第一章:知识图谱概述
目录
Part One. 什么是知识图谱?
1.人工智能的三个阶段
2.数据、信息和知识之间的关系
3.什么是知识库?
4.知识工程
5.大数据知识工程
6.知识图谱中图的结构
7.知识图谱是大数据知识工程的高效模型
Part Two.知识图谱的发展历程
1.知识图谱与互联网:万维网
Part Three.知识图谱的类型和代表性知识图谱
1.词语/实体/关系/属性
2.Ontology vs. Knowledge Base vs. Database
3.Formal Ontology vs. Lightweight Ontology
4.Ontology vs. Taxonomy vs. Folksonomy
5.知识图谱的类型以及代表性知识图谱
Part Four.知识图谱的生命周期
1.知识本体构建
2.知识获取
3.知识融合
4.知识存储和查询
5.知识推理
6.知识应用
Part Five.知识图谱和深度学习
1.符号表示和数值表示
Part Six.总结
Part One. 什么是知识图谱?
1.人工智能的三个阶段
Stage1:
计算智能
--->计算机具备与人脑一样的运算和存储的能力
Stage2:
感知智能
--->感知是人和动物通过感觉器官与自然界进行交互的能力,例如:模式识别的图像/音频识别等都属于感知智能
Stage3:
认知智能
--->特指人在感知世界以及人与人互动的过程中形成的、对世界万物的理性认识,包括记忆、概括、推理等
知识图谱是人工智能的一个分支
2.数据、信息和知识之间的关系
数据:反映客观事物运动状态的感知信号,是符号、文字 、数字等,未经加工和解释,与其他数据没有联系,
因此
不具有语义,不能回答任何问题
信息:经过加工和解释,通过某种关联而
具有含义的数据
知识:经过挑选、改造形成的、
可以用于决策的、系统化的信息
知识是特殊的信息,信息是特殊的数据。知识工程的任务就是把数据和信息转化为知识
3.什么是知识库?
知识库:
在对各种知识进行收集和整理的基础上,进行形式化表示,按照一定方法存储,并提供相应的知识查询手段,就形成知识库。知识库是知识共享和应用的基础,
知识图谱是知识库的一种形式
。
4.知识工程
1977
年,在第五届国际人工智能会议上,美国斯坦福大学计算机科学家
费根鲍姆教授
发表特约文章“人工智能的艺术:知识工程课题及实例研究”,系统地阐述了“专家系统”的思想,并
提出了“知识工程”的概念,确定了知识在人工智能中的重要地位
。
5.大数据知识工程
结构化数据:即行数据,存储在数据库里,可以用二维表结构来逻辑表达实现的数据
非结构化数据:包括所有格式的办公文档、HTML、各类报表、图像和音频/视频信息等
数据全球每年暴增,其中非结构化数据占八层,这些数据需要得到合理化的使用,即我们需要对这些数据进行知识化,让计算机更加有效的管理和利用数据。知识图谱是大数据知识工程的一种形式。
6.知识图谱中图的结构
以
结构化三元组的形式存储现实世界中的实体及其关系
,表示为 ,
三元组
通常描述了一个特定领域中的事实,
由头实体
、
尾实体
和描述这两个实体之间的
关系
组成。
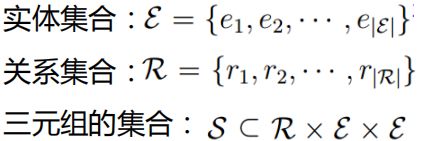
关系
有时也
称为属性
,
尾实体被称为属性值
。
从图结构的角度看,
实体是知识图谱中的节点
,
关系是连接两个节点的有向边
。
例如:WiKiData中的知识图谱:
圆圈里面的是实体,两个实体之间的有向边是关系

7.知识图谱是大数据知识工程的高效模型
结构化:图是一种能有效表示数据之间结构的表达形式,因此,
知识图谱可以很好建模大数据中蕴含的知识结构
。
关联化:可以
通过图中节点的关联和边的关联把多个来源的知识图谱自然地关联起来,从而实现知识融合
。
规范化:
结构化和关联化都采用统一的知识描述框架——语义网框架
,便于知识的分享与利用。
知识图谱:人工智能的重要基础设施:知识图谱以丰富的语义表示能力和灵活的结构构建知识的有效载体。
例如:下面实例中的知识图谱很好地建模大数据中蕴含的知识结构,并可以把知识图谱中蕴含的知识结构转化为语言表示。
Part Two.知识图谱的发展历程
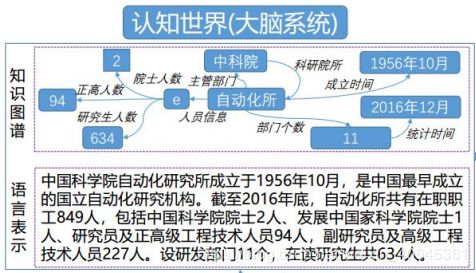
Stage1.1950-1970时代: 图灵测试===符号逻辑,神经网络,LISP,产生式规则、语义网络
Stage2.1970-1990时代:
专家系统===专家系统,限定领域,知识库+推理=智能,共同构建形成专家系统
Stage3.1990-2000时代:
web1代万维网===人工大规模知识库,本体概念,智能主体、机器人
Stage
4.2000-2006时代:
web2代群体智能
===简单万维网无法支持智能,所以出现群体智能
Stage5.2006- 现今时代:
web3代知识图谱===维基结构化,通用和领域知识,大规模知识获取
1.知识图谱与互联网:万维网
互联网的发展阶段:
World Wide Web (Web 1.0)、Social Web (Web 2.0)Semantic Web (Web 3.0)、Web Science
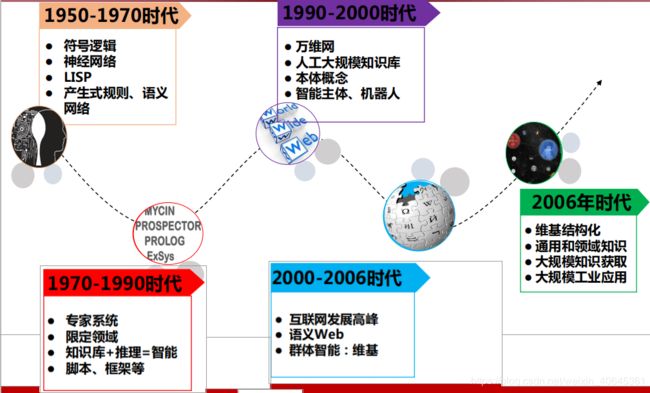
万维网:采用超文本标记语言HTML,Web内容没有采用形式化表示方式,缺乏明确的语义信息,是面向人的存储和共享信息的媒介,计算机信息查询和利用很困难。
语义网:是万维网的拓展和变革。它基于知识本体,对Web数据的内容进行了规范化的语义标注和关联,从而可以支持高效的机器信息共享和智能应用。语义网刚推出的十年间,并没有在实际中大规模应用,但其成果大力推动了使用本体模型和形式化手段表达数据 语义的方法的研究,为后续的知识图谱热潮奠定了基础。
人工智能:
知识的数据化
——让计算机表示、组织和存储人类的知识
语义网:
数据的知识化
——让数据支持推理等智能任务
知识图谱就是基于“语义网络”理论,
依据语义网
的技术框架和工程规范,对互联网数据进行知识化的一个知识工程产品。
Part Three.知识图谱的类型和代表性知识图谱
1.词语/实体/关系/属性
词语:word and phrases,用于描述实体、关系这些认知单元的语言单位。实体和关系是有确切含义的;
词语是有歧义的,在不同的语境中指称不同的实体或关系。
实体:entity,客观存在并可相互区别的事物,可以是具体的人、事、物,也可以是抽象的概念。
关系:relation,不同的实体之间各种联系。
Taxonomic Relation 分类关系
is-a
Hypernym-Hyponym
Non-taxonomic Relation非分类关系
Meoronymy 部分整体
Thematic roles 论旨角色
Attribute
属性
Possession 领属
Casuality 因果,等等
2.Ontology vs. Knowledge Base vs. Database
Ontology:本体,一套对客观世界进行描述的共享概念化体系。它对特定领域中概念(指事物的类型)及其相互关系进行形式化表达,重点是对
数据的定义进行描述
,而不是描述具体事物的
实例数据。
数据的定义进行描述:例如运动员有他自己的运动球队,这就是数据定义的描述;
实例数据:姚明有他术语NBA球队,这就是实例数据。也就是具体到每一个球员的年龄、性别等这是实例数据。
涉及
概念
、
关系
和
公理
三个要素
Knowledge Base:知识库,服从于ontology 控制的知识实例及其载体。例如姚明多少岁,属于哪个球队,就是实例数据
Database:数据库,计算机科学家为了用电脑表示和存储计算机应用中所需要的数据所设计开发的
这三个概念具有联系:例如做蛋糕的时候,蛋糕的磨具就是本体;做出来的一个蛋糕就是知识库;装蛋糕的盒子就是知识库。
3.Formal Ontology vs. Lightweight Ontology
Formal Ontology(形式化的本体): 大量使用公理的本体
Lightweight Ontology(轻量级的本体): 不用或很少使用公理的本体.(现在大多数使用的)
4.Ontology vs. Taxonomy vs. Folksonomy
Taxonomy:分类法,或称分类体系,是由专家编制的专业层次类别体系,如中图分类体系等。也有一些不严格的分类体系,通常由一些 组织为了自身需要而编制,如Yahoo分类目录等。
Ontology:本体,共享概念的规范。Ontology通常涵盖概念之间的分类体系,但是除此之外,更重要的是它还有概念之间的相关关系,如反向、传递、对称等,以及在此基础上建立的推理规则,从而支持复杂推理。由于具有严格的规范,一般用户难以构建。本体是一个领域共享的概念化规范(所谓概念指的是一类的事物)。举个例子:在金融领域,概念可以是实体类概念“上市 公司、董事、CEO”等,也可以是事件类概念“收购、拥有”等,那金融本体描述的范围就是:上市公司可以有董事、CEO等属性,上市公司可以收购另一家上市公司这样的关系,甚至是收购后就拥有了股份等规则。但这些都是在类别层的描述。相对应地,联想的CEO是柳传志,联想收购了IBM,就不是本体层的知识,而是实例层的事实。
Folksonomy:社会分类法,是由用户的自由标签自动形成的一种分类法,在对同一事物进行标签的所有标签中,取出高频标签作为分类标签。严格讲,是一种标签方法,并不一定构成一个分类体系。另一方面,标签具有随意性(歧义性)。
5.知识图谱的类型以及代表性知识图谱
语言知识图谱:WordNet
常识知识图谱:Cyc、ConceptNet、HowNet
百科知识图谱:DBpedia、Freebase、Google KG、Wikidata
语言+百科知识图谱:YAGO、BabelNet
领域知识图谱:
医学知识图谱 SIDER(Side Effect Resource)
电影知识图谱 IMDB (Internet Movie Database)
音乐知识图谱 MusicBrainz

Cyc:由专家构建,虽然准确,但是费时费力,规模和范围远远不够。
WordNet:采用人工标注方法,将英文单词按照其语义组成一个大的概念网络。词语被聚类成同义词集或上下位词集
FrameNet:具有层级的组织架构,位于最上层的节点表示框架,框架之间的边表示框架之间的关系。
描述词语之间的聚合语义是WordNet
描述词语之间的组合语义是FrameNet
知网:HowNet:区别于Wordnet,HowNet并不是将所有概念归结到一个树状的概念层次体系中,而是试图
用一系列的义原对每一个概
念进行描述,义原之间通过义原关系进行关联,从而使得HowNet是一个网状的知识系统,而不是一个简单的层级系统。义原:是用于描述一个概念的最小意义单位
ConceptNet:与Cyc是一个基于谓词逻辑的常识本体相比,ConceptNet采用词语关系三元组描述,形式较为简单。
更加接近WordNet,但是包含的关系类型更多,ConceptNet节点是词语,有些词语的歧义通过词性、类别等进行消除。
Wikipedia:前5个主要是人工做的,下边主要是机器自动做的
Wikipedia:前5个主要是人工做的,下边主要是机器自动做的
DBPedia:主要目标是构建一个社区,通过社区成员来定义和撰写准确的抽取模板,从维基百科中抽取结构信息,并将其发布到Web上。
YAGO:YAGO基于WordNet的知识体系,将 Wikipedia中的类别与 WordNet 中的类别进行关联,同时将Wikipedia 中的条目挂载到WordNet 的体系下。
BabelNet:与YAGO类似,BabelNet也是将维基百科链接到WordNet 上。但是 BabelNet 加入了多语言支持,目前覆盖 271种语言
Freebase:核心想法:在Wikipedia中,人们编辑文章;在Freebase中,人们编辑结构化知识。基于维基百科、使用
群体智能方法建立的完全结构化的知识资源。是公开可获取的规模最大的知识图谱之一。
Google:Knowledge Vault :2014 年创建的一个大规模知识图谱。相较于 Google 之前基于 Freebase 的知识图谱版本,
KnowledgeVault
不再采用众包方式进行图谱构建,而通过
机器学习方法自动搜集网上信息,并与已有的结构化数据进行融合,构建知识图谱。
KnowItAll:完全由机器构建,目标:让机器自动阅读互联网文本内容,从大量非结构化文本中抽取结构化的实体关系三元组信息。TextRunner和Reverb系统是 KnowItAll 项目中的两个代表系统。
NELL:也完全自动的。系统每天不间断地执行两项任务:阅读和学习。阅读任务从Web文本中获取三元组知识,并添加到内部知识库;学习任务目标是提升机器学习算法的性能。
Part Four.知识图谱的生命周期
Step1:知识本体构建:也叫知识建模;建模领域知识结构
Step2:
知识获取和验证:获取领域内的事实知识;估计知识的可信度
Step3:
知识融合:也叫知识集成;将多个来源的碎片知识组装成知识网络
Step4:
知识存储和查询:采用何种方式对知识图谱进行存储;采用何种方式对知识图谱进行查询
Step5:
知识推理:发现已有知识中隐含的知识
Step6:知识应用:提供高性能知识服务
1.知识本体构建
知识本体构建:指采用什么样的方式表达知识,其核心是构建一个本体对目标知识进行描述。该本体需要:
定义出知识的类别体系
每个类别下所属的实体和概念
某类概念和实体所具有的属性以及概念之间、实体之间的语义关系
定义在这个本体上的一些推理规则
作为语义网的应用,知识图谱的知识建模采用语义网的知识建模方式,分为概念、关系、概念关系三元组三个层次,并利用 “资源描述框架 (RDF)”进行描述。RDF 的基本数据模型包括了三个对象类型:
资源 (Resource)
能够使用 RDF 表示的对象称之为资源,包括互联网上的实体、事件和概念等。
谓词 (Predicate)
主要描述资源本身的特征和资源之间的关系。每一个谓词可以定义元知识,例如,谓词的头尾部数据值的类型(如定义域和值域)、谓词与其他谓词的关系(如逆关系)。该谓词所关联的头实体和尾实体的定义域和值域
陈述 (Statements)
一条陈述包含三个部分,通常称之为 RDF 三元组 < 主体 (subject),谓词 (predicate),宾语 (object)>。其中主体是被描述的资源,谓词可以表示主体的属性,也可以表示主体和宾语之间关系。当表示属性时,宾语就是属性值;当表示关系时,宾语也是一个资源。
2.知识获取
输入: 领域知识本体;海量数据:文本、垂直站点、百科
输出:实例知识;实体集合;实体关系/属性
主要技术:信息抽取;文本挖掘
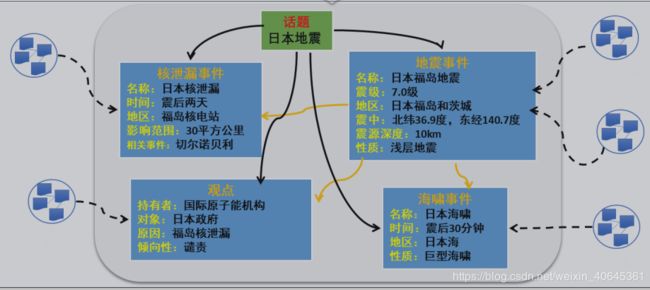
3.知识融合
任务:对不同来源、不同语言或不同结构的知识进行融合,从而对于已有知识图谱进行补充、更新和去重。
以下两个知识图谱在知识融合方面做的很优秀
YAGO :对专家构建的高质量语言知识图谱WordNet 和网民协同构建的大规模实体知识图谱 Wikipedia 进行融合而形成的,实现质量和数量的互补;
BabelNet :融合不同语言的知识图谱,实现跨语言的知识关联和共享。
从融合的对象看,可以分为知识本体融合和知识实例融合。
知识本体融合:两个或多个异构知识体系进行融合,即对相同的类别、属性、关系进行映射。
知识实例融合:对于两个不同知识图谱中的实例(实体实例、关系实例)进行融合,包括不同知识本体下的实例、不同语言的实例等
从融合的知识图谱类型看,可以分为:竖直方向的融合和水平方向的融合。
竖直方向的融合:融合(较)高层通用本体与(较)底层领域本体或实例数据。
上下位的挂接融合,融合 Wordnet 和 Wikipedia
水平方向的融合:融合同层次的知识图谱,实现实例数据的互补。
融合 Freebase 和 DBpedia
4.知识存储和查询
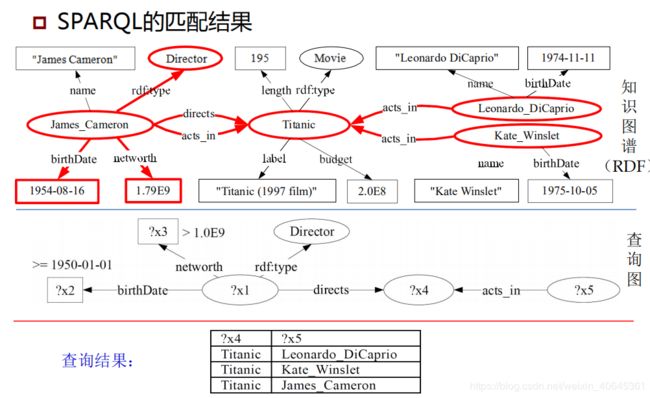
RDF图模型:RDF三元组:以文本的形式逐行存储;Google 开放的 Freebase 知识图谱

RDF图查询语言:SPARQL
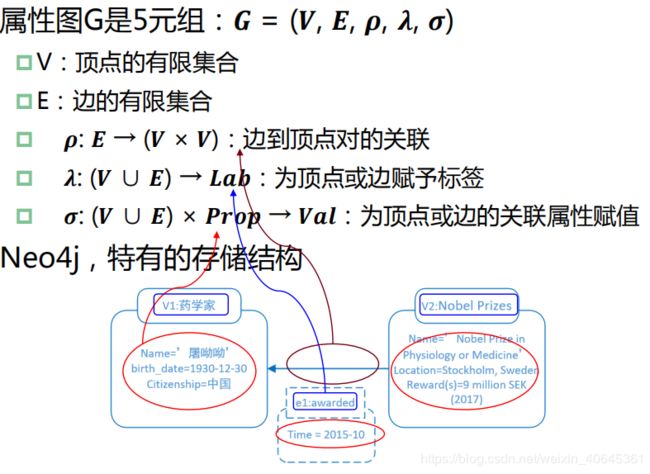
属性图模型:
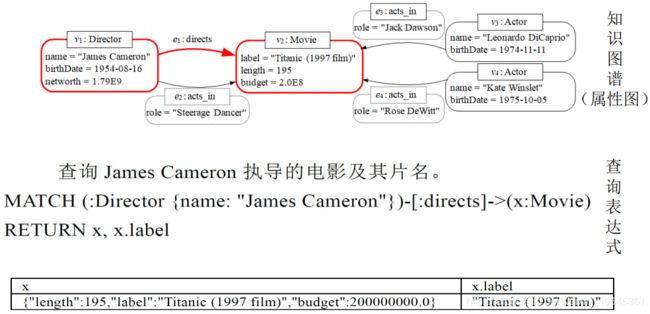
属性图查询语言:Cypher
5.知识推理
任务:采用推理的手段发现已有知识中隐含的知识
输入:大规模知识图谱
输出:隐含知识;
主要技术:
基于逻辑规则的推理
基于表示学习的推理
知识推理的不同计算手段
符号推理:特点是在知识图谱中的实体和关系符号上直接进行推理。本质是学习并应用推理规则。归纳和演绎
数值推理:使用数值计算,尤其是向量矩阵计算的方法,捕捉知识图谱上隐式的关联,模拟推理的进行。又叫做语义计算,即用深
度学习的手段进行推理。本质是分布式知识表示。将符号化的实体和关系在低维连续向量空间进行表示,在简化计算的同时最大程度保留原始的图结构。
数值推理示例:TransE,是最具代表性的位移距离模型,其核心思想是实体和关系间的位移假设
6.知识应用
语义搜索、天眼查、有推理能力的问答、推荐系统等
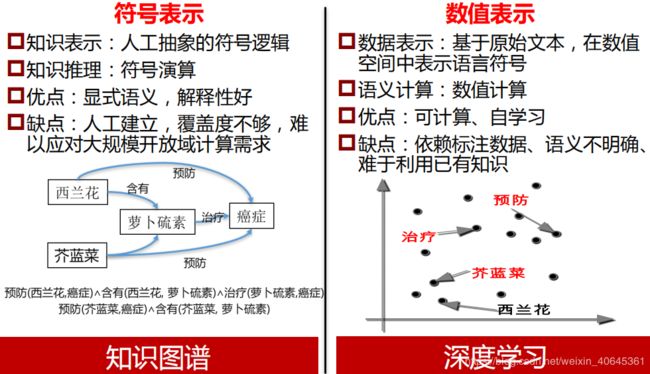
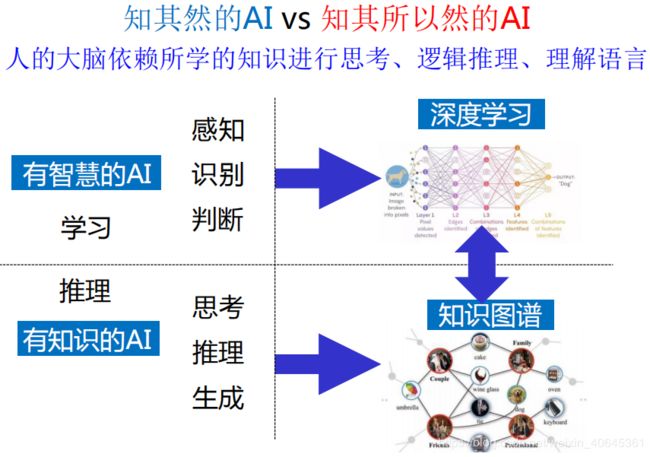
Part Five.知识图谱和深度学习
1.符号表示和数值表示
人工智能的两个流派:符号表示即知识图谱;数值表示即深度学习
Part Six.总结
知识图谱的特点:
知识图谱是人工智能应用不可或缺的基础资源
在语义搜索、问答系统、智能客服、个性化推荐等互联网应用中占有核心地位,在金融智能、商业智能、智慧医疗、智慧司法等领域具有广阔的应用前景。
语义表达能力丰富,能够胜任当前知识服务
知识图谱源于语义网络,是一阶谓词逻辑的简化形式,并在实际应用中通过定义大量的概念和关系类型丰富语义网络内涵。
描述形式统一,便于不同类型知识的集成与融合
本体(Ontology)和分类系统(Taxonomy)是典型的知识描述载体,数据库是典型的实例数据载体,它们的描述形式截然不同。知识图谱以语义网的资源描述框架(Resource Description Framework,RDF)规范形式对知识描述和实例数据进行统一表示,并通过对齐、匹配等操作对异构知识进行集成和融合,从而支撑更丰富、更灵活的知识服务。
二元关系为基础的描述形式,便于知识的自动获取
知识图谱对各种类型知识采取统一的二元关系进行定义和描述,为基于自然语言处理和机器学习方法进行知识的自动获取提供便利,为大规模、跨领域、高覆盖的知识采集提供技术保障。
表示方法对计算机友好,支持高效推理
推理是知识表示的重要目标,传统方法在进行知识推理时复杂度很高,难以快速有效地处理。知识图谱的表示形式以图结构为基础,结合图论相关算法的前沿技术,利用对节点和路径的遍历搜索,可以有效提高推理效率,极大降低计算机处理成本。
基于图结构的数据格式,便于计算机系统存储与检索
知识图谱以三元组为基础,使得在数据的标准化方面更容易推广,相应的工具更便于统一。结合图数据库技术以及语义网描述体系、标准和工具,为计算机系统对大规模知识系统的存储与检索提供技术保障。