风格迁移相关论文阅读笔记
《图像和视频油画风格化研究》
西安交通大学 2011年
论文网址:
http://kns.cnki.net/KCMS/detail/detail.aspx?dbcode=CJFQ&dbname=CJFD2011&filename=JSJA201106003&uid=WEEvREcwSlJHSldRa1FhcTdWajFtOTIvT3Q2OWpaOGd6eWNTcmg1ZzVCWT0=$9A4hF_YAuvQ5obgVAqNKPCYcEjKensW4ggI8Fm4gTkoUKaID8j8gFw!!&v=MDIxMzVUcldNMUZyQ1VSTEtmWStkcEZDamdXci9OTHo3QmI3RzRIOURNcVk5Rlo0UjhlWDFMdXhZUzdEaDFUM3E=
文章简介:
本文从图像和视频两方面对油画风格进行了介绍,无实验部分。通过对油画的分析或许可以启迪一下对水墨画的思考。
用学习的方法进行图像处理,有两大类:
1.基于类比的学习模式:找出A到A’的映射,从而找到B的映射B’
2.基于单模板的学习模式:本文的方法利用风格图片中的多个风格块,还用到了分割,方向场,颜色风格
思考:
1.现有的方法都是基于一张风格图片,有没有多张风格图片的研究
2.一张风格图片的效果是不是也是一种过拟合
3.能否用水墨风的颜色损失
4.文中提到现有风格技术只涉及到了风格选择,而对其他艺术设计,如夸张、构图、艺术布局等的处理。抽象表达语义是关键
《基于深度学习的图像与视频风格化研究与实现》
中国科学院大学 硕士学位论文 2017年
论文网址:
http://kns.cnki.net/KCMS/detail/detail.aspx?dbcode=CMFD&dbname=CMFD201702&filename=1017183567.nh&uid=WEEvREcwSlJHSldRa1FhcTdWajFtOTIvT1NRSksyaWpBci9Zb1F1NXlhTT0=$9A4hF_YAuvQ5obgVAqNKPCYcEjKensW4ggI8Fm4gTkoUKaID8j8gFw!!&v=MzAxMTlNVkYyNkdiS3dIZFRLcUpFYlBJUjhlWDFMdXhZUzdEaDFUM3FUcldNMUZyQ1VSTEtmWStkcEZ5amdWTC8=
文章简介:
本文作者主要做了三方面的努力:提出一种新的图像风格转换网络U-StyleNet、自拍图像处理,视频风格化。图像的风格化主要基于2篇文章:[15]是李飞飞残差网络,[16]双通道多尺度网络
[15]残差风格转换网络
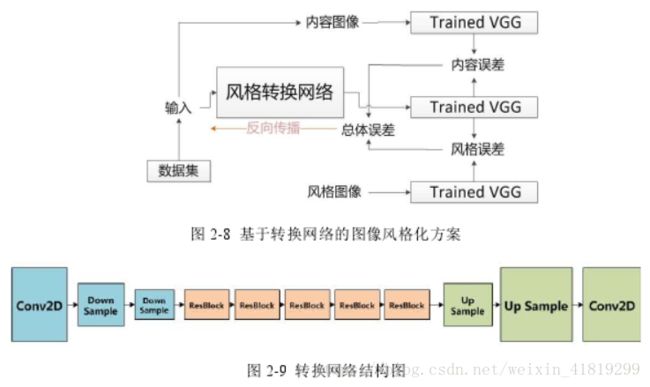
网络主要分为三部分:下采样区、残差区、上采样区
1、下采样区:通过步长为2的卷积层实现
2、残差区:包含5个连续的残差块
3、上采样区:包含两个上采样层(包含一个差值层和一个卷积层)和一个卷积层
可通过反卷积提高特征图的尺寸(反卷积会在块与块之间造成重叠,出现小格子。解决方法:1.卷积核大小是步长整数倍的反卷积减小这种效果;2.先使用最邻近插值法放大图像,再使用步长为1的卷积层)
[16]多尺度风格转换网络

将输入图像缩放为不同尺度的图像,经过不同通道后,在并联层结合,汇聚成原图相同尺寸的图像
作者提出的U-StyleNet:
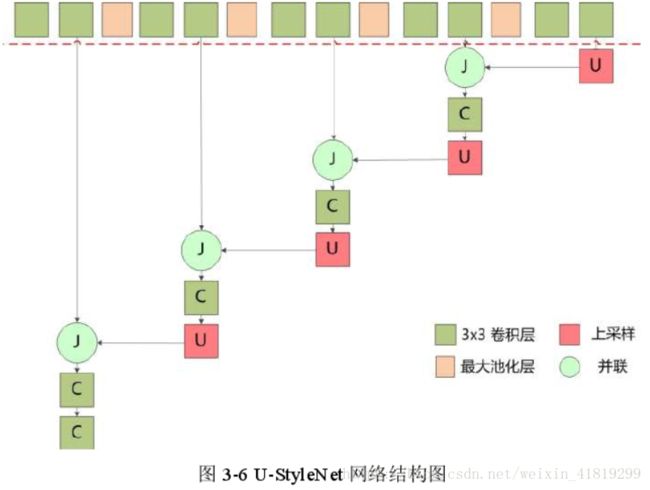
先用CIFAR100数据集训练虚线以上的分类网络,再用MS COCO数据集训练风格转换网络。
思考:1.多尺度风格转换网络可以学到不同维度的纹理特征,低层到高层的纹理特征对应局部到整体,而且更快,有没有有效的方法将这些不同维度的纹理特征应用到图像的不同细节上,即“不同层次纹理对目标图像的可调节性”
2.作者提到把人脸识别出来,然后单独处理会出现与背景不协调的问题,应考虑在设计风格转换网络的时候同时考虑人脸的识别和特殊处理。
《A Neural Algorithm of Artistic Style》
Gatys
文章简介:
基于像素迭代的方法
1.本文指出低层次响应描述图像的风格,高层次响应描述图像的内容。
2.Gram矩阵的计算:
风格在图像中表现为纹理特征,即像素之间的相关性,即不同feature map之间的相关性
3.和直觉相反,风格误差可以包含非常高的卷积层(conv5_1),反而有更自然,更“神似”的视觉效果。
这篇gatys的文章创造性地提出了低层featuremap是局部结构、颜色(有别于之前线,角等的说法),并将图像的风格和内容分开再重组
思考:无
《Deep Painterly Harmonization》深度绘画协调
康奈尔大学 Adobe Research 栾福军 2018.04
参考译文:https://zhuanlan.zhihu.com/p/35633664
http://tech.ifeng.com/a/20180415/44955021_0.shtml
文章简介:
1.跳出全局风格化的范围,实现局部风格化,在去除边界线、匹配色彩、细化质地上表现更为突出
2.核心思想:把画作相关部分(神经元响应)的特征统计,迁移到外来物体的对应位置上,关键在于选择,哪些东西是应该迁移的
two-pass,风格重建损失(Gram矩阵)
3.
第一步:粗略图像协调(单一尺度)
大致调整外来元素的色彩和质地,和画中语义相似的部分对应。要在神经网络的每一层,分别找到相邻最近的神经补丁,和粘贴部分的神经元响应匹配起来。再用Gram矩阵对风格损失优化一下
第二步:高品质细化(多尺度)
在一个负责捕捉质地属性的中间层集中火力,生成一个对应关系图(correspondence map),剔除空间异常值(spatial outliers)
对拥有空间一致性的对应图进行上采样,进入神经网络更加精细的层次里。保证对每一个输出位置来说,所有尺度上的神经元响应,都来自画中同一位置,使画面更连贯。
后处理:
(1)色度降噪:将图像转换成cielab色彩空间,再在Guided Filter里,以亮度通道作为向导,过滤ab色度通道
(2)补丁合成:用patch match来给每一个补丁找到相似的补丁。再为所有画风重叠的补丁取平均值,以此重构output,保证画面里不要出现新内容。副作用是会柔化细节,所以又要使用Guided Filter把图像分成底层和细节层来削弱柔化效果
思考:
1.文章提到:高频失真的现象,主要作用在色度通道,对亮度并没有太大影响。可是人眼不是应该对亮度比较敏感吗?难道这是画作的特性?这是高频特性?
2.转移区域特征统计的集合,比转移很多独立位置的特征统计效果要好
3.空间一致性及跨尺度一致性
《Deep Photo Style Transfer》深度图像风格转换
康奈尔大学 Adobe Research 栾福军 2017
参考译文:https://blog.csdn.net/cicibabe/article/details/70868746
文章简介:
1、本文实现了写实风格变换,即输入图像及参考图像都是真实照片,将输入图像到输出图像的变换约束在色彩空间的局部仿射变换中,将这个约束表示成一个完全可微的参数项,抑制图像扭曲(如直线弯曲、纹理扭曲),用拉普拉斯抠图矩阵表示一个完全可微项抑制图像扭曲。拉普拉斯抠图变换约束从色彩空间上从输入到输出的局部仿射变换。
2、将变换操作限制在色彩空间上,使用了色彩空间上的局部仿射变换模型。用到了写实正则化参数项。
3、抑制风格溢出:对变换过程中由于输入图像和参考图像的内容不同而导致的不相关内容不在预期范围内的变换的出现提供了解决方案。例如:一个输入图像的天空内容比较少,其他风格变换可能会忽略掉内容上的差异而导致天空风格“溢出”到图像的其他部分。
这是通过语义风格来解决的,这涉及到语义精度和转移保真度。用风格图像最相似的区域匹配每个输入神经区域,这个策略的本质是卷积网络和马尔科夫随机场方法。将输入图像和风格图像的语义标注整合到整个转移过程中,这样在相同语义的次区域间和每个次区域上进行风格转移,映射就会趋向均匀。
4、风格溢出可以根据计算输出图像和参考风格的对应关系来判断
5、抑制输入图像和部分风格图像区域匹配,其他整个风格图像区域被忽略的问题:用神经网络反馈gram矩阵的参考风格图像转移完整的“风格分布”。
思考:
1、如何在局部优化和全局一致性之间寻找平衡?
《Precomputed Real-Time Texture Synthesis with Markovian Generative Adversarial Networks 》基于马尔科夫GAN网络的预计算纹理合成
参考译文:https://www.jianshu.com/p/6054799d7bb1
文章简介:
预计算 一个前馈的步幅卷积网络,对马尔科夫碎片的纹理数据进行捕获,生成任意维度的输出,把棕色噪声解码成逼真的纹理或把图片转化成艺术图像。本文通过一种预计算网络反向的方法来加速。
大致流程:内容图像经过VGG进行特征抽取,送入G网络并输出风格图像,风格图像分别经过VGG网络抽取出风格特征和内容特征。最后将合成图片的风格特征和风格图像的风格特征输入到D网络得到GAN的损失函数,并将合成的图片的内容特征和内容图像的内容特征输入MSE损失函数。这两个损失函数共同更新网络的参数(主要是G网络和D网络)。
1.马尔科夫随机场在风格迁移中的应用
通过像素值的局部碎片区域描绘图像特征
2.深层结构对表现在物体类型上的变化的捕获能力已经超过了像素水平上的方法
疑问:这个说法是指考虑到语义了吗
3.两类生成模型
第一类:全图像模型
生成整体图像,
缺点:局限于细节上保真度有限的小图片
第二类:马尔科夫模型
捕获局部数据(碎片数据),并把它们集合成高分辨率的图片(建模)
缺点:生成特殊全局结构需要附加指引
4.初始化
在同样迭代周期下,用一个预训练的识别网络初始化可以得到比随机初始化好非常多的结果
5.本文方法缺陷
不能在两张不同面部照片之间转化面部特征,因为面部特征不能视作纹理,需要语义上的理解(例如:表情、姿势和性别)
思考:
1.作者认为“可能不存在一个对于所有纹理通用的最适宜的设计”
《Texture Networks: Feed-forward Synthesis of Textures and Stylized Images 》纹理网络:在前馈网络中进行纹理合成与风格化
参考译文:https://www.jianshu.com/p/1187049ae1ad
文章简介:
1.匹配统计特征
通过对网络进行描述性的研究,比如图像统计。他们的的想法是减少图像生成的随机抽样以匹配确定的统计特征
2.某些网络OOM原因
使用了梯度下降,利用反向传播来改变像素点的值需要高昂计算代价,占大量内存
3.预图片
4.有些生成器是通过确定性参数(拍摄对象的类型和观点)来生成目标图像的
5.GAN有助于解决样本多样性的问题,不再是一对一的映射关系
6.矩匹配网络——从分布派生的损失函数通过比较网络样本的统计平均值可代替GAN

7.本方法不使用VGG网络
生成器网络比VGG19小很多,可以实现显著提速。显著提速的另一个原因是避免了反向传播。
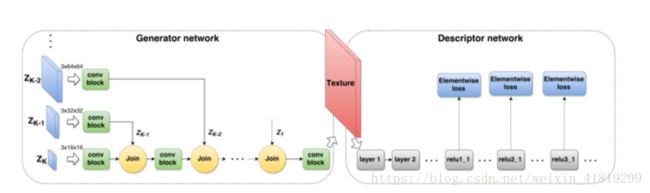
8.前馈网络
前馈神经网络是一种最简单的神经网络,各神经元分层排列。每个神经元只与前一层的神经元相连。接收前一层的输出,并输出给下一层.各层间没有反馈。
思考:
1.纹理合成中的描述性纹理建模没看懂
2.多尺度前馈网络的结构没有使用VGG网络,也就是说VGG分类网络不是必须的
《Multimodal Transfer: A Hierarchical Deep Convolutional Neural Network for Fast Artistic Style Transfer 》多模型迁移:一种用于快速风格迁移的分级深度卷积神经网络
CVPR 2017
参考译文:https://blog.csdn.net/u011534057/article/details/78935202
文章简介:
1.L通道
L通道代表光线强度,在Lab颜色模型中,有L亮度通道及a/b两个颜色通道
2.双通道
本文作者使用了RGB+L的结构,原因在于作者认为人类对L通道较为敏感
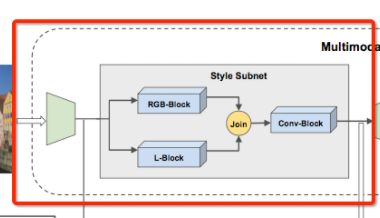
3.反卷积问题
和很多论文一样,为了避免棋盘状的现象,将反卷积换成双向性上采样(bilinear upsampling)
4.三步训练
1) Style Subnet(256) 用来捕获 color & texture traits
2) Enhance Subnet(512) 用来做stylization strength
3) Refine Subnet(1024) 用来remove local pixelization artifacts(去除局部伪影)
5.模型
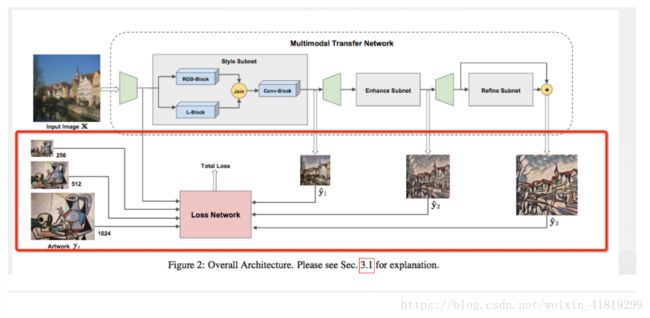
6.损失计算
在256,512,1024三种不同的尺度上计算

思考:
1.这个也是双通道多尺度?
《Improved Texture Networks: Maximizing Quality and Diversity in Feed-forward Stylization and Texture Synthesis》
改进的纹理网络:前馈风格化和纹理合成中的质量和多样性最大化
文章简介:
1.贡献
本文对前馈网络做了两大改进
首先是 IN(实例归一化 instance normalization)代替了BN(块归一化 batch normalization)
第二是通过一种方法改善了结果的多样性:从Julesz纹理集合(某些损失在一定阈值范围内的图像的集合)中进行均匀采样
2.IN实例归一化(有些人也称为 contrast normalization 对比度归一化)
IN层计算的是卷积层每一层输出的每个通道数据自身的均值和方差
IN与BN的区别是BN将归一化应用到了N张图片(一个batch),而IN是将归一化应用到了一个实例上,iN实现了对每个内容图像的归一化。
IN:
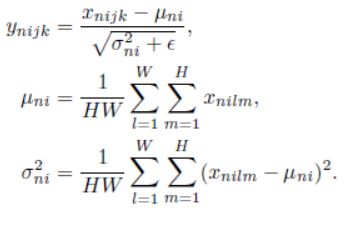
μ计算均值,σ计算方差
BN:
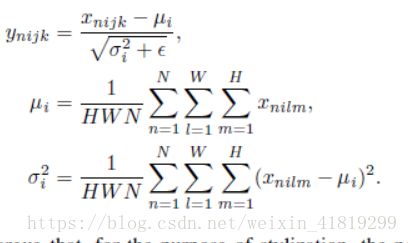
3.均匀采样
优化一个KL散度损失函数,KL散度是风格损失期望值L 以及 生成分布的负熵 之和

思考:
1.结果的多样性
2.IN层为同一网络同时风格化多种风格打下基础,这是否意味着可以避免对一张图片的过拟合
《a learned representation for artistic style》
谷歌大脑 2017
参考译文:
https://blog.csdn.net/wyl1987527/article/details/66472349
文章简介:
1、贡献
N个风格共用一个模型,缓解模型存储耗费空间的问题,因为一些计算实际可共享
2、条件网络的输入
内容图片+style的id
3、两个新加入的参数:缩放和平移
γ和β这两个参数,一个是缩放一个是平移
卷积权重可以多风格共享????
4、N-style风格(多风格融合)
对N风格的模型,只用一个网络,只是增加了N *C*2个参数,N表示风格数,C表示feature maps,2是代表γ和β这两个参数。
 ,在整个网络中只有0.2%的大小是存储的不同风格数据,而且参数个数随着风格个数是成线性增加。
,在整个网络中只有0.2%的大小是存储的不同风格数据,而且参数个数随着风格个数是成线性增加。
5、如何对李飞飞的网络做了改进
a.填充不是采用0填充而是采用了镜像填充,避免了在卷积事有时用0填充造成的边界伪边现象;
b.上采样是采用了先进行最近邻插值再进行卷积代替了之前的步长位1/2的转置卷积,这样处理避免了棋盘现象;
c.由于进行了上两个点的改进,损耗函数不再需要有一个总变差的损耗,之前提出的风格迁移模型中损耗函数计算时需要加入这项来减少高频噪声。
d.最后一层卷积层的激励函数是Sigmoid,不是relu.如果仍然使用relu会发现棋盘效应好了,但是会存在黑块
实验代码:
github代码:
https://github.com/tensorflow/magenta/tree/master/magenta/models/image_stylization
https://github.com/Heumi/Fast_Multi_Style_Transfer-tensorflow
参考代码
谷歌增强型风格迁移新算法
http://view.inews.qq.com/a/20161027A04FWH00?refer=share_recomnews
思考:
1.这里的所谓N-style,是对风格的线性融合,有没有更好的定义?有点像基因多样性的意思,但基因是通过颗粒保存的,是非连续的,能否用非线性的方法定义多风格融合?怎么对map进行操作代替原来的缩放和平移?用超像素?
2.风格信息保存下来的结果和风格图片的分辨率关系很大,对分辨率很敏感。非线性的话怎么确定纹理的对应关系?用语义?还是风格图片的分辨率?
3.以上两点的考虑算不算融合多特征?
4.考虑从离散和连续两个角度探索多风格融合:
离散:
a.用语义限定风格转移的区域
b.分时处理,就像2018年栾福军的方法,在加入新元素时使用新的纹理风格
c.使用超像素,在同一块内使用同一种风格,这种方法应该要考虑全局一致性
连续:
a.将线性融合转化为非线性融合,参考下正片叠底等一些方法
b.在不同尺度上应用不同的纹理,最后加个高斯模糊什么的?
《Diversified Texture Synthesis with Feed-forward Networks》基于前馈网络的多样化纹理合成
CVPR2017
文章简介:
1.网络结构

网络分为两大部分:生成器及选择器。选择器通过级联引导生成器进行纹理合成
本文的训练数据集:可描述纹理数据集Describable Textures Dataset (DTD)
输入是风格的one-hot向量及噪声,噪声的多样性与结果的多样性有关
2.本文贡献
三大贡献:
a.一个用户可控的生成网络用以合成多种纹理(确实没见过相似的?)
b.引入了多样性损失diversity loss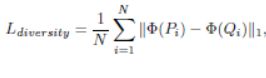
c.本文提出了一种基于增量学习算法的学习算法

d.通过减去均值改进了风格损失的gram矩阵
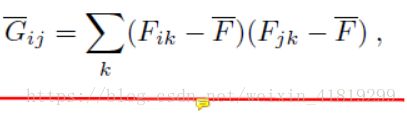
思考:
1.建立一个多风格融合网络需要考虑的问题:
a.如何进行训练
b.多个风格的存储,尽量减少内存
c.可控连续的多样性结果
d.损失的表示
e.不同的纹理其收敛速度存在差异,应与单个纹理的复杂性及纹理之间的差异有关
f.对某个纹理形成过拟合
《Fast Patch-based Style Transfer of Arbitrary Style》基于切片的快速任意风格的风格转换
陈天奇2016
参考译文:https://blog.csdn.net/wyl1987527/article/details/70476044
文章简介:
这篇文章用80,000张自然图片和80,000张绘画训练了一个逆网络来实现任意风格的转换。对内容的feature maps采取基于块的方法(块的大小为3/5/7)在风格的feature maps中寻找最接近的块来替换,即style swap思想
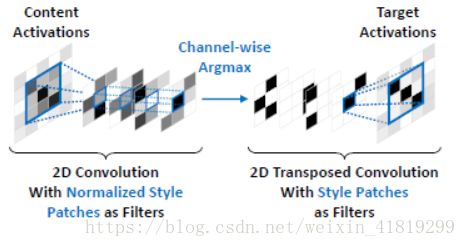
网络结构:
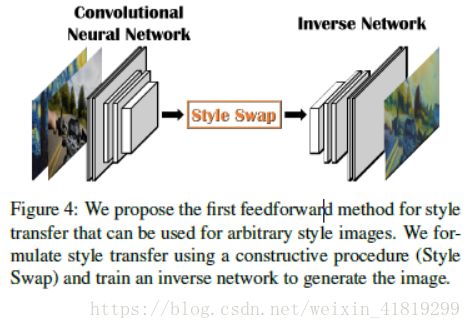
《Arbitrary Style Transfer in Real-time with Adaptive Instance Normalization 》自适应实例归一化的任意风格转换
ICLR 2017
参考译文:https://blog.csdn.net/wyl1987527/article/details/70245214
文章简介:
任意风格的实时风格转换,核心是自适应实例归一化层
1.起源及发展
本文这种使用AdaIN的起源分两条线:
2015年BN——2016年IN——2017年CIN(平移缩放)
2016年陈天奇style swap(实现任意内容任意风格)

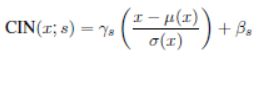

x代表内容输入,y代表风格输入,缩放和平移参数是从风格输入计算得到的。
CIN需要训练2*N*C个参数,N代表风格数量,C代表feature map的数量
2.AdaIN
以两张feature maps作为输入,调整内容的feature map的均值和方差以适应风格的feature map
AdaIN和Fast Patch-based Style Transfer of Arbitrary Style这篇论文中提出的style swap层作用类似,都是把风格信息加入到content中
3.网络结构
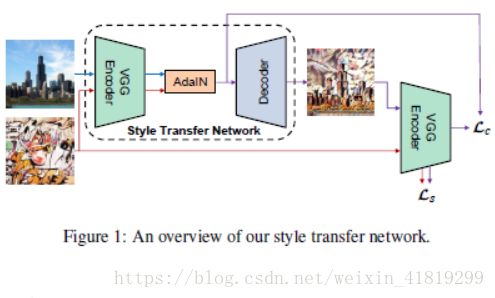
左边encoder-AdaI_Decoder三部分组成风格转换生成网络,右边的VGG为计算损耗网络
4.编解码及空间
编码:将图像从图像空间转到特征空间
解码:将图像从特征空间到图像空间
5.本文风格损耗
该论文在CIN的基础上做了一个改进,提出了AdaIN(自适应IN层)。顾名思义,就是自己根据风格图像调整缩放和平移参数,不在需要像CIN一样保存风格特征的均值和方差,而是在将风格图像经过卷积网络后计算出均值和方差。该方法会比上一种方法简单得多,也比较好实现。
思考:
1、BN、IN、CIN、AdaIN这个演变其实是对一个公式做了不同的解释
2、陈天奇2016年那篇和本篇论文都是将style加到content中去
《综述:图像风格化算法最全盘点 | 内附大量扩展应用》
http://baijiahao.baidu.com/s?id=1600455538813155076&wfr=spider&for=pc
文章简介:
1、风格迁移源于两个领域:纹理建模、图像重建
纹理建模解决了如何对风格特征进行提取的问题。
图像重建解决的则是如何将给定的特征表达重建还原为一张图像。
2.Gram矩阵
Gram 矩阵的纹理表示方法其实是利用了二阶统计量来对纹理进行建模
3.总变分TV
对图像进行恢复、去噪
4.除Gram矩阵外的对风格进行建模的方法
Domain Adaption 指的是当训练数据和测试数据属于不同的域时,我们通过某种手段利用源域有标签的训练数据训练得到的模型,去预测无标签的测试数据所在的目标域中的数据。
Domain Adaption 其中一个套路就是以最小化统计分布差异度量 MMD 的方式,让目标域中的数据和源域中的数据建立起一种映射转换关系。
@Naiyan Wang 老师通过公式推导发现,最小化重建结果图和风格图的 Gram 统计量差异其实等价于最小化两个域统计分布之间的基于二阶核函数的 MMD。换言之,风格迁移的过程其实可以看做是让目标风格化结果图的特征表达二阶统计分布去尽可能地逼近风格图的特征表达二阶统计分布。
可参看论文:Demystifying Neural Style Transfer
由此可以很自然地想到,既然是衡量统计分布差异,除了有二阶核函数的 MMD 外,其他的 MMD 核函数例如一阶线性核函数、高阶核函数、高斯核函数,也可能达到和 Gram 统计量类似的效果。实验证明也确实如此。这些计算风格特征的方式其实都是在特征表达(feature map)的所有 channel 上进行计算的。
5.对于BN、channel-wise的进一步理解
用VGG某些曾的特征表达的每一个channel的均值和方差来表示风格

表示 VGG 中第 l 层的 feature map 的第 c 个 channel
6.像素空间的低层次图像信息
以往风格化算法在提取特征的时候都是在高层次的 CNN 特征空间(feature space)中完成的,虽然这样做的效果在感知效果上(perceptually)优于利用传统的在像素空间(pixel space)计算的特征,但由于特征空间是对图像的一种抽象表达,会不可避免丢失一些低层次的如边缘等的图形信息这会导致风格化结果图中有一些不是很漂亮的变形等。
@李韶华 老师为解决这一问题,在 ACM MM2017 的一篇文章中 [40]Laplacian-Steered Neural Style Transfer,提出在风格化迁移的过程中同时考虑像素空间和特征空间。
具体做法为在像素空间中将内容图的拉普拉斯算子的滤波结果和风格化重建结果图的滤波结果之间的差异作为一个新的 loss,加到祖师爷 Gatys 提出的损失函数上面。这样的话就弥补了抽象特征空间丢失低层次图像信息的缺点。
7.MRF多重参考模型——用以取代Gram矩阵
其核心思想是提出了一个取代 Gram 损失的新的 MRF 损失。思路与传统的 MRF 非参数化纹理建模方法相似,即先将风格图和重建风格化结果图分成若干 patch,然后对于每个重建结果图中的 patch,去寻找并逼近与其最接近的风格 patch。以上操作是在 CNN 特征空间中完成的。
这种基于 patch 的风格建模方法相比较以往基于统计分布的方法的一个明显优势在于,当风格图不是一幅艺术画作,而是和内容图内容相近的一张摄影照片(Photorealistic Style),这种基于 patch 匹配(patch matching)的方式可以很好地保留图像中的局部结构等信息
思考:
1、其他论文里长谈到的编码、解码。编码就是将图像从图像空间转到特征空间,解码就是将图像从特征空间转到图像空间(这就属于图像重建)
2.栾福军的照片风格转换也是用拉普拉斯算子来抑制边缘扭曲,其实本质就是用了额外的损失项
《Universal Style Transfer via Feature Transforms》基于特征变换的通用风格转换
参考译文:https://blog.csdn.net/u011534057/article/details/78935230
文章简介:
本文的主要特色是用了白化着色的方法来实现风格转换,且可以实现任意图像任意风格
1.Whitening & Coloring Transform(WCT)
刷白和着色的变换反映了内容图像的特征协方差与给定风格图像的直接匹配
刷白:首先将feature map减去均值,然后乘上对自身的协方差矩阵的逆矩阵,进行whitening, 将feature map拉到一个白化的分布空间。
着色:然后通过对style image取得image feature map的coloring协方差矩阵,乘上content image 白化后的结果加上mean,即将content图白化后的feature map空间迁移到style图的分布上。
2单层风格化网络

先训练一个编解码网络,然后将WCT插入编解码中,实现特征空间统计上的匹配。对于一种新的需要风格化的风格,只要计算风格图像的协方差矩阵,就能通过WCT将风格加入内容的feature中
3.多层风格化网络
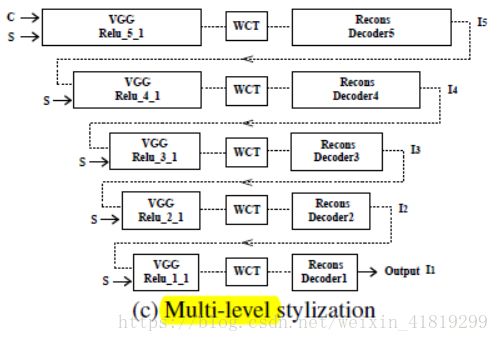
从高层到低层,不断编解码,由粗到细
4.用户可控性
本作者从尺寸、权重、空间上对风格化过程进行了控制
尺寸:由于感受野的限制,不同分辨率的风格化图像得到的统计结果不同,会对风格化效果产生影响,调整风格图像尺寸进行控制
权重:从损失的角度调整内容和风格的权重
空间:实现在一张图像中不同区域用不同方法实现风格化,本文中不同区域是different masks
5.纹理融合
将内容图像设置为高斯噪声图,风格图像为s1和s2,将s1和s2分别通过WCT方法得到转化后的featu,fcs1和fcs2.进行一个线性插值![]() ,解码后得到混合后的效果
,解码后得到混合后的效果
6.多样性
本文的多样性也是通过噪声的多样性实现的
思考:
1.评价一种风格化方法的指标
客观评价:通用性、转换质量(需要从几种差异性很大的风格的角度进行评价,如绘画、抽象画。。。)、效率
主观评价:网络投票
2.纹理融合不仅要考虑公式上的表示,也要考虑在网络的什么时候进行融合,越早越好
《StyleBank: An Explicit Representation for Neural Image Style Transfer》风格基元:神经图像风格转换的显式表示
参考译文:
https://blog.csdn.net/wyl1987527/article/details/75452215
https://blog.csdn.net/dpppbr/article/details/78794733
文章简介:
1.风格基元StyleBank
创新灵感:纹理合成技术中的纹理基元(texton)
不同的风格被表示为不同的风格基元

左图——纹理合成——纹理基元和位置脉冲函数(Delta function)之间的卷积
右图——风格迁移——特征空间中特定风格基元和图片特征响应之间的卷积
为了更好的理解风格基元的工作原理,对训练学到的风格基元进行了可视化, 实际上它表达了风格图片中不同的纹理单元,而这与经典的纹理合成一脉相承。

2.内容、风格分离
显式地对图像的内容和风格进行分离
3.学习(分离训练/独立训练/(T+1步交替训练)+增量训练)
在训练时,每T+1次迭代,先训练风格化分支T次迭代,然后训练自编码分支一次。
图像自解码器与风格基元之间的学习相互独立
快速训练 (将一种艺术风格效果的训练时间从4-5小时减少到10分钟以内)
自编码器分支(Auto-encoder branch,实线)和风格化分支(Stylizing branch,虚线), 通过切换学习,从而对图像的内容和风格的进行分离。

增量学习:对于一个已经训练完成的StyleBank,可以保持编码器与解码器不变,以增加一个新的滤波器的方法来增加一个新的风格
4.多风格线性融合
通过对不同风格的风格基元(StyleBank)进行组合,可以轻松实现不同风格的融合和过渡切换
线性融合风格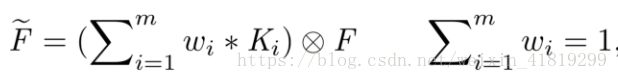
5.部分风格提取
可以做到对图片的某一部分进行风格提取,再融合到目标图片上
6.多风格协同训练
与以往单风格模型相比(需要4小时训练一种风格),风格基元支持一个网络多风格协同训练,以50个风格为例,平均每个风格训练耗时16分钟,而试验中曾尝试过175个风格一起协同训练同一个网络。这样额外带来的好处就是可以大幅降低模型的大小,比如一个风格只需要0.56MB,而以往的模型如Johnson[5]则需要6.4MB

7.区域性风格融合
有不同风格融合、不同风格权重融合、不同风格层融合.
特定区域风格融合:不同的图像区域可以被渲染成不同的风格。可以在图像自编码后的特征空间中对特征进行分簇实现不同区域划分
a.content image 编码后的feautres可以在空间上进行分簇(颜色、边缘、纹理),如可以采用K-mean的无监督算法进行分簇,获得如下图中的左边结果,这里可以看到实现了图像的分割效果,因此这里的自编码可以实现特定区域的风格转换。
本方法可实现多风格融合,以及通过聚类可实现空间控制


思考:
1.微软亚洲研究院视觉计算组 做了好多相关工作,暴风雨式哭泣
2.这些特征在通道上稀疏分布。有价值的响应始终存在于某些特定通道。很可能是这些通道刚好对应于区域特定转移中的特定风格元素。???
3.本文的增量学习是指增量训练一个新的风格
《Visual Attribute Transfer through Deep Image Analogy》基于深度图像类比的视觉属性传递
参考网址:https://zhuanlan.zhihu.com/p/27512619
实现内容(语义)上相关但视觉风格迥异的两张图像之间建立起像素级的对应关系,从而实现精确地视觉特征迁移
文章简介:
1.多种风格互换
两种风格之间的相互转换,真实照片和艺术画之间的相互转换,两张不同照片之间色彩纹理的相互转换
2.图像对偶
直接建立二者之间的像素对应非常困难。因此,我们引入了图像对偶的概念。假设存在图像A'和B,且存在这样的对偶关系:A:A' = B:B'。那么,该对偶关系隐含两条假设,1)A和A',同理B和B'是完全对齐的;2)A和B属于同一视觉风格而A'和B'属于另一视觉风格。
AB'的跨风格映射关系则可以转化为一个相同位置的映射AA'和一个统一风格内的映射A'B'
3.VGG网络的作用
根据A:A' = B:B',将已有的两张内容相似风格迥异的图片作为A、B‘,通过VGG网络提取feature map,根据高层feature map是语义相关,得到最高层A’和B的feature map ,通过上层采样及两条指导路径(A—A’—B',B'—B—A),得到下层的feature map,逐渐细化到底层。
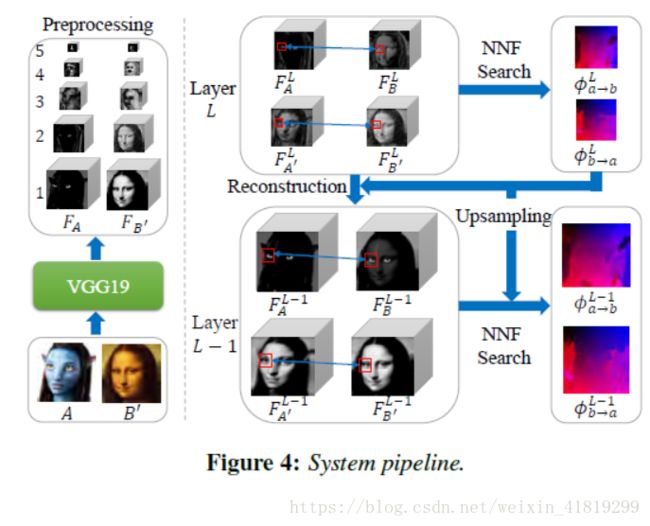
思考:
1.好像对我来说没啥用?高层到低层的细化,和其他论文里的粗到精差不多意思?
《Unpaired Image-to-Image Translation using Cycle-Consistent Adversarial Networks》
基于循环一致性对抗网络的非成对图像翻译
图像到图像的翻译,比如马——斑马、夏天——冬天
参考译文:
https://blog.csdn.net/summer2day/article/details/79369064
文章简介:
1.循环一致性损失
F(G(X))≈X(反之亦然)
其中 G:X→ Y F:Y→ X

2.CycleGAN 与pix2pix
pix2pix也可以做图像变换,它和CycleGAN的区别在于,pix2pix模型必须要求成对数据(paired data),而CycleGAN利用非成对数据也能进行训练(unpaired data)。
比如,我们希望训练一个将白天的照片转换为夜晚的模型。如果使用pix2pix模型,那么我们必须在搜集大量地点在白天和夜晚的两张对应图片,而使用CycleGAN只需同时搜集白天的图片和夜晚的图片,不必满足对应关系。因此CycleGAN的用途要比pix2pix更广泛,利用CycleGAN就可以做出更多有趣的应用。
3.GAN损失、循环一致性损失
GAN损失:
假设生成器F,判别器Dy
![]()
为了使GAN的训练更加稳定,使用平方损失代替Log似然后:
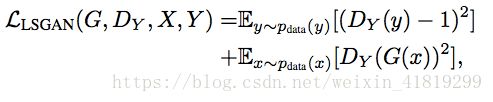
循环一致性损失(CycleGAN):
F(G(x))≈x和G(F(y))≈y

最终的损失由三部分组成:
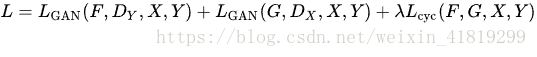
4、缺陷
在有几何学变换的时候,领域转换的效果不好。比如猫狗转换,橘子变苹果
思考:无,这篇文章有意思的貌似就是这个损失了
《Stable and Controllable Neural Texture Synthesis and Style Transfer Using Histogram Losses》
基于直方图损失的稳定可控的神经纹理合成与风格转换
参考译文:
https://blog.csdn.net/cicibabe/article/details/72901721
https://oldpan.me/archives/style-transfer-histogram-match
文章简介:
1.gram矩阵的不稳定性
实际中需要人工调参才可以得到不错的结果,原因在于gram矩阵在读取对象本身的特征同时对这个对象本身的分布并不“感冒”

2.直方图损失
不仅匹配均值,还匹配卷积神经网络中激活函数的统计分布,直方图代表的信息就是分布

3.局部风格损失
作者认为一张图不同区域有不同的风格,用一个模型去应对不同风格是不科学的,所以把内容图和风格图划分成多个区域进行风格迁移,并且分别计算损失。

《Multi-style Generative Network for Real-time Transfer》多模式实时传输生成网络
参考译文:
https://blog.csdn.net/wyl1987527/article/details/70832199
本文的主要贡献在于(1)提出灵感层,以及(2)在多尺度上匹配Gram矩阵的方法
文章简介:
1.残差网络结构

网络分为两大部分MSG-Net多风格生成网络,以及损耗网络
损耗网络是普通的VGG
MSG-Net分为两个子网络:Descriptive Network 和 Transformation Network:Descriptive Network使用VGG网络获得风格feature map,Transformation Network分为编码和解码两部分,下采样采用卷积的方式,上采样采用分数步长卷积。采用反射填充避免边缘的假边现象。在卷积层、分数步长卷积、Inspiration层之后都使用Instance normalization和Relu激励。

在四个灵感层,结合内容feature map 和风格gram矩阵进行计算,调整内容feature map
2.Inspiration layer 灵感层
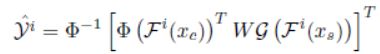
y^是Content调整后的feature maps,Fi(x)是指输入图片x在第i个尺度的feature maps,φ是代表对维度进行reshape操作,G是gram矩阵
3.其他尝试
风格化程度控制、颜色保持、空间控制、笔刷大小控制
思考:
1.这篇文章算是单模型多风格,为什么不是单模型任意风格?是灵感层公式的原因还是VGG提取feature map的原因还是其他?
《Demystifying Neural Style Transfer》阐明神经风格迁移
文章简介:
阐明Gram矩阵为什么能作为重建风格的依据,比起原文中相关性的解释,这篇论文更进一步把Gram矩阵转化成了squared Maximum Mean Discrepancy,(理论上证明了匹配特征映射的GM矩阵,等价于用二阶多项式核最小化最大平均差)这直接把图像和CNN中响应的分布联系了起来,并且可以通过替换计算MMD的方式尝试其他风格重建的目标计算方式。
风格转换本质上是一个领域适应问题,它对齐特征分布。作者尝试了其他方法(如线性、高斯、poly、BN等)也迁移了风格
关于Gram矩阵可以看看这篇文章:https://blog.csdn.net/tunhuzhuang1836/article/details/78474129
思考:不知道作者这个Different Transfer Methods是怎么处理的
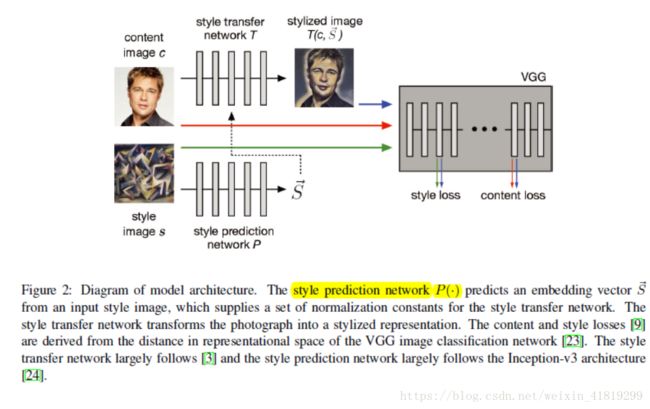
《Exploring the structure of a real-time, arbitrary neural artistic stylization network》一种实时任意风格转换网络
文章简介:
可以看做是 CIN的一个 follow-up 的工作,既然通过改变 CIN 层中仿射变换的参数,就可以得到不同的 style,换言之,只要任意给一个风格,我们只需要知道他的 CIN 层中的仿射变换的参数就可以了。沿着这个思路,Google Brain 的研究者设计和训练了一个 style prediction network去专门预测每个 style 的仿射变换的参数,style prediction network 需要大规模 style 和 content 图来进行训练。
这个方法的缺点也很明显,数据驱动的方式不可避免地导致风格化效果与训练数据集中 style 的种类和数量非常相关。
可以简单看做:基于风格训练的包含风格预测网络的改进CIN网络(单模型任意风格)
《Combining Markov Random Fields and Convolutional Neural Networks for Image Synthesis》
结合马尔科夫随机场和CNN的图像合成
参考译文:
https://blog.csdn.net/wangxc_123/article/details/76096082
https://blog.csdn.net/matrix_space/article/details/54478598
文章简介:
1.MRF的作用
可以将feature maps 分成很多的patch,找 patch之间的匹配。计算风格损失时,计算的是从每一个pathψi(ϕ(x)),我们反响最好的匹配path是ψNN(i)(ϕ(x)),

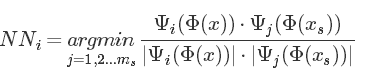
2.平方梯度范数

使合成的图片平滑化
思考:
这篇文章发表于2016年,现在基本没啥看头,在当时的贡献应该是损失的表示,用MRF后通过patch与patch的匹配,风格损失能更好地表示
《Improved Techniques for Training GANs》
2016年发表,目前引用量:485
参考译文:
https://blog.csdn.net/Layumi1993/article/details/52413235
http://blog.sina.com.cn/s/blog_76d02ce90102xq4d.html
https://blog.csdn.net/zijin0802034/article/details/58643889
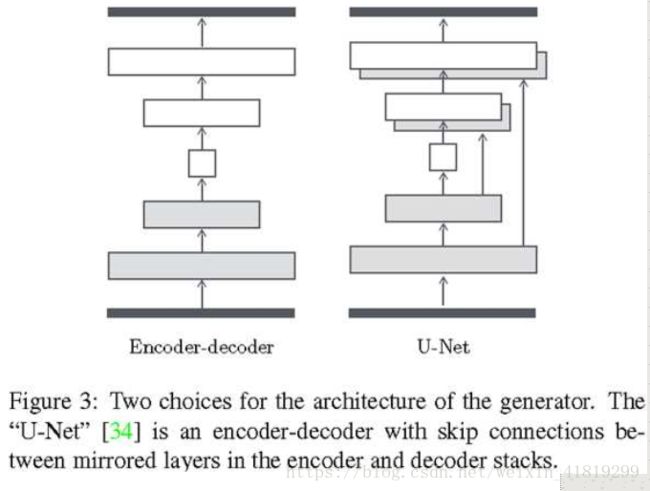
《Image-to-Image Translation with Conditional Adversarial Networks》有条件对抗网络的图像到图像翻译
参考译文:
https://www.cnblogs.com/punkcure/p/8029603.html
https://blog.csdn.net/Ruo_hua/article/details/77170117
文章简介:
1.Unet结构做layer 的skip
2.条件GAN损失函数

思考:
蛮复杂,细看浪费时间
《Stereoscopic Neural Style Transfer》3D立体风格迁移
参考译文:http://tech.ifeng.com/a/20180311/44902991_0.shtml
文章简介:
1.困难
左右视图一致性:很难在两个视图上产生几何一致的风格化纹理。结果就是,它会引起有问题的深度感知,并且造成观看者的 3D 疲劳
2.视差一致性损失
惩罚风格化结果在非遮挡区域的偏差。具体而言,在给定双向视差和遮挡掩膜的情况下,可以建立左视图和右视图之间的对应关系,并且惩罚了两个视图中都可见的重叠区域的风格不一致。
《Arbitrary Style Transfer with Deep Feature Reshuffle》具有深度特征重组的任意样式转换
参考译文:http://baijiahao.baidu.com/s?id=1603761045016451754&wfr=spider&for=pc
文章简介:
作者分析了使用整体统计信息与使用局部patch的优缺点,又可以称为参数化方法与非参数化方法。统计信息方法很难保证局部纹理结构,且有风格溢出题;patch方法会有某个patch多次重复使用,造成wash-out artifact冲蚀伪影。
于是作者将两种方法结合了一下,提出一种叫reshuffle的方法。将风格图的特征图做一个重排,“这种重排的结果首先先天地就符合 local 的 style loss”,且这种方法也不会影响整体的统计信息。
为了应对patch可能不够用的情况,“定义了一个相对 soft 的 parameter,通过这个参数控制 patch 的使用数量。当参数比较大的时候,其约束就比较强,这时候模型更接近于 global 方法;相反则更接近 non-parametric 的 local 的结果。通过设置参数可以动态地调节结果偏向,从而自适应地来融合两方的特征。”
最后的效果就是综合局部和整体来看,效果不错。
思考:确实之前没有这种局部和整体结合的研究,intersting!
清华美院博士后高峰
发表在ACM Multimeda 2018 (没找到这篇文章) 道子智能绘画系统
http://baijiahao.baidu.com/s?id=1605020907296884397&wfr=spider&for=pc
————————————————————————————————
《综述:图像风格化算法最全盘点 | 内附大量扩展应用》
http://baijiahao.baidu.com/s?id=1600455538813155076&wfr=spider&for=pc
《深度学习【23】图像风格化总结》
网址:https://blog.csdn.net/linmingan/article/details/78500616?locationNum=6&fps=1