Hadoop+Hbase集群环境搭建
Hadoop+Hbase集群环境搭建
- 修改用户名
- 配置Hosts
- 安装 Java 环境
- 下载 Hadoop + Hbase
- 配置节点之间免密码登录
- 核心配置
- 配置Hadoop
- 配置Hbase
- 传递配置
- 启动
修改用户名
所有人用户名保持相同,考虑到不同用户名配置会出现各种问题(比较麻烦),请保持相同用户名 本教程所有节点 用户名均为 hadoop(实际上任意,这里为了方便,采用 hadoop) 如果用户名不同,可以手动修改用户名,鉴于直接修改用户名比较麻烦,这个教程是写给大象看的,此处采用更简 单的方法:新建用户,打开终端,依次输入如下指令:(用户名为:hadoop跳过)
#添加用户
sudo adduser hadoop
(如果你们小组的用户名已经统一,就不需要进行如下操作)
#之后会要求输入密码和验证密码
#然后会询问添加一些信息,可以一直回车跳过
#最后按一下 y 再回车就完成了创建用户的操作
#将用户设置为管理员
sudo adduser hadoop sudo
(如果你们小组的用户名已经统一,就不需要进行如下操作)
重启虚拟机
选择hadoop用户
在终端执行
sudo apt-get update
配置Hosts
- 将虚拟机网络链接改为桥接模式
- 打开虚拟机设置
- 点击网络适配器
- 将网络连接改为桥接模式

2. 打开终端,输入:
ifconfig
结果:
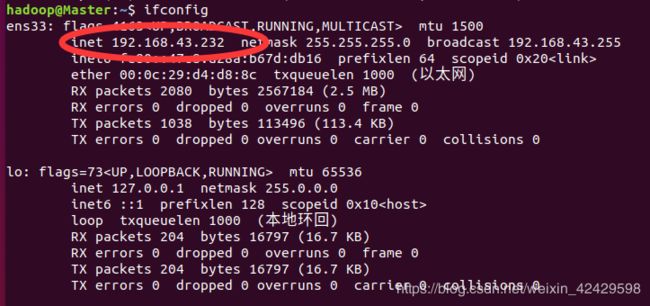
每个节点一定记下改ip,,选择一台机器作为主节点(Master),在终端中继续执行:
sudo gedit /etc/hostname
#主节点将ubuntu改为Master,其他节点依次改为Slave1,Slave2… 保存退出
#在终端中输入
sudo gedit /etc/hosts
#在 hosts 中,localhost 的下面,添加你们小组全部人的 IP,格式是:IP 空格 主机名
#举个例子,如果:
#主节点(Master)IP 是 192.168.43.1
#从节点(Slave1)IP 是 192.168.43.2
#从节点(Slave1)IP 是 192.168.43.3
#格式是:IP 空格 主机名
#那么 hosts 就添加如下内容:
#要保证ip地址在同一网段里,即查询出来的广播地址一样,否则,不相同的主机将不会被ping到,只能ping到别人
192.168.43.1 Master
192.168.43.2 Slave1
192.168.43.3 Slave2
#此处务必小组全部成员跟着一起改
#主节点起名叫 Master
#从节点分别起名为 Slave1,Slave2…
#格式是:IP 空格 主机名
#小组成员 Hosts 保持一致
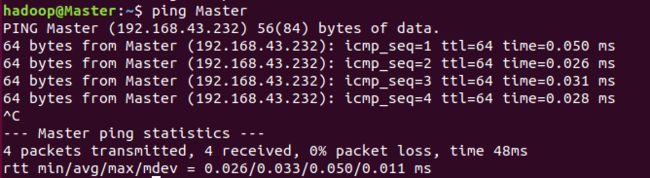
#在主节点中运行(Ctrl+C结束信息传递)
ping Master
ping Slave1
ping Slave2
…
在其他节点中执行:
ping Master
ping Slave2
…
#有几个节点就执行几次,若每次ping都能出现下图的内容,即hosts配置成功
安装 Java 环境
Hadoop 基于 Java,为了保证其能正常运行,我们需要先安装 Java 环境 介于部分系统Java环境配置有各种问题,
这里请所有节点重新完整安装一遍Java环境(除非你能保证自己下文有关Java的配置不出错) (最好安装java8,版本过高可能导致与hadoop、hbase不兼容,无法进入hbase的shell命令)(最好组内Java版本都一致)
- 方法:
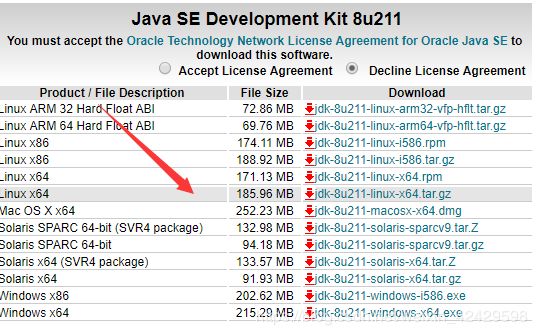
[1 ]打开下述链接:java下载
http://www.oracle.com/technetwork/java/javase/downloads/jdk8-downloads-2133151.html
下载指定的版本,这里选择 jdk-8u211-linux-x64.tar.gz,
[2 ]配置Java环境变量
#首先执行:
sudo su
cd /usr/lib
sudo chown -R hadoop jvm/
cd /
#将 jdk-8u172-linux-x64.tar.gz 解压至指定目录:
sudo tar -zxf ~/Downloads/jdk1.8.0_211 -C /usr/lib/jvm/
#编辑 主目录下的 .bashrc 文件:
sudo gedit ~/.bashrc
#在文件末尾添加:
export JAVA_HOME=/usr/lib/jvm/jdk1.8.0_211
export JRE_HOME=${JAVA_HOME}/jre
export CLASSPATH=.:${JAVA_HOME}/lib:${JRE_HOME}/lib
export PATH=${JAVA_HOME}/bin:$PATH
#使配置立即生效:
source ~/.bashrc
#检验变量值:
echo $JAVA_HOME
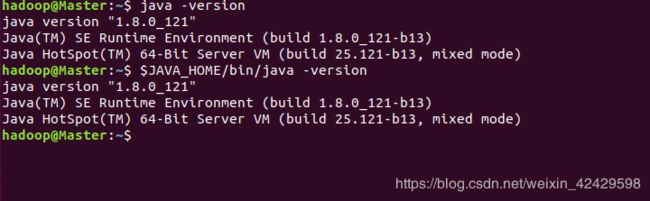
#查看Java版本:
java -version
$JAVA_HOME/bin/java -version# 与直接执行 java -version 一样
- 运行结果:
下载 Hadoop + Hbase
为了减少出错率,采用完全重装的方式,并且所有节点的hadoop与hbase版本都要一致,这里使用hadoop-3.1.1.tar.gz和hbase-1.4.9-bin.tar.gz,意味着以前的版本需要删除
#删除已经存在的 Hadoop 和 Hbase
sudo rm -r /usr/local/hadoop
sudo rm -r /usr/local/hbase
#可能会出错,可能是hadoop或hbase未关闭
下载hadoop+hbase:
所有的节点依次执行:或者直接去官网下载
hadoop-3.1.1下载
hbase1.4.9下载
#进入下载目录
cd ~/下载
#下载 Hadoop & Hbase
wget http://apache.claz.org/hadoop/common/hadoop-3.1.1/hadoop-3.1.1.tar.gz
wget https://archive.apache.org/dist/hbase/1.4.9/hbase-1.4.9-bin.tar.gz
#解压到 /usr/local/
sudo tar -zxf hadoop-3.1.0.tar.gz -C /usr/local/
sudo tar -zxf hbase-1.4.4-bin.tar.gz -C /usr/local/
#改名 + 授予权限
cd /usr/local/
mv hadoop-3.1.1/ hadoop/
mv hbase-1.4.9-bin/ hbase/
sudo chown -R hadoop hadoop/
sudo chown -R hadoop hbase/
#配置环境变量
sudo gedit ~/.bashrc
#在文件末尾添加
export PATH=$PATH:/usr/local/hadoop/bin:/usr/local/hadoop/sbin:/usr/local/hbase/bin
export HADOOP_HOME="/usr/local/hadoop"
export HADOOP_CONF_DIR="/usr/local/hadoop/etc/hadoop"
export HBASE_HOME="/usr/local/hbase"
#之后保存关闭,执行:
source ~/.bashrc
配置节点之间免密码登录
#依次执行
ssh-keygen -t rsa
cp ~/.ssh/id_rsa.pub ~/.ssh/authorized_keys# 中途遇到问题全部按回车
#所有节点依次执行:
ssh-copy-id hadoop@对应名字# @后面是Hosts中写好的主机名,在执行过程中会有提示,输入yes,同时也会叫其输入相对
应的主机的密码
#其他节点有几个就输入几次,比如一共有三台电脑,一台是主节点,两台从节点
#那么主节点需要输入两次(另外两台从节点)
#每个从节点需要输入两次(主节点和另一个从节点)
#例如:
#主节点输入:
ssh-copy-id hadoop@Slave1
ssh-copy-id hadoop@Slave2
核心配置
到此,从节点的组员可以休息了(但必须开机并保持联网),接下来交给主节点操作
配置Hadoop
#进入hadoop目录
cd /usr/local/hadoop/etc/hadoop/
#编辑 env
export JAVA_HOME="/usr/lib/jvm/jdk1.8.0_211/jre"#在除了第一行的任意行添加
#保存退出
#修改 core-site.xml
gedit core-site.xml
#内容修改如下
fs.defaultFS
hdfs://Master:9000
hadoop.tmp.dir
file:/usr/local/hadoop/tmp
#保存退出
#修改 hdfs-site.xml
gedit hdfs-site.xml
#内容修改如下
dfs.replication
3
dfs.namenode.name.dir
file:/usr/local/hadoop/tmp/dfs/name/
dfs.datanode.data.dir
file:/usr/local/hadoop/tmp/dfs/data/
#保存退出
#修改yarn-site.xml
gedit yarn-site.xml
#内容如下
yarn.resourcemanager.hostname
Master
yarn.nodemanager.aux-services
mapreduce_shuffle
#保存退出
#修改mapred-site.xml
gedit mapred-site.xml
#内容如下
mapreduce.framework.name
yarn
mapreduce.jobhistory.address
Master:10020
mapreduce.jobhistory.webapp.address
Master:19888
#保存退出
#修改workers
gedit workers
#内容如下
#这个文件比较特殊,它里面记录的主机名将成为 DataNode
#比如:
Master
Slave1
Slave2
#根据你的节点数和名称修改,一定要把组员都放进去,这里的这些名字同样是之前在 hosts 里面写好的
#主节点可根据情况不写进去(如果担心主节点电脑性能太低影响实验)
#保存退出
配置Hbase
#进入配置目录
cd /usr/local/hbase/conf
#修改 hbase-env.sh
gedit hbase-env.sh
#在除了第一行的任意位置添加
export JAVA_HOME="/usr/lib/jvm/jdk1.8.0_211/jre"#在除了第一行的任意行添加
export HBASE_MANAGES_ZK=true
#保存退出
#修改 hbase-site.xml
gedit hbase-site.xml
#内容如下:
hbase.rootdir
hdfs://Master:9000/hbase
hbase.cluster.distributed
true
hbase.zookeeper.quorum
此处把全部主机都写进去,比如:Master,Slave1,Slave2
#保存退出
#修改 regionservers (如果没有会自动创建)
gedit regionservers
#内容与 workers 一致即可,比如:
Master
Slave1
Slave2
传递配置
#各个从节点分别对着主节点执行如下两条语句:
sudo scp hadoop@Master:/usr/local/hadoop/etc/hadoop/* /usr/local/hadoop/etc/hadoop/
sudo scp hadoop@Master:/usr/local/hbase/conf/* /usr/local/hbase/conf/
启动
按顺序启动
启功hadoop
cd /usr/local/hadoop
./sbin/start-dfs.sh
启动yarn
./sbin/start-yarn.sh
启动hbase
cd /usr/local/hbase
bin/start-hbase.sh
访问浏览器
Master:9870
Master:8088
Master:16010