深度之眼【Pytorch】-Xavier、Kaiming初始化(附keras实现)
本文主要为深度之眼pytorch训练营二期学习笔记,详细课程内容移步:深度之眼 https://ai.deepshare.net/index
目录
背景知识
Xavier初始化
1.Xavier均匀分布初始化
2.Xavier正态分布初始化
Kaiming初始化
1.Kaiming正态分布初始化
2.Kaiming均匀分布初始化
Pytorch实现
Keras实现
背景知识
神经网络的训练过程中的参数学习是基于梯度下降法进行优化的。梯度下降法需要在开始训练时给每一个参数赋一个初始值,因此权重初始化的选取十分的关键,设定什么样的初始化方法关系到模型能否成功学习。那么如果我们把权重初始值全部设置为0,会怎样???通常来说,把权值初始值设置成0,不是一个理性的选择,因为实际上如果初始化为0的话,模型将无法学习。因为如果参数都为0,在第一遍前向计算时,所有的隐层神经元的激活值都相同。这样会导致深层神经元没有区分性。这种现象也称为对称权重现象。因此为了打破这个现象,比较好的方式就是给每个参数随机初始化一个值。
但是初始化的值太小,那么导致神经元的输入过小,经过多层之后信号就消失了,设置的过大导致数据状态过大,对于sigmoid类型的激活函数来说,激活值就一下子饱和了,梯度接近于0,也是不好训练的。
因此一般而言,参数初始化的区间应该根据神经元的性质进行差异化的设置。
Pytorch常见的几种初始化方法。

高斯分布初始化是最简单的初始化方法,参数从一个固定均值(比如0)和固定方差(比如0.01)的Gaussian分布进行随机初始化。均匀分布初始化是在一个给定的区间[−r,r]内采用均匀分布来初始化参数
Xavier初始化
适合饱和的激活函数:Sigmoid、Tanh类型
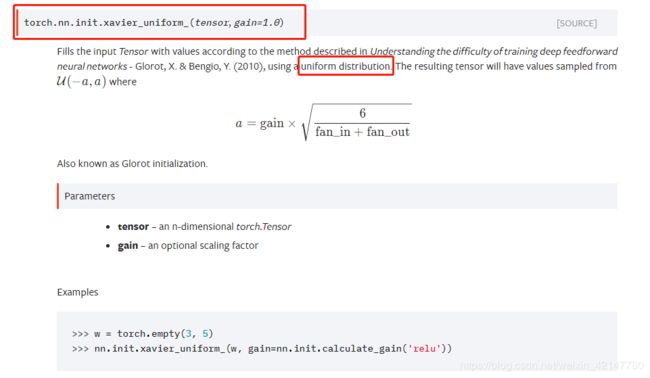
1.Xavier均匀分布初始化
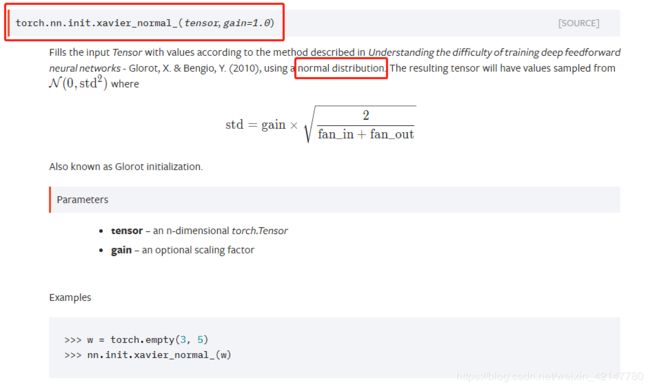
2.Xavier正态分布初始化
Kaiming初始化
适合非饱和的激活函数:Rulu及其变种类型
1.Kaiming正态分布初始化
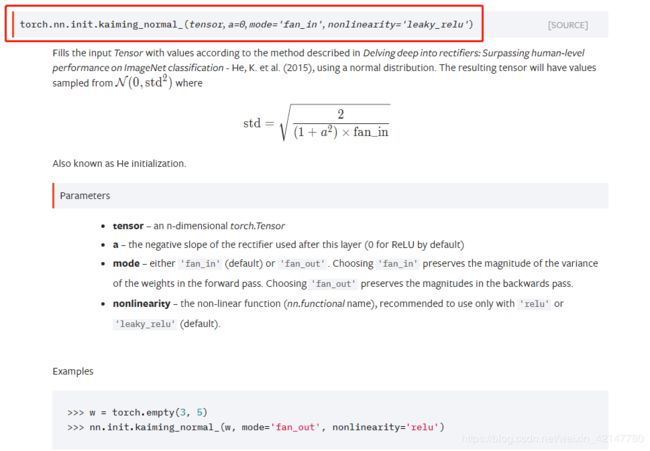
2.Kaiming均匀分布初始化

Pytorch实现
"""
代码来自深度之眼
"""
import os
import torch
import random
import numpy as np
import torch.nn as nn
class MLP(nn.Module):
def __init__(self, neural_num, layers):
super(MLP, self).__init__()
self.linears = nn.ModuleList([nn.Linear(neural_num, neural_num, bias=False) for i in range(layers)])
self.neural_num = neural_num
def forward(self, x):
for (i, linear) in enumerate(self.linears):
x = linear(x)
x = torch.relu(x)
print("layer:{}, std:{}".format(i, x.std()))
if torch.isnan(x.std()):
print("output is nan in {} layers".format(i))
break
return x
def initialize(self):
for m in self.modules():
if isinstance(m, nn.Linear):
# nn.init.normal_(m.weight.data, std=np.sqrt(1/self.neural_num)) # normal: mean=0, std=1
# a = np.sqrt(6 / (self.neural_num + self.neural_num))
#
# tanh_gain = nn.init.calculate_gain('tanh')
# a *= tanh_gain
#
# nn.init.uniform_(m.weight.data, -a, a)
# nn.init.xavier_uniform_(m.weight.data, gain=tanh_gain)
# nn.init.normal_(m.weight.data, std=np.sqrt(2 / self.neural_num))
nn.init.kaiming_normal_(m.weight.data)
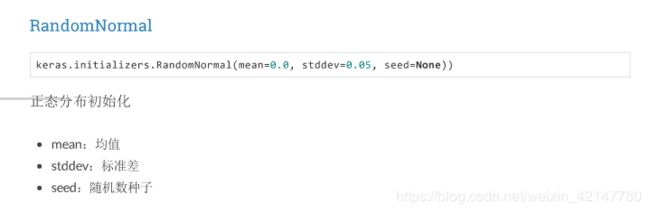
Keras实现
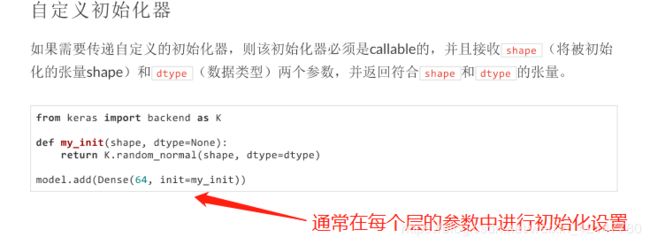
keras的初始化十分简单,在每添加一个层(Dense、Conv2D、LSTM等)的时候进行初始化的配置。