Springboot整合Webmagic实现网页爬虫并实时入库
我的上一篇写的是面试技术AOP,当然,这么多天不在线,总得来点技术干货啊!公司最近需要爬虫的业务,所以翻了一些开源框架最终还是选择国人的开源,还是不错的,定制化一套,从抽取,入库,保存,一应俱全。现在展示一下我找的框架对比吧。
简单demo会如下,抽取要求,定时获取新闻列表,二级页面标题正文等信息。
关于爬虫组件的使用调研
调研简介:因使用爬虫组件抓取网页数据和分页新闻数据,故对各爬虫组件进行调研,通过分析相关组件的功能和技术门槛以及多因素,得出满足项目需求的适宜组件。
| 功能需求 |
webmagic |
crawler4j |
heritrix3 |
nutch |
spiderman2 |
| 抓取指定网页数据 |
√ |
√ |
√ |
√ |
√ |
| 抓取分页新闻数据 |
√ |
√ |
√ |
√ |
√ |
| 自定义存储抓取的网页数据内容或文件 |
支持存储至文件和数据库中 |
支持存储至文件和数据库中 |
job爬取数据默认存储为warc格式文件; 支持存储至文件和数据库中 |
1.x不支持; 2.x放到了gora中,可以使用多种数据库,例如HBase, Cassandra, MySql来存储数据 |
支持存储至文件和数据库中 |
| 定时抓取网页数据 |
√ |
√ |
√ |
√ |
× |
| 是否支持分布式爬取 |
√ |
√ |
√ |
√ |
√ |
| 性能需求 |
webmagic |
crawler4j |
heritrix3 |
nutch |
spiderman2 |
| 可视化(1) 配置化(2) 都不可(0) |
(2) 提供注解配置 |
(2) 可集成spring做配置 |
(1) 提供webUI配置爬取job |
(2) 采用脚本配置抓取 |
(0) 编辑代码配置 |
| 使用和查看地址 |
https://github.com/code4craft/webmagic |
https://github.com/yasserg/crawler4j |
https://github.com/internetarchive/heritrix3 |
https://github.com/apache/nutch |
https://gitee.com/l-weiwei/Spiderman2 |
| 组件热度star(s)和浏览次数(w) |
s:7589 w:803 |
s:3372 w:309 |
s:1385 w:174 |
s:1869 w:245 |
s:1377 w:528 |
| 稳定性 |
稳定 |
稳定 |
稳定 |
稳定 |
较稳定 |
| 用户手册和开发文档 |
完善 |
较差 没有开放的API,只提供了几个详细的源码事例 |
完善 用户手册和开发文档介绍详细 |
完善 用户手册和开发文档皆有最新版本,且详细 |
相对缺乏 |
| 社区生态 |
相对较好 |
一般 |
较好 |
较好 |
相对较差 |
| 开发门槛和学习成本 |
较低 |
较低 |
一般 有自己的web控制台,操作者可以通过选择Crawler命令来操作控制台,需要学习相关知识,但是是java开发的开源爬虫框架 |
较高 需要编写脚本,安装和使用都需要操作服务器,熟悉相关shell命令 |
较低 |
| 评价 |
垂直、全栈式、模块化爬虫。更加适合抓取特定领域的信息。它包含了下载、调度、持久化、处理页面等模块。 |
多数爬虫项目基于此组件进行开发,改造,扩展性和延展性相对较高,但是较基础,生态较差 |
文档丰富,资料齐全,框架成熟,适合大型爬虫项目,学习成本相对较高 |
apache下的开源爬虫程序,数据抓取解析以及存储只是其中的一个功能 |
架构简洁、易用,生态相对较差 |
综上所述:
认为选择小型框架webmagic相对适宜
选取原因:开发门槛低,简单、易用、容易上手、国内开发人员维护,文档详细,支持全栈式爬虫开发。
现在就拿springboot和webmagic做一个整合。
确定项目的技术要点,maven构建,orm为Spring Data JPA。
引入pom依赖:
org.springframework.boot
spring-boot-starter-web
org.springframework.boot
spring-boot-starter-test
test
us.codecraft
webmagic-core
0.7.3
us.codecraft
webmagic-extension
0.7.3
us.codecraft
webmagic-selenium
0.7.3
org.springframework.boot
spring-boot-starter-data-jpa
mysql
mysql-connector-java
5.1.38
确定项目结构:
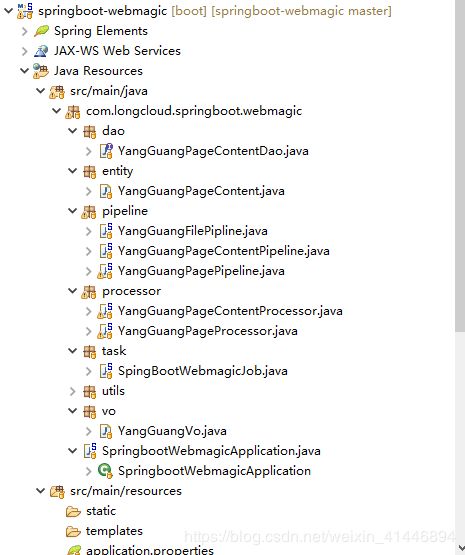
#模块介绍
processor模块负责抓取页面信息,执行抽取流程
pipeline模块负责保存抓取的信息
task模块负责设置定时任务,实现定时爬取网站信息
entity模块是实体信息模块
dao模块负责持久化数据
utils模块是工具类模块
我们这里只是做一个简单事例,代码直接贴上;
YangGuangPageContent.class
package com.longcloud.springboot.webmagic.entity;
import java.util.Date;
import javax.persistence.Column;
import javax.persistence.Entity;
import javax.persistence.Id;
import javax.persistence.Table;
/**
* 新闻内容
* @author 常青
*
*/
@Entity
@Table(name = "yang_guang_page_content")
public class YangGuangPageContent {
//新闻内容id
@Id
private String id;
//新闻正文
private String content;
//新闻作者
private String author;
//列表的新闻类型
private String type;
//新闻发表地点
private String address;
//新闻标题
private String title;
//新闻的被关注状态
private String status;
//新闻发表时间
@Column(name = "publish_time")
private String publishTime;
//新闻抓取时间
@Column(name = "created_time")
private Date createdTime;
//新闻抓取者
@Column(name = "created_by")
private String createdBy;
//列表的正文指向url
@Column(name = "content_url")
private String contentUrl;
//新闻抓取时间
@Column(name = "updated_time")
private Date updatedTime;
//新闻抓取者
@Column(name = "updated_by")
private String updatedBy;
public String getId() {
return id;
}
public void setId(String id) {
this.id = id;
}
public String getContent() {
return content;
}
public void setContent(String content) {
this.content = content;
}
public String getAuthor() {
return author;
}
public void setAuthor(String author) {
this.author = author;
}
public String getPublishTime() {
return publishTime;
}
public void setPublishTime(String publishTime) {
this.publishTime = publishTime;
}
public Date getCreatedTime() {
return createdTime;
}
public void setCreatedTime(Date createdTime) {
this.createdTime = createdTime;
}
public String getCreatedBy() {
return createdBy;
}
public void setCreatedBy(String createdBy) {
this.createdBy = createdBy;
}
public String getType() {
return type;
}
public void setType(String type) {
this.type = type;
}
public String getAddress() {
return address;
}
public void setAddress(String address) {
this.address = address;
}
public String getTitle() {
return title;
}
public void setTitle(String title) {
this.title = title;
}
public String getStatus() {
return status;
}
public void setStatus(String status) {
this.status = status;
}
public String getContentUrl() {
return contentUrl;
}
public void setContentUrl(String contentUrl) {
this.contentUrl = contentUrl;
}
public Date getUpdatedTime() {
return updatedTime;
}
public void setUpdatedTime(Date updatedTime) {
this.updatedTime = updatedTime;
}
public String getUpdatedBy() {
return updatedBy;
}
public void setUpdatedBy(String updatedBy) {
this.updatedBy = updatedBy;
}
}
dao:
package com.longcloud.springboot.webmagic.dao;
import java.util.Date;
import javax.transaction.Transactional;
import org.springframework.data.jpa.repository.JpaRepository;
import org.springframework.data.jpa.repository.Modifying;
import org.springframework.data.jpa.repository.Query;
import org.springframework.stereotype.Repository;
import com.longcloud.springboot.webmagic.entity.YangGuangPageContent;
@Repository
public interface YangGuangPageContentDao extends JpaRepository {
//根据url查询正文
YangGuangPageContent findByContentUrl(String url);
//更新部分字段
@Transactional
@Modifying(clearAutomatically = true)
@Query("update YangGuangPageContent set content = ?1 , updated_time = ?2 , updated_by = ?3 where content_url = ?4")
int updateContent(String content,Date updatedTime,
String updatedBy,String contentUrl);
}
抽取逻辑:
抽取新闻list ---YangGuangPageProcessor .class
package com.longcloud.springboot.webmagic.processor;
import java.util.ArrayList;
import java.util.Date;
import java.util.List;
import org.apache.commons.lang3.StringUtils;
import org.slf4j.Logger;
import org.slf4j.LoggerFactory;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.stereotype.Component;
import com.longcloud.springboot.webmagic.entity.YangGuangPageContent;
import com.longcloud.springboot.webmagic.pipeline.YangGuangPagePipeline;
import com.longcloud.springboot.webmagic.utils.UUIDUtil;
import com.longcloud.springboot.webmagic.vo.YangGuangVo;
import us.codecraft.webmagic.Page;
import us.codecraft.webmagic.Site;
import us.codecraft.webmagic.processor.PageProcessor;
import us.codecraft.webmagic.selector.Selectable;
@Component
public class YangGuangPageProcessor implements PageProcessor {
@Autowired
private static YangGuangPagePipeline yangGuangPagePipeline;
private static Logger logger = LoggerFactory.getLogger(YangGuangPageProcessor.class);
// 正则表达式\\. \\转义java中的\ \.转义正则中的.
// 主域名
public static final String URL = "http://58.210.114.86/bbs/";
public static final String BASE_URL = "http://58.210.114.86/bbs/forum.php?mod=forumdisplay&fid=2&page=1";
public static final String PAGE_URL = "http://58.210.114.86/bbs/forum.php?mod=forumdisplay&fid=2&page=1";
//设置抓取参数。详细配置见官方文档介绍 抓取网站的相关配置,包括编码、抓取间隔、重试次数等
private Site site = Site.me()
.setDomain(BASE_URL)
.setSleepTime(1000)
.setRetryTimes(30)
.setCharset("utf-8")
.setTimeOut(5000);
//.setUserAgent("Mozilla/5.0 (Macintosh; Intel Mac OS X 10_7_2) AppleWebKit/537.31 (KHTML, like Gecko) Chrome/26.0.1410.65 Safari/537.31");
@Override
public Site getSite() {
return site;
}
@Override
public void process(Page page) {
String[] pages = page.getUrl().toString().split("page=");
Long size = Long.valueOf(pages[1]);
if(size !=null && size <=2) {
YangGuangVo yangGuangVo = new YangGuangVo();
//获取所有列表框内容
List list = page.getHtml().xpath("//div[@class='bm_c']/form/table/tbody").nodes();
//获取当前页面的所有列表
if(list != null && list.size() > 0){
List yangGuangPages = new ArrayList();
for(int i = 0; i < list.size(); i++){
Selectable s = list.get(i);
//正文,地址等信息
String contentUrl = s.xpath("//tr/td[@class='icn']/a/@href").toString();
String type = s.xpath("//tr/th[@class='common']/em[1]/a/text()").toString();
String status = s.xpath("//th[@class='common']/img[1]/@alt").toString();
String title = s.xpath("//th[@class='common']/a[@class='s xst']/text()").toString();
String author = s.xpath("//td[@class='by']/cite/a/text()").toString();
String address = s.xpath("//th[@class='common']/em[2]/text()").toString();
String publishTime = s.xpath("//td[@class='by']/em/span/span/@title").toString();
if(StringUtils.isEmpty(type)) {
type = s.xpath("//tr/th[@class='new']/em[1]/a/text()").toString();
}
if(StringUtils.isEmpty(status)) {
status = s.xpath("//th[@class='new']/img[1]/@alt").toString();
}
if(StringUtils.isEmpty(title)) {
title = s.xpath("//th[@class='new']/a[@class='s xst']/text()").toString();
}
if(StringUtils.isEmpty(address)) {
address = s.xpath("//th[@class='new']/em[2]/text()").toString();
}
if(StringUtils.isNotEmpty(contentUrl)){
YangGuangPageContent yangGuangPage = new YangGuangPageContent();
yangGuangPage.setId(UUIDUtil.uuid());
yangGuangPage.setContentUrl(URL+contentUrl);
yangGuangPage.setCreatedBy("system");
yangGuangPage.setCreatedTime(new Date());
yangGuangPage.setType(type);
yangGuangPage.setStatus(status);
yangGuangPage.setTitle(title);
yangGuangPage.setAuthor(author);
yangGuangPage.setAddress(address);
yangGuangPage.setPublishTime(publishTime);
logger.info(String.format("页面的正文指向路径为:[%s]",contentUrl));
yangGuangPages.add(yangGuangPage);
}
}
yangGuangVo.setPageList(yangGuangPages);
}
page.putField("yangGuang", yangGuangVo);
//page.putField("yangGuangHtml", page.getHtml());
}
page.addTargetRequests(doListUrl());
}
/*public static void main(String[] args) {
Spider spider = Spider.create(new YangGuangPageProcessor());
spider.addUrl(BASE_URL);
spider.addPipeline();
spider.thread(5);
spider.setExitWhenComplete(true);
spider.start();
spider.stop();
}*/
public List doListUrl(){
List list = new ArrayList();
for(int i = 2;i<3;i++) {
list.add("http://58.210.114.86/bbs/forum.php?mod=forumdisplay&fid=2&page=" + i);
}
return list;
}
}
保存新闻list
YangGuangPagePipeline .class
package com.longcloud.springboot.webmagic.pipeline;
import java.util.ArrayList;
import java.util.List;
import java.util.Map;
import org.slf4j.Logger;
import org.slf4j.LoggerFactory;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.stereotype.Component;
import com.longcloud.springboot.webmagic.dao.YangGuangPageContentDao;
import com.longcloud.springboot.webmagic.entity.YangGuangPageContent;
import com.longcloud.springboot.webmagic.processor.YangGuangPageContentProcessor;
import com.longcloud.springboot.webmagic.vo.YangGuangVo;
import us.codecraft.webmagic.ResultItems;
import us.codecraft.webmagic.Spider;
import us.codecraft.webmagic.Task;
import us.codecraft.webmagic.pipeline.Pipeline;
@Component
public class YangGuangPagePipeline implements Pipeline{
@Autowired
private YangGuangPageContentDao yangGuangContentDao;
@Autowired
private YangGuangPageContentPipeline yangGuangPageContentPipeline;
private Logger logger = LoggerFactory.getLogger(YangGuangPagePipeline.class);
@Override
public void process(ResultItems resultItems, Task task) {
YangGuangVo yangGuangVo = (YangGuangVo) resultItems.get("yangGuang");
if(yangGuangVo != null){
System.out.println(yangGuangVo);
List list = new ArrayList<>();
if(yangGuangVo.getPageList()!=null && yangGuangVo.getPageList().size()>0) {
list = yangGuangContentDao.save(yangGuangVo.getPageList());
}
if(list.size()>0) {
for(YangGuangPageContent yangGuangPage : yangGuangVo.getPageList()){
logger.info("开始正文内容的抓取");
//这里我们对后面的页面进行了深度的抓取,获取新闻的二级页面信息
Spider spider = Spider.create(new YangGuangPageContentProcessor());
spider.addUrl(yangGuangPage.getContentUrl());
logger.info("抓取正文的URL:"+yangGuangPage.getContentUrl());
spider.addPipeline(yangGuangPageContentPipeline)
.addPipeline(new YangGuangFilePipline());
spider.thread(1);
spider.setExitWhenComplete(true);
spider.start();
spider.stop();
logger.info("正文内容抓取结束");
}
}
}
}
}
抽取新闻每个列表的正文部分:
YangGuangPageContentProcessor .class
package com.longcloud.springboot.webmagic.processor;
import java.util.Date;
import org.slf4j.Logger;
import org.slf4j.LoggerFactory;
import org.springframework.stereotype.Component;
import com.longcloud.springboot.webmagic.entity.YangGuangPageContent;
import us.codecraft.webmagic.Page;
import us.codecraft.webmagic.Site;
import us.codecraft.webmagic.processor.PageProcessor;
@Component
public class YangGuangPageContentProcessor implements PageProcessor {
private static Logger logger = LoggerFactory.getLogger(YangGuangPageContentProcessor.class);
public static final String URL = "http://58.210.114.86/bbs/";
//设置抓取参数。详细配置见官方文档介绍 抓取网站的相关配置,包括编码、抓取间隔、重试次数等
private Site site = Site.me()
.setDomain(URL)
.setSleepTime(1000)
.setRetryTimes(30)
.setCharset("utf-8")
.setTimeOut(5000);
//.setUserAgent("Mozilla/5.0 (Macintosh; Intel Mac OS X 10_7_2) AppleWebKit/537.31 (KHTML, like Gecko) Chrome/26.0.1410.65 Safari/537.31");
@Override
public void process(Page page) {
//获取正文的各个参数
YangGuangPageContent yangGuangPageContent = new YangGuangPageContent();
String content = page.getHtml().xpath("//div[@id='postlist']/div/table/tbody/tr/td[2]").toString();
//div[@id='JIATHIS_CODE_HTML4']/div/table/tbody/tr/td/text()正文内容
System.out.println(content);
yangGuangPageContent.setContentUrl(page.getUrl().toString());
yangGuangPageContent.setContent(content);
yangGuangPageContent.setUpdatedBy("system");
yangGuangPageContent.setUpdatedTime(new Date());
page.putField("yangGuangPageContent", yangGuangPageContent);
//page.putField("yangGuangHtml", page.getHtml());
}
@Override
public Site getSite() {
return site;
}
}
保存正文部分:
YangGuangPageContentPipeline .class
package com.longcloud.springboot.webmagic.pipeline;
import org.slf4j.Logger;
import org.slf4j.LoggerFactory;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.stereotype.Component;
import com.longcloud.springboot.webmagic.dao.YangGuangPageContentDao;
import com.longcloud.springboot.webmagic.entity.YangGuangPageContent;
import us.codecraft.webmagic.ResultItems;
import us.codecraft.webmagic.Task;
import us.codecraft.webmagic.pipeline.Pipeline;
@Component
public class YangGuangPageContentPipeline implements Pipeline{
@Autowired
private YangGuangPageContentDao yangGuangContentDao;
private static Logger logger = LoggerFactory.getLogger(YangGuangPageContentPipeline.class);
@Override
public void process(ResultItems resultItems, Task task) {
YangGuangPageContent yangGuangPageContent = (YangGuangPageContent) resultItems.get("yangGuangPageContent");
if(yangGuangPageContent!=null && yangGuangPageContent.getContentUrl()!=null) {
YangGuangPageContent dbYangGuangPageContent=yangGuangContentDao.findByContentUrl(yangGuangPageContent.getContentUrl());
//更新列表的正文内容
if(dbYangGuangPageContent!=null) {
logger.info(yangGuangPageContent.getContent());
yangGuangContentDao.updateContent(yangGuangPageContent.getContent(),
yangGuangPageContent.getUpdatedTime(),
yangGuangPageContent.getUpdatedBy(),
dbYangGuangPageContent.getContentUrl());
}
}else {
logger.info("此列表无内容");
}
}
}
定时抓取任务
SpingBootWebmagicJob.class
package com.longcloud.springboot.webmagic.task;
import org.slf4j.Logger;
import org.slf4j.LoggerFactory;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.scheduling.annotation.EnableScheduling;
import org.springframework.scheduling.annotation.Scheduled;
import org.springframework.stereotype.Component;
import com.longcloud.springboot.webmagic.dao.YangGuangPageContentDao;
import com.longcloud.springboot.webmagic.pipeline.YangGuangPagePipeline;
import com.longcloud.springboot.webmagic.processor.YangGuangPageProcessor;
import us.codecraft.webmagic.Spider;
@Component
@EnableScheduling
public class SpingBootWebmagicJob {
private Logger logger = LoggerFactory.getLogger(SpingBootWebmagicJob.class);
public static final String BASE_URL = "http://58.210.114.86/bbs/forum.php?mod=forumdisplay&fid=2&page=1";
@Autowired
private YangGuangPageContentDao yangGuangContentDao;
@Autowired
YangGuangPagePipeline yangGuangPagePipeline;
@Scheduled(cron = "${webmagic.job.cron}")
//@PostConstruct启动项目则开启
public void job() {
long startTime, endTime;
System.out.println("【爬虫开始】");
startTime = System.currentTimeMillis();
logger.info("爬取地址:" + BASE_URL);
try {
yangGuangContentDao.deleteAll();
Spider spider = Spider.create(new YangGuangPageProcessor());
spider.addUrl(BASE_URL);
spider.addPipeline(yangGuangPagePipeline);
// .addPipeline(new YangGuangFilePipline());
spider.thread(5);
spider.setExitWhenComplete(true);
spider.start();
spider.stop();
} catch (Exception e) {
logger.error(e.getMessage(),e);
}
endTime = System.currentTimeMillis();
System.out.println("【爬虫结束】");
System.out.println("阳光便民任务抓取耗时约" + ((endTime - startTime) / 1000) + "秒,已保存到数据库.");
}
}
别忘了application的配置哦:
server.port=8085
server.context-path=/
#database
spring.datasource.driver-class-name=com.mysql.jdbc.Driver
spring.datasource.url=jdbc:mysql://localhost:3306/scrapy-webmagic?useSSL=false&useUnicode=yes&characterEncoding=UTF-8&zeroDateTimeBehavior=convertToNull&allowMultiQueries=true
spring.datasource.username=root
spring.datasource.password=webmagic123
#connector-pool
spring.datasource.hikari.maximum-pool-size=20
spring.datasource.hikari.minimum-idle=5
#JPA
spring.jpa.database-platform=org.hibernate.dialect.MySQL5InnoDBDialect
spring.jpa.show-sql=true
#cron
#每天凌晨一点爬取一次
webmagic.job.cron=0 0 0 1 * ? *
到此一个定时爬取新闻的技术就完成了。欢迎继续关注我哦!