Hadoop-理论知识(大数据概况及Hadoop生态系统使用Java进行HDFS文件操作)
大数据概况及Hadoop生态系统以及使用Java进行HDFS文件操作
- 一、什么是大数据?
- 二、大数据特征
- 三、分布式计算
- 四、Hadoop是什么、为什么使用?
- 五、Hadoop vs RDBMS
- 六、Hadoop生态圈
- 七、Zookeeper
- 八、Hadoop架构
- 九、HDFS特点
- 十、HDFS CLI (命令行)
- 十一、hdfs dfsadmin
- 十二、HDFS角色
- 十三、HDFS架构
- 十四、HDFS副本机制
- 十五、HDFS高可用
- 十六、HDFS读文件和HDFS写文件
- 十七、HDFS文件格式
- 十八、使用Java进行HDFS文件操作
一、什么是大数据?
大数据是指无法在一定时间内用常规软件工具对其内容进行抓取、管理和处理的数据集合。
二、大数据特征
4V特征
- Volume(大数据量):90% 的数据是过去两年产生
- Velocity(速度快):数据增长速度快,时效性高
- Variety(多样化):数据种类和来源多样化 结构化数据、半结构化数据、非结构化数据
- Value(价值密度低):需挖掘获取数据价值
固有特征
- 时效性
- 不可变性
三、分布式计算
| 传统分布式计算 | 新的分布式计算 - Hadoop | |
|---|---|---|
| 计算方式 | 将数据复制到计算节点 | 在不同数据节点并行计算 |
| 可处理数据量 | 小数据量 | 大数据量 |
| CPU性能限制 | 受CPU限制较大 | 受单台设备限制小 |
| 提升计算能力 | 提升单台机器计算能力 | 扩展低成本服务器集群 |
四、Hadoop是什么、为什么使用?
Hadoop是一个开源分布式系统架构
分布式文件系统HDFS——解决大数据存储
分布式计算框架MapReduce——解决大数据计算
分布式资源管理系统YARN
处理海量数据的架构首选
非常快得完成大数据计算任务
已发展成为一个Hadoop生态圈
为什么使用?
高扩展性,可伸缩
高可靠性
多副本机制,容错高
低成本
无共享架构
灵活,可存储任意类型数据
开源,社区活跃
五、Hadoop vs RDBMS
| RDBMS | Hadoop | |
|---|---|---|
| 格式 | 写数据时要求 | 读数据时要求 |
| 速度 | 读数据速度快 | 写数据速度快 |
| 数据监管 | 标准结构化 | 任意结构数据 |
| 数据处理 | 有限的处理能力 | 强大的处理能力 |
| 数据类型 | 结构化数据 | 结构化、半结构化、非结构化 |
| 应用场景 | 交互式OLAP分析 ACID事务处理 企业业务系统 | 处理非结构化数据 海量数据存储计算 |
六、Hadoop生态圈
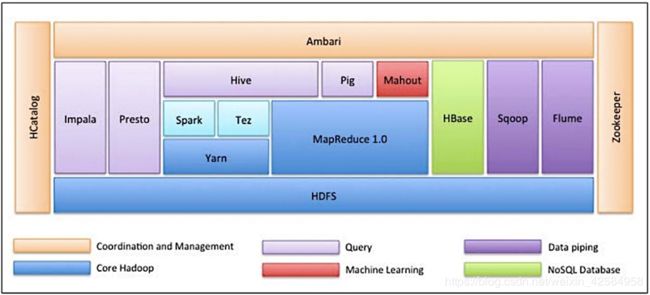
- HDFS:数据存储
- Zookeeper:软件,解决集群管理。看机器在不在,看机器状态,还有多少资源,就是集群管理员
- Flume:有更好的工具,初衷吧web日志送到hadoop环境下,数据传输工具
- Sqoop:数据迁移工具,功能单一。rdp->hadoop
- Hbase:关系型数据库,没有格式化,no sql两种理解:用特定指令去hbase查数据;一不仅仅是sql,通过hive包装用sql使用
- Oozie:定时系统。把各种任务定制为工作流程,通过定时在指定时间运行
- MapReduce(重要):应用框架(环境或者api),分布式处理框架
- Pig:脚本语言。早期是很重要的数据处理工具。知道一下,现在有了spark
- Mahout:机遇Mapreduce 的机器学习库,知道有这个东西就行,现在有了spark
- Yarn:MapReduce2.0是建立在Yarn之上的,在hadoop环境下,负责资源管理
- Hive:sql语句,会被翻译成Mapreduce2.0,执行引擎有3中选择:MapReduce2.0、Tez、Sparl
- Spark:可以作为Hive的执行引擎
- Tez:比MapReduce执行快
- Presto:解决交互式数据查询速度,解决hive处理交互式数据性能慢的问题,但是有局限性:在数据量和记忆数据处理能力没有Hive强,看应用场景再决定用什么(hive-presto)
- Impala:跟hive功能一样,但比hive性能快了不是一点点
- Hcatalog:保存元数据(元数据:是关于数据的数据,数据不是很大),其他工具都可以使用
- Ambarl:相当于hadoop环境下的管理软件,操作和管理不同功能块的执行情况
强调:支持sql:Impala、presto、hive、sqoop 玩大数据要sql过关,java功底也要强
重要的hdfs、hive、spark、Oozie、Hbase、sqoop、flume
七、Zookeeper
是一个分布式应用程序协调服务
解决分布式集群中应用系统的一致性问题
提供的功能
配置管理、命名服务、分布式同步、队列管理、集群管理等
特性:
全局数据一致
可靠性、顺序性、实时性
数据更新原子性
八、Hadoop架构

HDFS(Hadoop Distributed File System)
分布式文件系统,解决分布式存储
MapReduce
分布式计算框架
YARN
分布式资源管理系统
在Hadoop 2.x中引入
Common
支持所有其他模块的公共工具程序
九、HDFS特点
HDFS优点
支持处理超大文件
可运行在廉价机器上
高容错性
流式文件写入
HDFS缺点
不适合低延时数据访问场景
不适合小文件存取场景
不适合并发写入,文件随机修改场景
十、HDFS CLI (命令行)
基本格式
hdfs dfs -cmd
hadoop fs -cmd(已过时)
命令和Linux相似
-ls
-mkdir
-put
-rm
-help
十一、hdfs dfsadmin
| 命令 | 描述 |
|---|---|
| hdfs dfsadmin -report | 返回集群的状态信息 |
| hdfs dfsadmin -safemode enter/leave | 进入和离开安全模式 |
| hdfs dfsadmin -saveNamespace | 保存集群的名字空间 |
| hdfs dfsadmin -rollEdits | 回滚编辑日志 |
| hdfs dfsadmin -refreshNodes | 刷新节点 |
| hdfs dfsadmin -getDatanodeInfo node1:8010 | 获取数据节点信息 |
| hdfs dfsadmin -setQuota 10 /hdfs | 设置文件目录配额 |
十二、HDFS角色

Client:客户端
NameNode (NN):元数据节点—大脑
管理文件系统的Namespace/元数据
一个HDFS集群只有一个Active的NN(可以有standby的NN备用(与active的NN同步备份),万一Active的NN挂掉,备用NN顶替)
DataNode (DN):数据节点—心跳向NN表示还在运行
数据存储节点,保存和检索Block
数据计算
一个集群可以有多个数据节点
Secondary NameNode (SNN):从元数据节点(助手)
合并NameNode的edit logs到fsimage文件中
辅助NN将内存中元数据信息持久化
十三、HDFS架构

十四、HDFS副本机制
Block:数据块
HDFS最基本的存储单元
默认块大小:128M(2.x)
副本机制
作用:避免数据丢失
副本数默认为3
存放机制:
一个在本地机架节点
一个在同一个机架不同节点
一个在不同机架的节点

十五、HDFS高可用
在1.x版本中
存在Namenode单点问题
在2.x版本中
解决:HDFS Federation方式,共享DN资源
Active Namenode
对外提供服务
Standby Namenode
Active故障时可切换为Active
十六、HDFS读文件和HDFS写文件
HDFS读文件

HDFS写文件

十七、HDFS文件格式
HDFS支持以不同格式存储所有类型的文件
文本、二进制
未压缩、压缩
为了最佳的Map-Reduce处理,文件需可分割
SequenceFile
Avro File
RCFile&ORCFile
Parquet File
十八、使用Java进行HDFS文件操作
向hdfs写入本地文件
public class TestHDFS {
public static void writeToHDFS(String hdfsFile,String hdfsURL,String fileName) throws IOException {
Configuration cfg = new Configuration();
cfg.set("fs.defaultFS",hdfsURL);
FileSystem fs = FileSystem.get(cfg);
if (fs.exists(new Path(hdfsFile))){
FSDataOutputStream fsdos = fs.create(new Path(hdfsFile));
FileInputStream fis = new FileInputStream(fileName);
byte[] bytes = new byte[2048];
//首次读
int count = fis.read(bytes,0,2048);
while(count>0){
fsdos.write(bytes,0,count);
count = fis.read(bytes,0,2048);
}
fis.close();
fsdos.close();
fs.close();
}
}
public static void main(String[] args) throws IOException {
writeToHDFS(args[0],args[1],args[2]);
}
}
本地文件写hdfs
public class TestLOCAL {
public static void writeToLOCAL(String hdfsFile,String hdfsURL,String fileName) throws IOException {
Configuration cfg = new Configuration();
cfg.set("fs.defaultFS",hdfsURL);
FileSystem fs = FileSystem.get(cfg);
if (fs.exists(new Path(hdfsFile))){
FSDataInputStream fsdos = fs.open(new Path(hdfsFile));
FileOutputStream fis = new FileOutputStream(fileName);
byte[] bytes = new byte[2048];
//首次读
int count = fsdos.read(bytes,0,2048);
while(count>0){
fis.write(bytes,0,count);
count = fsdos.read(bytes,0,2048);
}
fis.close();
fsdos.close();
fs.close();
}
}
public static void main(String[] args) throws IOException {
writeToLOCAL(args[0],args[1],args[2]);
}
}