图像目标检测网络
一、定义
ROI(region of interest):感兴趣区域
region proposal method:候选区域方法
RPN(region proposal network):候选区域网络
滑动窗口检测
SS(selective search):选择性搜索
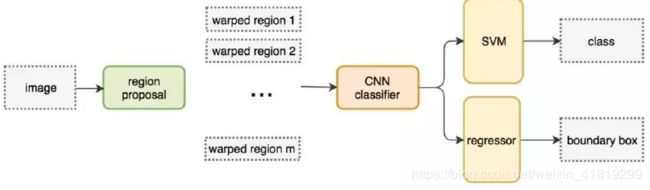
二、RCNN
用候选区域方法替代滑动窗口,更快更准。CNN classifier用于获取4096个特征,SVM用于确定box的类别,regressor边界框回归器/线性回归器/全连接层用于提炼边界框。
例如下图就是利用像素增长获得的区域,与其对应的ROI

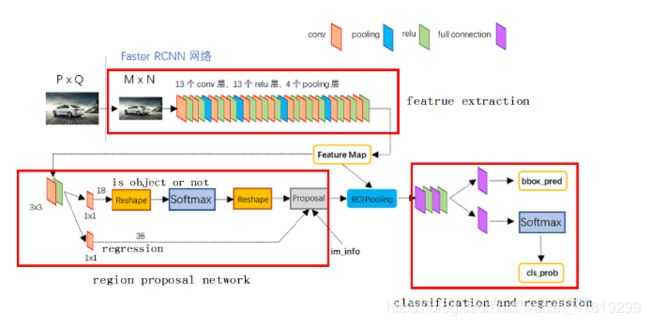
三、fast RCNN
ROI有重叠的可能,将ROI放到CNN classifier中时,就有重复计算的问题,由此将CNN这一步放到前面,先获取CNN,再计算ROI(例如利用VGG的conv5来计算ROI),再裁减特征图。
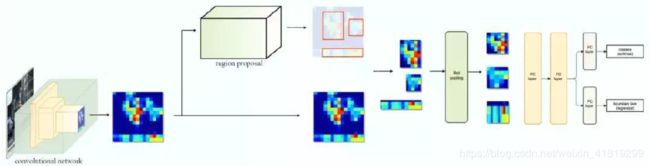
img——CNN获取Feature map——计算ROI——裁取——ROI池化——FC算class及回归box
采用的损失有:分类损失、定位损失
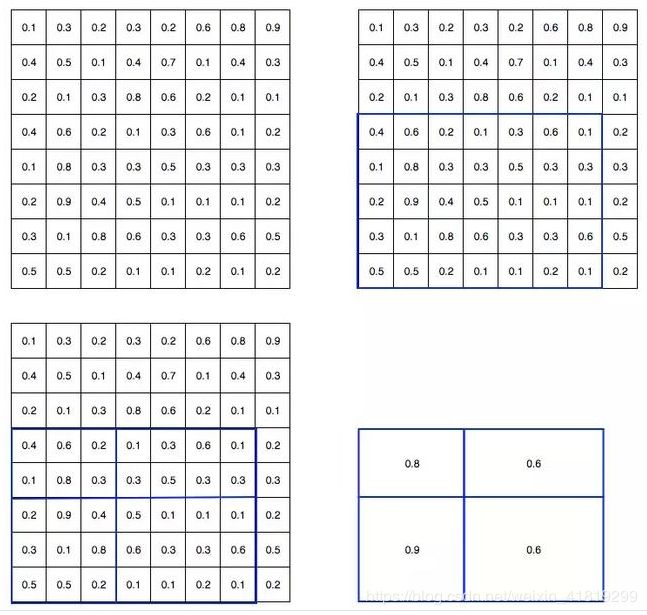
四、ROI池化
ROI池化=ROI+最大池化
对Feature map取感兴趣区域,若为2*2目标,将ROI区域划分为相等或相似大小的2*2个区域,每个区域取最大值
五、Faster R-CNN
参考链接:https://blog.csdn.net/liuxiaoheng1992/article/details/81843363
用候选区域网络(PRN)代替候选区域方法生成ROI,简单理解就是用深度网络的方法代替了融合像素的方法。
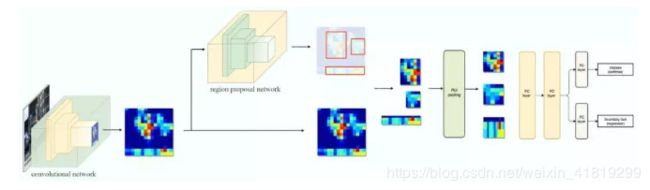
k=9,9 个锚点框:3 个不同宽高比的3 个不同大小的锚点框。下图中使用ZF网络获取conv5层256维度的conv feature map,将该Feature map作为PRN网络的输入,使用3*3的卷积核融合周围区域,应该是为了进一步集中特征信息?,再分别送入两个1*1卷积层获取每个位置2k个objectness 分数(2:带目标及不带目标的分类得分)和4×k 个坐标(4:x,y,w,h;).
原文中RPN网络为CNN后面接一个3*3的卷积层,再接两个1*1的卷积层(原文称这两个卷积层的关系为sibling),其中一个是用来给softmax层进行分类,另一个用于给候选区域精确定位。
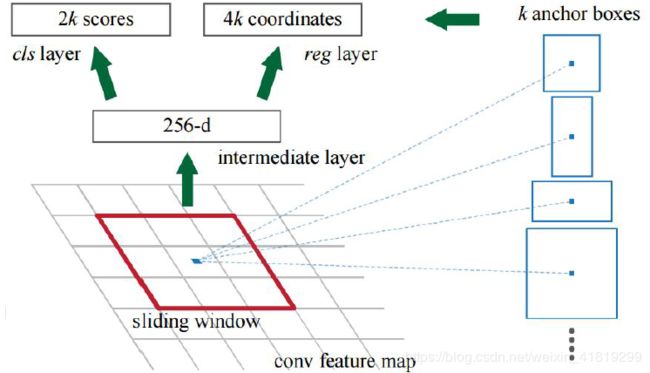
六、Anchor Boxes
参考链接:https://www.cnblogs.com/wangyong/p/8513563.html
1、为什么有anchor boxes的设计:
目标检测时会有物体的重叠,不同类别物体bounding box的检测中心可能落到feature map的同一个点上,那就不好对feature map的这个点进行分类了。比如下图通过前置CNN网络变成3*3的feature map,三行二列点是两类物体的中心。anchor boxes的设计可以让feature map中的一个点对应原图中的k个像素区域

2、一个feature map点如何对应到原图中的像素区域
CNN网络的操作一般会使长宽尺寸缩小N倍数而通道数增加。举个例子,在faster r-cnn中input image图像输入时先resize成了600*1000(这个resize后的大小不一定,网络会根据你设置的min max值调节,使长宽在这个范围内,比如我输入图像大小为1800*3000,min max尺寸为600、1024,就会resize到600*1000),经过某个CNN网络,图像变成了60*40*512的特征图(看成是16倍的差距),所以特征图上一个点就是原图中16*16的像素区域。如果是zf网络,特征图是256通道的‘如果利用VGG网络提取特征,特征图是512通道的。’
3、anchor boxes的选取
计算损失的时候是通过特征图计算,那映射到原始图像上有什么作用呢?假设设计的anchor box数量是k=9,那么对于60*40的特征图来说,就可以在原图上产生60*40*9个anchor boxes,这些boxes不是所有都参与训练,而是选取其中的正样本和负样本进行训练,规则如下:
① 去除掉超过1000*600这原图的边界的anchor box
② 如果anchor box与ground truth的IoU值最大,标记为正样本,label=1
③ 如果anchor box与ground truth的IoU>0.7,标记为正样本,label=1
④ 如果anchor box与ground truth的IoU<0.3,标记为负样本,label=0
剩下的既不是正样本也不是负样本,不用于最终训练,label=-1
4、anchor boxes如何对网络优化起作用
特征图通过后续的2个1*1卷积操作可以得到类别信息及回归框信息,其中类别信息是判断是否包含前景物体信息;回归框信息为偏移量△x,△y, △w, △h,利用偏移量加上基准anchor box可以得到更精确的预测框region proposal,再对预测框进行超出边界剔除及nms非极大值抑制,这就完成了PRN网络的作用。下式中_a中的a表示anchor box。
△x=(x*-x_a)/w_a △y=(y*-y_a)/h_a
△w=log(w*/w_a) △h=log(h*/h_a)
也不是所有经过边界剔除及nms的框douy都有用,只取前N个进行ROI池化。PRN网络和CNN网络输出的特征图(60*40*512)结合起来,裁减出一个个感兴趣区域(为了实现1000*600到60*40区域的映射,还进行了坐标缩小16倍的操作),通过ROI池化归一化到同一大小。再进行最后的全连接、softmax、region proposals获取更高精度的位置信息。
七、基于区域的全卷积网络(R-FCN)
faster r-cnn在获取ROI池化的结果后有一个全连接操作,计算量大。R-FCN不搞全连接了也不计算什么偏移量了,而是计算重叠区域,因此比faster r-cnn更快。

位置敏感得分图(position-sensitive score map),每个图检测目标的子区域(计算其得分)。比如上图5*5区域中的3*3蓝色方块,每个小块就是提高子区域,共9个子区域,也就是9个位置敏感得分图。
vote_array:每个位置敏感得分图与虚线框的对应子区域部分计算包含概率,得到vote_array。
位置敏感ROI 池化(position-sensitive ROI-pool):就是得到3*3数组的这个过程。
类别得分是其所有元素得分的平均值。
八、单次区域检测器
R-FCN通过某个方法绕开候选区域计算实现加速,单次区域检测器也是这样,可同时预测出类别和边界框。锚点不是点,是一个初始边界猜想,对于每个锚点,单次检测器可以得到一个预测框。比如对于一个20类分类的问题。特征图尺寸为8*8*D,单次检测器所用的卷积核尺寸为3*3*D*25(25=20类+4偏移量+1置信度),特征图就变为8*8*25。
类似于上面9个锚点的操作,对于8*8中的每个位置,也要做k次预测。
九、SSD
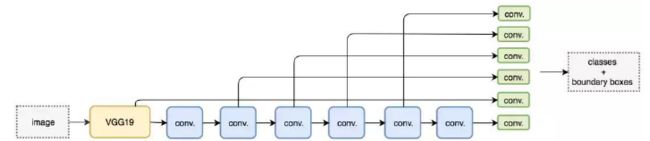
十、YOLO
C++版代码:https://pjreddie.com/darknet/yolo/
yolo有v1,v2,9000,v3这几个版本,用回归的方法来做分类问题。
V1精度低,召回率低,小目标检测不好,最大优点是速度快。
每个栅格预测x, y, w, h, confidence(dt 与gt的IOU)、conditional class probability(条件类别概率,即在一个栅格包含一个Object 的前提下,它属于某个类的概率)。即每个栅格的信息为B * 5 + C(B为一个栅格要预测的box数量,v1一般为2;5为x, y, w, h, confidenc;C为类别数量)。若分为S*S个栅格,则,预测的tensor为S*S(B*5+C)

v2改进点:
1)Batch Normalization提高泛化能力,提升mAP
2)High Resolution Classifier,也就是输入resize尺寸变大了,从256变成448
3)引入Anchor bo作者观察后发现,大物体通常占据画面中心,因此又把输入尺寸改成了416*416(13*32),这样得到的特征图就是13*13(奇数,中心有个cell)了。然后这13*13个位置,每个地方都预测9个box,以微弱的准确率的下降获取召回率的上升。而在V1中每个栅格只预测2个box。
4)用K-means方法训练bounding boxes,获取更有代表性的适合数据集的anchor boxes的尺寸
5)用Darknet-19代替VGG作为特征提取器,mAP无提升,但可减少计算量
6)改变边界框位置计算方式。约束了边界框的位置预测值,将边界框中心点约束在当前cell 中,不会在整张图上漂移,使得模型更容易稳定训练
7)passthrough层,又称reorg layer。简单来说,yolo对小目标检测不好,416*416*3尺寸的输入,卷积后变成了13*13*1024,参考了残差网络的思想,复用池化前的26*26*512的特征图,经过passthrough层处理,变为13*13*2046,将2处13*13连接起来为13*13*3072,在此基础上预测。工程实现上,是将26*26*512用64个1*1卷积为26*26*64,后经passthrough层处理为13*13*256
8)多尺度训练,yolov2只有卷积层和池化层,可以改变输入尺寸
9000:
9000的意思是可以检测超过9000个类别,可以综合利用检测和分类的数据集,为综合利用多个数据集,提出了一种层级分类方法建立数结构WordTree,处理多种数据集下的类别关系。WordTree 中的根节点为"physical object",每个节点的子节点都属于同一子类,可以对它们进行softmax 处理。在给出某个类别的预测概率时,需要找到其所在的位置,遍历这个path,然后计算path 上各个节点的概率之积。在预测时,树状概率图中最高的路径就是预测的类别。
v3改进点
1)多尺度预测
在三个尺度上每个尺度预测三个box,共9个box,就是将其他方法中的9个box按照大小均分给3 种尺度。
2)更好的基础分类网络(类ResNet)和分类器darknet-53,
3)类别预测损失预测
不使用Softmax而采用binary cross-entropy loss,可以应对重叠标签的情况,Softmax 可被独立的多个logistic 分类器替代。
参考资料:
https://www.toutiao.com/a6548986429299491331/?tt_from=weixin&utm_campaign=client_share×tamp=1525490580&app=news_article&utm_source=weixin&iid=29839959762&utm_medium=toutiao_android&wxshare_count=1