学习Hadoop第一课(Hadoop安装与配置)
步骤一:环境准备
在Hadoop安装与配置之前,需要准备的环境:虚拟机、Linux系统、配置JDK环境变量。
若以上还没准备,请参考以下文章:
1.VMware下载安装及CentOS7下载安装
2.Linux安装jdk1.8和配置环境变量
步骤二:下载
首先我们需要到Apache官网下载我们需要的Hadoop版本,Apache产品官网是:http://archive.apache.org/dist/ 如下图所示,我们可以看到有很多种产品,这里我们需要的是Hadoop因此我们点击hadoop。
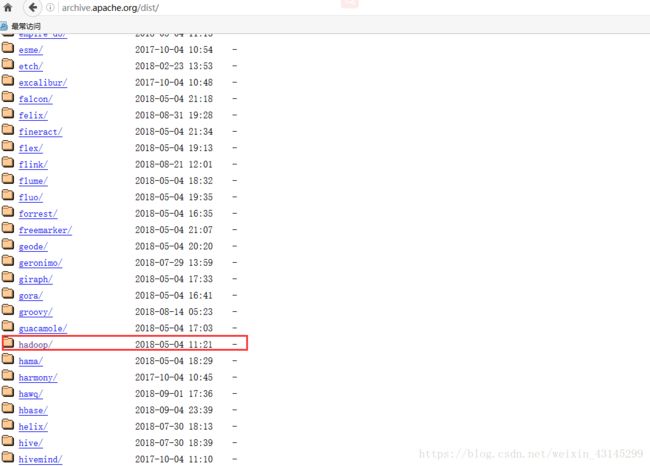
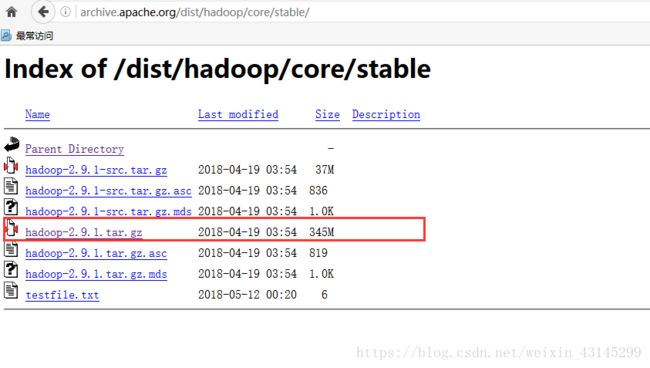
点击hadoop–》core–》然后选择要下载的版本
我是下载的最新的稳定版本–》stable
然后点击hadoop-2.9.1.tar.gz进行下载
步骤三:上传并解压
1.在/usr/local/src/目录下为Hadoop创建个目录:mkdir hadoop
2.rz上传:linux与windows 通过SecureCRT进行文件传输方式
3.解压:tar -zxvf hadoop-2.9.1.tar.gz
步骤四:分析解压的hadoop目录
如下图所示:
bin文件夹中存放的是一些可执行的脚本(我们用到的比较多的是hadoop、hdfs、yarn);
etc存放的是hadoop的配置文件,这个etc跟linux根目录下的etc是不一样的;
include存放的是本地库的一些头文件;
lib存放的是本地库的文件其所依赖的jar包在share目录下;
sbin里面存放的是关于启动和停止相关的内容(如 start-all.sh、start-dfs.sh、stop-all.sh、stop-dfs.sh等);

步骤五:修改5个配置文件
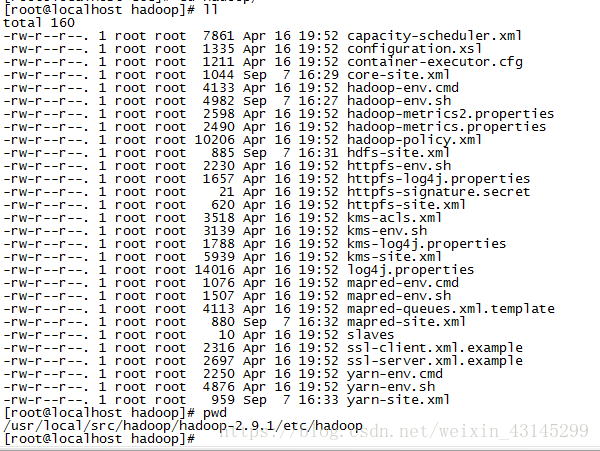
接下来我们开始修改5个配置文件了,首先我们进入/usr/local/src/hadoop/hadoop-2.9.1/etc/hadoop的配置文件目录(如下图所示),我们可以看到有很多配置文件。
1.修改配置文件 hadoop-env. sh
输入命令vim hadoop-env. sh,按回车,我们可以看到该文件的内容,如下图所示,其中有一行是配置JAVA环境变量的,初始值默认是${JAVA_HOME},我们需要把它改成具体的jdk所在的目录。

[root@localhost hadoop]# find / -name jdk
/usr/local/src/jdk
[root@localhost hadoop]# cd /usr/local/src/jdk
[root@localhost jdk]# ll
total 181192
drwxr-xr-x. 8 10 143 255 Mar 15 2017 jdk1.8
-rw-r--r--. 1 root root 185540433 Mar 16 2017 jdk-8u131-linux-x64.tar.gz
[root@localhost jdk]# cd jdk1.8/
[root@localhost jdk1.8]# pwd
/usr/local/src/jdk/jdk1.8
[root@localhost jdk1.8]#
#查看JDK安装目录
[root@localhost ~]# echo $JAVA_HOME
/usr/local/src/jdk/jdk1.8
[root@localhost ~]#
我的JDK路径:/usr/local/src/jdk/jdk1.8
修改如下:

2.修改配置文件core-site.xml
添加的内容在当中,需要说明的是,第一个property配置的是HDFS的NameNode的地址(主机名:端口号),第二个property配置的内容用来指定Hadoop运行时产生的文件的存放目录(初始化的tmp目录,后面格式化时会自动生成tmp文件)。添加完后按ESC键退出编辑模式,输入:wq保存并退出当前配置页面。
fs.defaultFS
hdfs://MrZhang:9090
hadoop.tmp.dir
/usr/local/src/hadoop/tmp
3.修改配置文件hdfs-site.xml
该文件是Hadoop的底层存储配置文件。
第一个key|value键值对表示:key表示namenode存储hdfs名字的空间的元数据文件;value表示自己指定的目录(不创建也会自动生成)。
第二个key|value键值对表示:key表示datanode上的一个数据块的物理的存储位置文件;value表示自己指定的目录(不创建也会自动生成)。
第三个key|value键值对表示:用来指定HDFS保存数据副本的数量(现在是伪分布式,所以数量是1,将来的集群副本数量默认是3)
dfs.namenode.name.dir
file:/usr/local/src/hadoop/hdfs/name
dfs.datanode.data.dir
file:/usr/local/src/hadoop/hdfs/data
dfs.replication
1
4.修改配置文件mapred-site.xml
我们在hadoop目录下发现文件列表中只有mapred-site.xml.template而没有mapred-site.xml,因此我们需要先把mapred-site.xml.template的后缀.template去掉(即重命名)
该配置告诉Hadoop以后mapreduce(MR)运行在YARN上。(表示MapReduce使用yarn框架)
mapreduce.framework.name
yarn
5.修改配置文件yarn-site.xml
需要说明的是,第一个property配置的内容是NodeManager获取数据的方式shuffle,第二个property配置的内容是指定YARN的ResourceManager的地址。
yarn.nodemanager.aux-services
mapreduce_shuffle
yarn.resourcemanager.hostname
MrZhang
至此,修改完了五个配置文件!
另外,若搭建Hadoop集群的话,只需要把这台安装配置好的Hadoop复制到另外Linux指定目录即可:
scp -r /usr/local/src/hadoop/hadoop-2.9.1/ 其他Linux系统:指定路径
#比如
scp -r /usr/local/src/hadoop/hadoop-2.9.1/ Hadoop-note2:/usr/local/src/hadoop/hadoop-2.9.1
#输入密码
并修改第六个配置文件:slaves文件,里面写上从节点所在的主机名字
6.修改配置文件slaves
vi slaves
MrZhang
MrZhang2
MrZhang3