gremlin语句详解
到了新公司用到了tinkerPop的gremlin语句,由于是全英文的文档。为了杜绝我鱼记忆,决定整理一下以后查看方便。嗯嗯~ o(* ̄▽ ̄*)o
附图:语句来源于图片
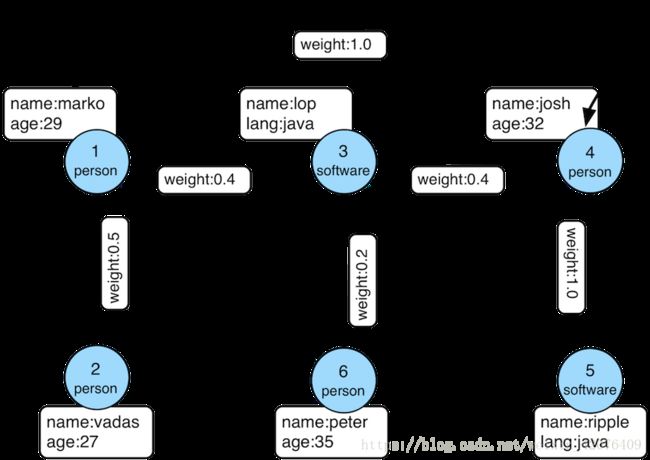
初步认识:
点:蓝色的圈代表顶点(查询语句中的V()),圈中的person代表顶点的名称,name和age为顶点的属性。
边:黑色的线代表边(查询语句中的E()),线上的knows代表边的名称,weight为边的属性。
一、Lambda Step
四个基础的步骤:map ,flatMap ,filter,sideEffect,branch
1. 查找节点属性
(1). V(1)=查询图中第一个顶点 .out() = 输出的顶点 .values("name") = 属性为name的值
(查询第一个顶点所有边中向外指的顶点,返回这些顶点的name的值)
gremlin> g.V(1).out().values('name')
==>lop
==>vadas
==>josh
(2).返回相同的数据使用map的方式
gremlin> g.V(1).out().map {it.get().value('name')}
==>lop
==>vadas
==>josh
2. has has的用法类似于过滤器的作用
(1).查找所有顶点中label边的值为person的(默认返回节点信息)
gremlin> g.V().hasLabel('person')
==>v[1]
==>v[2]
==>v[4]
==>v[6]
(2).使用过滤器filter的方式查找
gremlin> g.V().filter {it.get().label() == 'person'}
==>v[1]
==>v[2]
==>v[4]
==>v[6]
3. 进入sideEffect() 的任何内容都被传递到下一个步骤,但可能会发生一些中间过程。gremlin> g.V().hasLabel('person').sideEffect(System.out.&println)
v[1]
==>v[1]
v[2]
==>v[2]
v[4]
==>v[4]
v[6]
==>v[6]
4.choose()和branch()
解释:返回顶点的姓名,如果姓名为marko则返回年龄,其他的返回姓名。
gremlin> g.V().branch(values('name')).option('marko', values('age')).option(none, values('name'))
==>29
==>vadas
==>lop
==>josh
==>ripple
==>peter
gremlin> g.V().choose(has('name','marko'),values('age'),values('name'))
==>29
==>vadas
==>lop
==>josh
==>ripple
==>peter
二、AddEdge Step
此部分的主要功能是为已有的图形添加新的边。

1.addE()例一 以上图为例
解释:第一个顶点命名为a,查找出边为created的点(3),再次查找入边为created的点,并且这个点不是a,添加一条边,边的名称为co-developer,从a发出属性为:year,2009.
gremlin> g.V(1).as('a').out('created').in('created').where(neq('a')).addE('co-developer').from('a').property('year',2009)
==>e[12][1-co-developer->4]
==>e[13][1-co-developer->6]
2.addE()例二
gremlin> g.V(3,4,5).aggregate('x').has('name','josh').as('a').select('x').unfold().hasLabel('software').addE('createdBy').to('a')
==>e[14][3-createdBy->4]
==>e[15][5-createdBy->4]
3.addE()例三
解释:所有顶点为a,查找出边为created的顶点(3),增加边名称为createdBy,新增的边出点为a,属性名为acl,public。
gremlin> g.V().as('a').out('created').addE('createdBy').to('a').property('acl','public')
==>e[16][3-createdBy->1]
==>e[17][5-createdBy->4]
==>e[18][3-createdBy->4]
==>e[19][3-createdBy->6]
4.addE()例四
gremlin> g.V(1).as('a').out('knows').addE('livesNear').from('a').property('year',2009).inV().inE('livesNear').values('year')
==>2009
==>2009
5.addE()例五
gremlin> g.V().match(__.as('a').out('knows').as('b'),__.as('a').out('created').as('c'),__.as('b').out('created').as('c')).addE('friendlyCollaborator').from('a').to('b').property(id,13).property('project',select('c').values('name'))
==>e[13][1-friendlyCollaborator->4]
三、AddVertex Step
addE()例五 这个过程是用户给图形增加顶点,对于每一个传入对象,都创建一个顶点。此外,GraveTraceSaleStand维护了一个addV()方法。
1.例一 新增一个顶点person,属性为name=stephen。
gremlin> g.addV('person').property('name','stephen')
==>v[12]
2.例二 查看所有顶点的name
gremlin> g.V().values('name')
==>marko
==>vadas
==>lop
==>josh
==>ripple
==>peter
==>stephen
3.例三 所有顶点出边为knows,新增顶点,属性名为name=nothing。
gremlin> g.V().outE('knows').addV().property('name','nothing')
==>v[14]
==>v[16]
4.例四 查看所有顶点中name=nothing的id
gremlin> g.V().has('name','nothing')
==>v[16]
==>v[14]
四、AddProperty Step
addProperty()用户给图中的对象增加属性。不同于addV()和addE()
1.例一 给顶点1创建属性country=usa
gremlin> g.V(1).property('country','usa')
==>v[1]
2.例二 给顶点1创建属性city=sanfa fe,state=new mexico并返回所有属性名。
gremlin> g.V(1).property('city','santa fe').property('state','new mexico').valueMap()
==>[country:[usa], city:[santa fe], name:[marko], state:[new mexico], age:[29]]
3.例三 给顶点1创建属性age=35
gremlin> g.V(1).property(list,'age',35)
==>v[1]
4.例四 返回顶点1的所有属性值
gremlin> g.V(1).valueMap()
==>[country:[usa], city:[santa fe], name:[marko], state:[new mexico], age:[29, 35]]
5.例五 给顶点1增加属性friendWeight输出边为knows的值为weight之和,属性为ac=private
gremlin> g.V(1).property('friendWeight',outE('knows').values('weight').sum(),'acl','private')
==>v[1]
6.例六 查询顶点1的friendWeight的属性。
gremlin> g.V(1).properties('friendWeight').valueMap()
==>[acl:private]
五、Aggregate Step
aggregte()用于遍历所有特定的对象集合在一起。
1.例一
查找顶点1输出边是created的点(3)
gremlin> g.V( 1 ).out( 'created' )==>v[3]
将所有顶点1输出边为created的顶点聚合为x
gremlin> g.V(1).out('created').aggregate('x')
==>v[3]
查找所有顶点1输出边为created的顶点(3),再查找输入边为created的所有顶点
gremlin> g.V(1).out('created').aggregate('x').in('created')
==>v[1]
==>v[4]
==>v[6]
查找所有顶点1输出边为created的顶点(3),再查找输入边为created的所有顶点,再查找输出边为created的顶点
gremlin> g.V(1).out('created').aggregate('x').in('created').out('created')
==>v[3]
==>v[5]
==>v[3]
==>v[3]
查找所有顶点1输出边为created的顶点(3),再查找输入边为created的所有顶点,再查找输出边为created的顶点。过滤所有x(x = 顶点1输出边为created的顶点 = 3)的集合并输出name值。
gremlin> g.V(1).out('created').aggregate('x').in('created').out('created').where(without('x')).values('name')
==>ripple
六、And Step
and()同时满足and()要求的条件并输出。
1.例一 满足两个条件1.g.V().outE('knows') 2.g.V().values('age').is(lt(30))的名字
gremlin> g.V().and(outE('knows'),values('age').is(lt(30))).values('name')
==>marko
七、As Step
as(),是一步虚拟的操作,类似于by()和option().
1.例一 所有顶点命名为a,输出边为created的顶点命名为b,查询a和b。
gremlin> g.V().as('a').out('created').as('b').select('a','b')
==>[a:v[1], b:v[3]]
==>[a:v[4], b:v[5]]
==>[a:v[4], b:v[3]]
==>[a:v[6], b:v[3]]
八、By Step
by(),是一步虚拟的操作,一般用于通过条件分组查询。
1.例一 查询所有顶点,通过边的数量分组查询数量
gremlin> g.V().group().by(bothE().count())
==>[1:[v[2], v[5], v[6]], 3:[v[1], v[3], v[4]]]
2.例二 查询所有顶点,通过边的数量分组查询姓名
gremlin> g.V().group().by(bothE().count()).by('name')
==>[1:[vadas, ripple, peteby(),是一步虚拟的操作,一般用于通过条件分组查询。, lop, josh]]
3.例三 查询所有顶点,通过边的数量分组查询每组的数量
gremlin> g.V().group().by(bothE().count()).by(count())
==>[1:3, 3:3]
九、Cap Step
十、Coalesce Step
by(),是一步虚拟的操作,一般用于通过条件分组查询。
十一、Count Step
count(),统计遍历总数。
1.例一 统计所有顶点的总数
gremlin> g.V().count()
==>6
2.例二 统计所有顶点中label为person的总数
gremlin> g.V().hasLabel('person').count()
==>4
3.例三 查询顶点label值为person的输出边为created的数量,返回查询路径。
gremlin> g.V().hasLabel('person').outE('created').count().path()
==>[4]
4.例四 查询顶点label值为person的输出边为created的数量,遍历其内容 乘10返回路径。
gremlin> g.V().hasLabel('person').outE('created').count().map {it.get() * 10}.path()
==>[4, 40]
十二、Choose Step
choose()步骤,类似于if-else的步骤,判断条件走不同的路径。
1.例一 查找所有顶点中label为person的顶点,如果属性age小于30,查找入边的顶点,否则查找出边的顶点。
(顶点1age小于30没有入边无结果,顶点4age大于30查找出边顶点为3:name=lop和5:name=ripple)
gremlin> g.V().hasLabel('person').choose(values('age').is(lte(30)),__.in(),__.out()).values('name')
==>marko
==>ripple
==>lop
==>lop
2.例二 查找所有顶点中label为person的顶点,如果age为27则输出该顶点的入边顶点,如果age为32则输出该顶点的出边顶点。
(顶点2age为27,入边的顶点为1:name=marko,顶点4age为32,出边的顶点为3:name=lop,5:name=ripple)
gremlin>g.V().hasLabel('person').choose(values('age')).option(27,__.in()).option(32,__.out()).values('name')
==>marko
==>ripple
==>lop
十三、Coin Step
十四、Constant Step
constant()步骤,定义成常量。
1.例一 查询所有顶点,如果label名为person则返回名字,否则返回常量名为inhuman。
gremlin> g.V().choose(hasLabel('person'),values('name'),constant('inhuman'))
==>marko
==>vadas
==>inhuman
==>josh
==>inhuman
==>peter
十五、CyclicPath Step
十六、Dedup Step
dedup()步骤,过滤重复数据。
1. 例一 查询所有名为lang的顶点。dedup()过滤到重复的数据。
gremlin> g.V().values('lang')
==>java
==>java
gremlin> g.V().values('lang').dedup()
==>java
十七、Drop Step
drop()步骤,删除指定的元素或属性。
1. 例一 查询所有顶点中属性名为name并删除,遍历查询所有的顶点(name的属性已被删除)
gremlin> g.V().properties('name').drop()
gremlin> g.V().valueMap()
==>[age:[29]]
==>[age:[27]]
==>[lang:[java]]
==>[age:[32]]
==>[lang:[java]]
==>[age:[35]]
2.例二 查询并删除所有顶点(查询最后结果为空)
gremlin> g.V().drop()
gremlin> g.V()
十八、Explain Step
好像是用来解释的,没什么实质的作用
十九、Fold Step
fold()遍历所有的对象,并把他们聚合在一起。
1. 例一:查询顶点1出边为knows的name值,fold()聚合在一起为一个数组。
gremlin> g.V(1).out('knows').values('name')
==>vadas
==>josh
gremlin> g.V(1).out('knows').values('name').fold()
==>[vadas, josh]
二十、Graph Step
V-()步骤通常用于启动一个图形遍历,但也可以用于中间遍历。
1.例一 查找所有顶点name为marko,vadas或josh命名为person,再次查询所有顶点中name为lop或ripple,增加名为uses的边,从person发出。
gremlin> g.V().has('name', within('marko', 'vadas', 'josh')).as('person').V().has('name', within('lop', 'ripple')).addE('uses').from('person')
==>e[12][1-uses->3]
==>e[13][1-uses->5]
==>e[14][2-uses->3]
==>e[15][2-uses->5]
==>e[16][4-uses->3]
==>e[17][4-uses->5]
二十一、Group Step
group()步骤主要用于分组。
1.例一 通过顶点的label值对顶点进行分类
gremlin> g.V().group().by(label)
==>[software:[v[3], v[5]], person:[v[1], v[2], v[4], v[6]]]
2.例二 通过顶点的label值对顶点进行分类,获得他们的姓名。
gremlin> g.V().group().by(label).by('name')
==>[software:[lop, ripple], person:[marko, vadas, josh, peter]]
3.例三 通过顶点的label数量进行分类。
gremlin> g.V().group().by(label).by(count())
==>[software:2, person:4]
二十二、GroupCount Step
groupCount()步骤主要用于统计分组后的数量。
1.例一 通过顶点的label值对顶点进行分类
主要用于统计分组
1.例一 查询顶点label为person的年龄分布情况。
gremlin> g.V().hasLabel('person').values('age').groupCount()
==>[32:1, 35:1, 27:1, 29:1]
2.例二 同例一
gremlin> g.V().hasLabel('person').groupCount().by('age')
==>[32:1, 35:1, 27:1, 29:1]
二十三、Has Step
has() 作用可以过滤顶点,过滤边以及过滤属性。
例如:
has(key,value): 删除没有提供的键值对属性。has(key,predicate): 删除没有提供的键值。hasLabel(labels...): 删除没有对应label属性的内容。hasId(ids...): 删除没有对应id属性的内容。has(key): 删除没有该健的值的内容。hasNot(key): 删除有对应健的内容。has(key, traversal): 遍历没有结果的则删除。
1.例一 查询所有顶点中label为person的顶点。
gremlin> g.V().hasLabel('person')
==>v[1]
==>v[2]
==>v[4]
==>v[6]
2.例二 查询所有顶点中label为person的输出的顶点,并且name=vadas或josh。
gremlin> g.V().hasLabel('person').out().has('name',within('vadas','josh'))
==>v[2]
==>v[4]
3.例三 查询所有顶点中label为person的输出的顶点,并且name=vadas或josh,输出边label为created的边。
gremlin> g.V().hasLabel('person').out().has('name',within('vadas','josh')).outE().hasLabel('created')
==>e[10][4-created->5]
==>e[11][4-created->3]
4.例四 查询所有顶点中年龄在20~30之间的。
gremlin> g.V().has('age',inside(20,30)).values('age')
==>29
==>27
5.例五 查询所有顶点中年龄不在20~30之间的。
gremlin> g.V().has('age',outside(20,30)).values('age')
==>32
==>35
6.例六 查询所有顶点中姓名为josh和marko的并遍历属性。
gremlin> g.V().has('name',within('josh','marko')).valueMap()
==>[name:[marko], age:[29]]
==>[name:[josh], age:[32]]
7.例七 查询所有顶点中姓名不为josh和marko的并遍历属性。
gremlin> g.V().has('name',without('josh','marko')).valueMap()
==>[name:[vadas], age:[27]]
==>[name:[lop], lang:[java]]
==>[name:[ripple], lang:[java]]
==>[name:[peter], age:[35]]
8.例八 查询所有顶点中姓名不为josh和marko的并遍历属性。
gremlin> g.V().has('name',not(within('josh','marko'))).valueMap()
==>[name:[vadas], age:[27]]
==>[name:[lop], lang:[java]]
==>[name:[ripple], lang:[java]]
==>[name:[peter], age:[35]]
二十五、Is Step
is()类似于等于的作用。
1.例一 查询所有顶点中age=32的顶点。
gremlin> g.V().values('age').is(32)
==>32
2.例二 查询所有顶点中age<30的顶点。
gremlin> g.V().values('age').is(lte(30))
==>29
==>27
3.例三 查询所有顶点中age在30到40之间的顶点。
gremlin> g.V().values('age').is(inside(30, 40))
==>32
==>35
4.例四 查询所有顶点,条件为入边为created并且数量为1,显示name。
gremlin> g.V().where(__.in('created').count().is(1)).values('name')
==>ripple
5.例五 查询所有顶点,条件为入边为created并且数量大于2,显示name。
gremlin> g.V().where(__.in('created').count().is(gte(2))).values('name')
==>lop
6.例六 查询所有顶点,平均值在30到35之间。
gremlin> g.V().where(__.in('created').values('age').mean().is(inside(30d, 35d))).values('name')
==>lop
==>ripple
二十六、Limit Step
Limit()的主要作用和Range()类似,主要用于限制最小条数。
1.例一 查询所有顶点的前两条。
gremlin> g.V().limit(2)
==>v[1]
==>v[2]
二十七、Local Step
二十八、Match Step
二十九、Max Step
Max()的作用查找流中最大的值
1.例一 两种方式查找age最大的值。
gremlin> g.V().values('age').max()
==>35
gremlin> g.V().repeat(both()).times(3).values('age').max()
==>35
三十、Mean Step
mean()的主要作用用于求平均值。
1.例一 查询所有顶点的平均值
gremlin> g.V().values('age').mean()
==>30.75
2.例二 查询所有顶点,查询三次所有边,计算年龄的平均值
gremlin> g.V().repeat(both()).times(3).values('age').mean()
==>30.645833333333332
3.例三 查询所有顶点,查询三次所有去重边,计算年龄的平均值
gremlin> g.V().repeat(both()).times(3).values('age').dedup().mean()
==>30.75
三十一、Min Step
Min()的作用查找流中最小的值
1.例一 两种方式查找age最小的值。
gremlin> g.V().values('age').min()
==>27
gremlin> g.V().repeat(both()).times(3).values('age').min()
==>27
三十二、Or Step
or()或者的作用满足条件之一即可返回数据
1.例一 查找顶点的输出边为created或者输入边为created的数量大于1.
gremlin> g.V().or(__.outE('created'),__.inE('created').count().is(gt(1))).values('name')
==>marko
==>lop
==>josh
==>peter
三十三、Order Step
order()当需要对遍历流的对象进行排序时,可以利用Order()
1.例一 查询顶点的姓名并进行排序
gremlin> g.V().values('name').order()
==>josh
==>lop
==>marko
==>peter
==>ripple
==>vadas
2.例二 查询顶点的姓名并进行倒序排序
gremlin> g.V().values('name').order().by(decr)
==>vadas
==>ripple
==>peter
==>marko
==>lop
==>josh
3.例三 查询label为person的顶点,并使用age进行升序排序,显示其姓名。
gremlin> g.V().hasLabel('person').order().by('age', incr).values('name')
==>vadas
==>marko
==>josh
==>peter
三十四、Path Step
path()的作用主要用于查询每一步的路径。
1.例一 查询顶点输出顶点的输出顶点的姓名。
gremlin> g.V().out().out().values('name')
==>ripple
==>lop
1.例一 查询顶点输出顶点的输出顶点的姓名的路径。
gremlin> g.V().out().out().values('name').path()
==>[v[1], v[4], v[5], ripple]
==>[v[1], v[4], v[3], lop]
2.例二 如果边缘在路径中是必须的。
gremlin> g.V().outE().inV().outE().inV().path()
==>[v[1], e[8][1-knows->4], v[4], e[10][4-created->5], v[5]]
==>[v[1], e[8][1-knows->4], v[4], e[11][4-created->3], v[3]]
3.例三 如果by()在路径中是必须的。
gremlin> g.V().out().out().path().by('name').by('age')
==>[marko, 32, ripple]
==>[marko, 32, lop]
三十五、Profile Step
允许配置遍历的信息等。
三十六、Range Step
range()的主要作用是限制查询的条数
1.例一 查找所有顶点从下标1的开始查询3条。
gremlin> g.V().range(1,3)
==>v[2]
==>v[3]
三十七、Repeat Step
repeat()用于对给定的条件 进行循环。
1.例一 查询顶点1的输出顶点的路径循环两次,并显示其名字。
gremlin> g.V(1).repeat(out()).times(2).path().by('name')
==>[marko, josh, ripple]
==>[marko, josh, lop]
2.例二 查询所有顶点输出的顶点路径,显示名字,直到name=ripple时停止。
gremlin> g.V().until(has('name','ripple')).repeat(out()).path().by('name')
==>[marko, josh, ripple]
==>[josh, ripple]
==>[ripple]
三十八、Sack Step
三十九、Select Step
select()查询过滤需要显示的内容
1.例一 所有的顶点为a,输出的顶点为b,再次输出的顶点为c,查询a,b,c。
gremlin> g.V().as('a').out().as('b').out().as('c').select('a','b','c')
==>[a:v[1], b:v[4], c:v[5]]
==>[a:v[1], b:v[4], c:v[3]]
2.例二 所有的顶点为a,输出的顶点为b,再次输出的顶点为c,查询a,b。
gremlin> g.V().as('a').out().as('b').out().as('c').select('a','b')
==>[a:v[1], b:v[4]]
==>[a:v[1], b:v[4]]
3.例三 所有的顶点为a,输出的顶点为b,再次输出的顶点为c,查询a,b并返回姓名。
gremlin> g.V().as('a').out().as('b').out().as('c').select('a','b').by('name')
==>[a:marko, b:josh]
==>[a:marko, b:josh]
四十、SimplePath Step
simplePath()作用为过滤重复路径。
1.例一 查询顶点1的所有相邻顶点(2,3,4),再次查询相邻的顶点(1,1,4,6,3,5,1)
gremlin> g.V(1).both().both()
==>v[1]
==>v[4]
==>v[6]
==>v[1]
==>v[5]
==>v[3]
==>v[1]
2.例二 查询顶点1的所有相邻顶点(2,3,4),再次查询相邻的顶点(1,1,4,6,3,5,1),过滤重复路径。
gremlin> g.V(1).both().both().simplePath()
==>v[4]
==>v[6]
==>v[5]
==>v[3]
3.例三 查询顶点1的所有相邻顶点(2,3,4),再次查询相邻的顶点(1,1,4,6,3,5,1),过滤重复路径的路径查看。
gremlin> g.V(1).both().both().simplePath().path()
==>[v[1], v[3], v[4]]
==>[v[1], v[3], v[6]]
==>[v[1], v[4], v[5]]
==>[v[1], v[4], v[3]]
四十一、Store Step
四十二、Subgraph Step
用于提取一部分子图用于分析。
四十三、Sum Step
sum()作用查询条件的总和
1.例一 查询所有顶点中age的总和
gremlin> g.V().values('age').sum()
==>123
2.例二 查询所有顶点中所有边的时间的年龄之和
gremlin> g.V().repeat(both()).times(3).values('age').sum()
==>1471
四十四、Tail Step
tail()类似于limit()倒着获取结果集的内容。
1.例一 获取顶点中最后一条记录的名称。
gremlin> g.V().values('name').order().tail()
==>vadas
2.例二 获取顶点中最后一条记录的名称。
gremlin> g.V().values('name').order().tail(1)
==>vadas
3.例三 获取顶点中倒数三条记录的名称。
gremlin> g.V().values('name').order().tail(3)
==>peter
==>ripple
==>vadas
四十五、TimeLimit Step
四十六、Tree Step
四十七、Unfold Step
unfold()是fold()的反向形式,将放入数组的内容拆分出来。
1.例一 查询顶点1的输出顶点的集合,并增加gremlin和[1.23,2.34]的内容。
gremlin> g.V(1).out().fold().inject('gremlin',[1.23,2.34])
==>gremlin
==>[1.23, 2.34]
==>[v[3], v[2], v[4]]
2.例二 查询顶点1的输出顶点的集合,并增加gremlin和[1.23,2.34]的内容拆分出来。
gremlin> g.V(1).out().fold().inject('gremlin',[1.23,2.34]).unfold()
==>gremlin
==>1.23
==>2.34
==>v[3]
==>v[2]
==>v[4]
四十八、Union Step
union()支持任意数量的遍历结果的合并的结果集。
1.例一 查询顶点4的入点的年龄值和出点的lang值。
gremlin> g.V(4).union(__.in().values('age'),out().values('lang'))
==>29
==>java
==>java
2.例二 查询顶点4的入点的年龄值和出点的lang值的路径。
gremlin> g.V(4).union(__.in().values('age'),out().values('lang')).path()
==>[v[4], v[1], 29]
==>[v[4], v[5], java]
==>[v[4], v[3], java]
四十九、ValueMap Step
valueMap()映射元素的属性表示。
1.例一 查询所有顶点的属性。
gremlin> g.V().valueMap()
==>[name:[marko], age:[29]]
==>[name:[vadas], age:[27]]
==>[name:[lop], lang:[java]]
==>[name:[josh], age:[32]]
==>[name:[ripple], lang:[java]]
==>[name:[peter], age:[35]]
2.例二 查询所有顶点的属性age的结果。
gremlin> g.V().valueMap('age')