mode:follower
原因:选举机制,myid最大,则机会更大。有主节点了,即使myid再大也没反应了。
12.通过客户端运行ZooKeeper
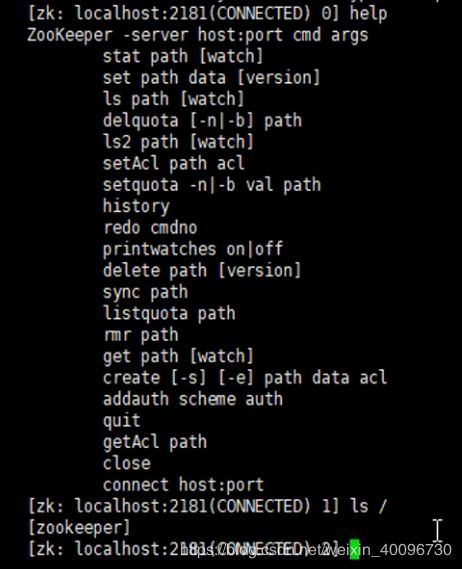
zkCli.sh 运行客户端
namenode同步穿透
1.首先在node01,node02,node03启动journalnode
hdfs --daemon start journalnode2.然后对namenode进行格式化,node01和node02机器任选一台。我用的node01
hdfs namenode -format3.格式成功,查看配置信息

4.将node01上的namenode启动--必要!!否则无法进行同步
hadoop-daemon.sh start namenode5.然后在node02上进行同步
hdfs namenode -initializeSharedEdits6.同步成功,查看node02配置信息,与node01应一致!
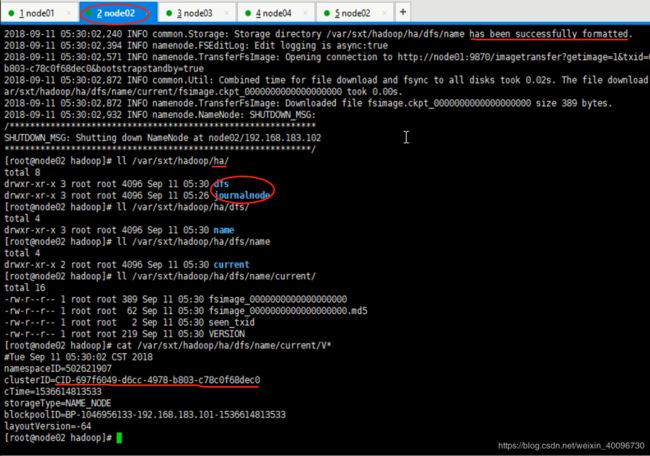
格式化ZooKeeper
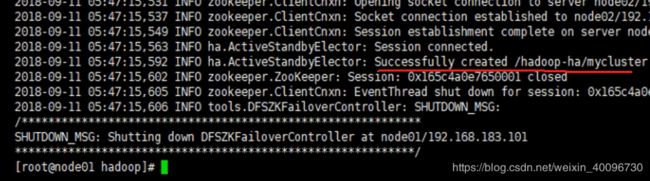
1.在zookeeper已经启动的前提下格式化,在node01上执行:
hdfs zkfc -formatZK如图,格式化成功!
并且在node02下的zkCli.sh客户端查看已经多了hadoop-ha目录

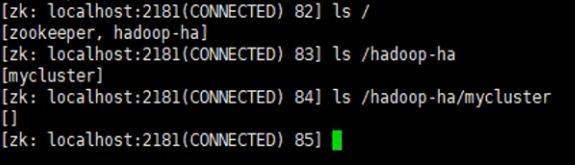
该目录存储namenode注册信息,注册上的节点为active,没有则是standby
启动hadoop集群
1.在node01上执行
start-dfs.sh如图:

2.查看运行jps
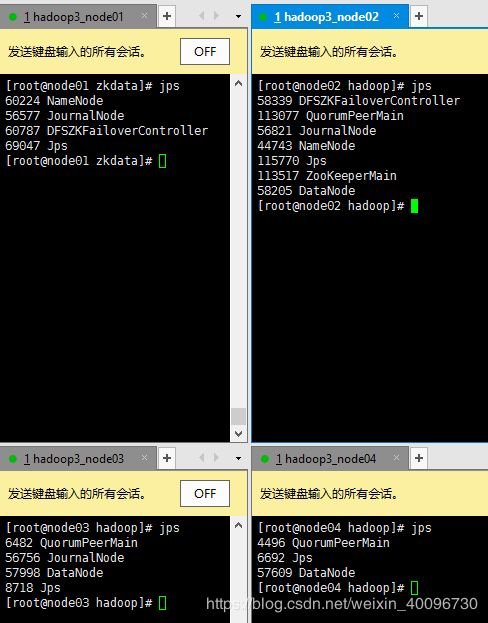
3.在node02的zookeeper客户端下查看信息
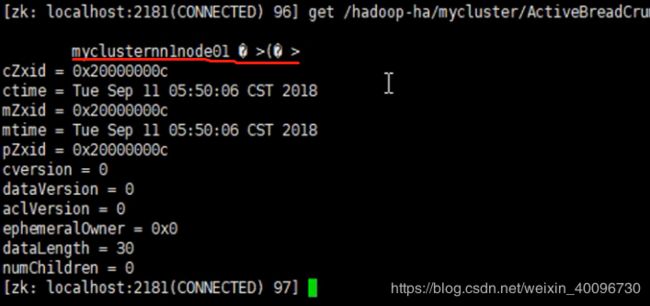
此时node01的namenode为active,而node02的namenode为standby

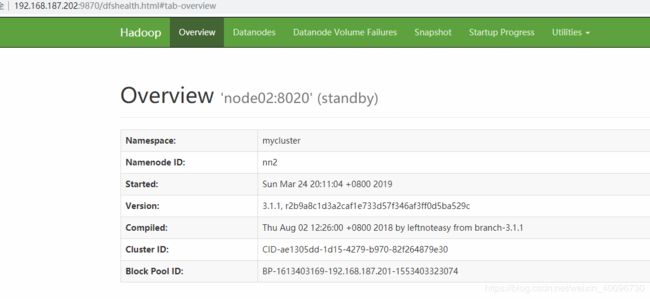
关闭node01上的namenode测试一下,是否node02的name变为active,变化成功即正常!
重新启动node01的namenode
再关闭node02上的zkfc测试一下,是否node01的name变为active,变化成功即正常!
hdfs --daemon stop zkfc重新启动好zkfc。
至此高可用集群搭建完成!