零基础搭建Hadoop高可用环境——从安装VM虚拟机开始,结合使用Xshell
前景提要:这是一位比小白还小白的小小白写的,主要是为了完成作业。若有错误欢迎指正!!
第一章 vmware安装与Linux基础配置
1.1下载安装vmware
提供了3个安装软件的连接,是我在学习过程中用得到软件。
已经有很多大神都写了,(我自己是跟着老师走的),那我就不废话了直接上链接吧。
第一个是vmware虚拟机
VMware安装教程
第二个是xshell
xshell 是一个强大的安全终端模拟软件。
使用这个软件连接Linux系统。
Xshell安装教程
第三个是Xftp
Xftp可以在 UNIX/Linux 和 Windows PC 之间传输文件。
Xftp安装教程
1.2新建虚拟机
话不多说,新建过程看链接!
VMware新建虚拟机过程
1.3初步配置Linux
1.3.1启动虚拟机,配置IP
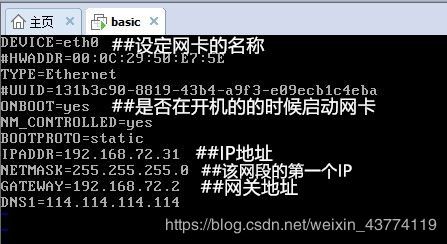
1、修改网络配置文件
vi /etc/sysconfig/network-scripts/ifcfg-eth0
linux主机刚安装好时,ONBOOT属性的缺省值为no,需要修改为yes,BOORPROTO缺省值为dhcp,需要修改为static。
然后设置IP地址,网络掩码,网关等。
2、重启network服务
service network restart
使网络设置生效。
3、测试是否成功
ping www.baidu.com
ping百度时出现图片上的内容,则成功。按Ctrl+C停止ping。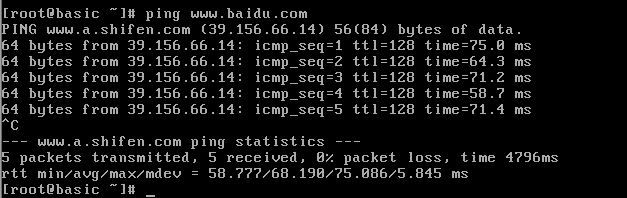
1.3.2删除70-persistent-net.rules
删除指令:
rm –fr /etc/udev/rules.d/70-persistent-net.rules
为什么要删除70-persistent-net.rules
因为如果虚拟机保留 /etc/udev/rules.d/70-persistent-net.rules这个文件,在通过该虚拟机克隆的时候:
1,文件被带到新的虚拟机中
2,vm变更了新的虚拟机的mac地址
你配置的/etc/sysconfig/network-scripts/ifcfg-eth0就不能应用
所以,新机器不能使用eth0接口
1.3.3关闭防火墙和Selinux
按序输入如下指令
service iptables stop
chkconfig iptables off
接着输入:修改SELINUX的值,将值设为disabled
vi /etc/selinux/config
这样设置更安全,如时间错了就把相应文件变成只读文件
1.3.4关机、拍摄快照
关机指令:poweroff
拍摄快照:当搭建好一个环境后,在没有添加任何数据时,或改变系统环境时,可以启用快照功能,虚拟机会保存虚拟系统里当前的环境,包括所安装的软件等设置;
当环境改变或需要重新搭建并系统初始化时,为免安装其他大型软件,可以启用快照的保存点进行恢复。作用就达到了快捷搭建环境的作用,也可以说是一种备份。
1.4克隆4台虚拟机
1.4.1用快照克隆4台虚拟机
选择某一个快照,并进行克隆
我一共配置了4台虚拟机,分别命名为node03、node04、node05、node06
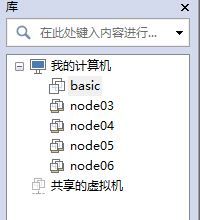
1.4.2配置4台虚拟机的主机名、IP、hosts
1、配置主机名
打开4台虚拟机,分别配置对应的主机名。
vi /etc/sysconfig/network
分别将HOSTNAME的值改为node03/node04/node05/node06
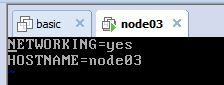
2、配置IP
分别配置4台机子的IP.
如node03的ip为192.168.72.33
则node04的ip为192.168.72.34
更改最后一位数
vi /etc/sysconfig/network-scripts/ifcfg-eth0
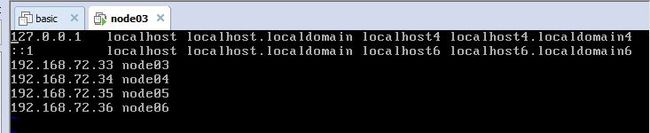
3、配置hosts
vi /etc/hosts
将四台虚拟机的IP和HOSTNAME都输入进去
配置完之后poweroff,拍快照,保存一个非常干净的Linux版本
4台虚拟机之间互相ping一下看是否能ping通,使用指令 ping nodeXX
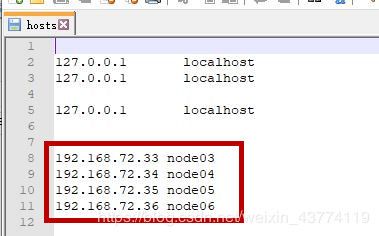
1.4.3配置Windows下的hosts文件
在我的电脑里,找到C:\Windows\System32\drivers\etc目录,打开hosts文件进行编辑。
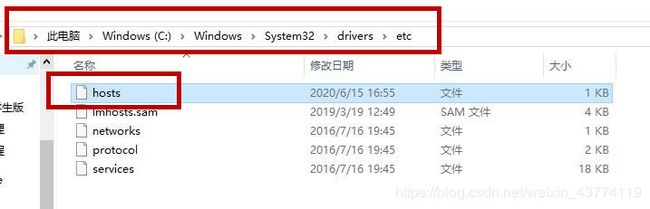
在hosts文件中,添加4台虚拟机。
配置完后,打开电脑的cmd窗口,ping node03/04/05/06 ,看是否ping成功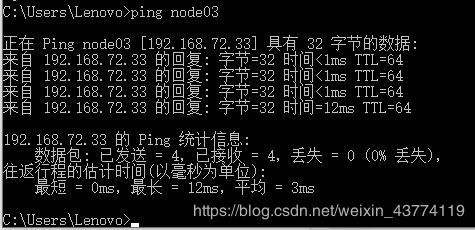
Linux的基础配置到此就完成了!恭喜你,你现在已经是青铜了!!让我们朝着白银出发吧!!!
第二章 Hadoop伪分布式安装
接下来的步骤都是用Xshell和Xftp来操作。
2.1在第一台虚拟机中用rpm安装jdk
我的第一台虚拟机是node03。
先在根目录下,将jdk上传。(这里就使用到了Xftp传输文件)
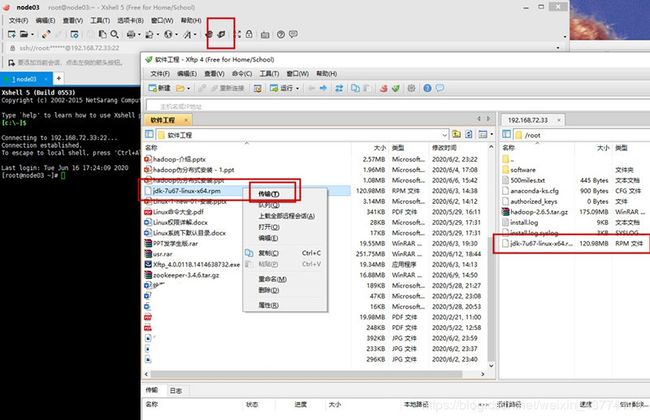
输入指令安装jdk
rpm -i jdk-7u67-linux-x64.rpm
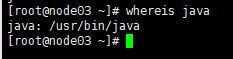
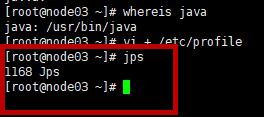
安装完成输入下面指令,查看安装路径。(记住路径,下面会使用到)
whereis java
修改配置文件,输入下面的vi指令
vi + /etc/profile
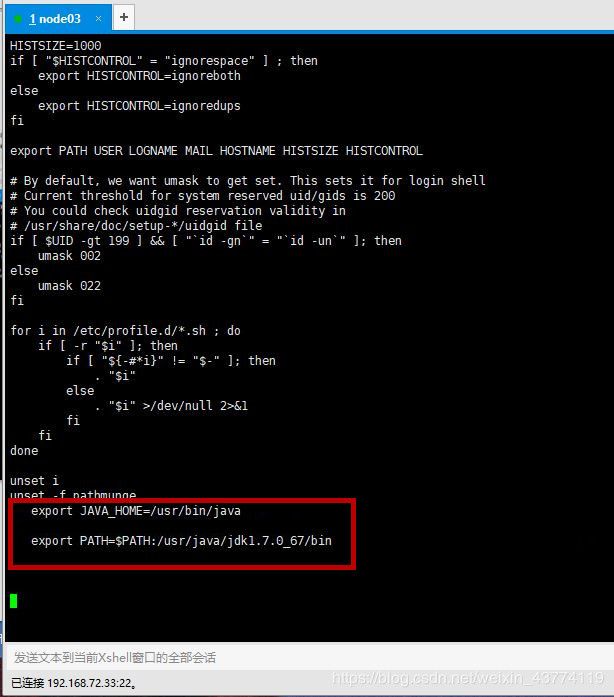
在打开的配置文件里添加或修改export语句,保存并退出。
export JAVA_HOME=/usr/bin/java
export PATH=$PATH:/usr/java/jdk1.7.0_67/bin
修改完后不要忘记
source /etc/profile
输入jps查看是否成功。成功会出现数字+jps。
2.2免密钥
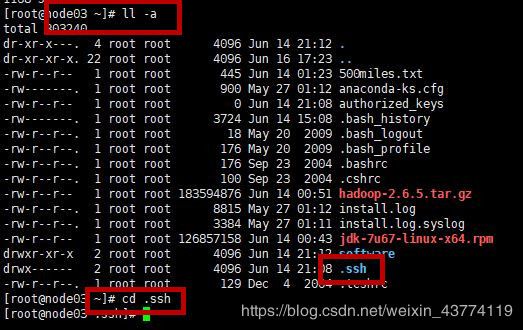
首先,在家目录下,ll –a ,看有无.ssh文件,
若无,则先ssh localhost一下(登录完别忘了exit)
然后,cd .shh进入ssh
在.ssh目录下输入下面两个指进行免密钥
ssh-keygen -t dsa -P '' -f ~/.ssh/id_dsa
cat ~/.ssh/id_dsa.pub >> ~/.ssh/authorized_keys

验证:ssh XXXX时不需要输入密码
ssh loocalhost(不要忘记exit)
ssh node03(不要忘记exit)
2.3安装Hadoop2.6.5
首先进入/opt 建立一个目录,这里的/smy是我自己创的文件名,你也可以设为别的名字
cd /opt
mkdir smy
把准备好的hadoop-2.6.5.tar.gz文件传给node03
tar xf hadoop-2.6.5.tar.gz -C /opt/smy
(注:-C的C 是大写)
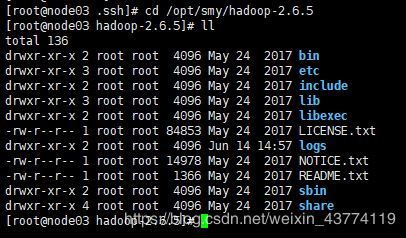
然后到/opt/smy目录下去看一下是否解压好了,ll可查看该目录下的文件,其中sbin这个文件夹很重要,放的是系统级别的一些可执行脚本。
cd /opt/smy/hadoop-2.6.5
要想在任意目录下启动hadoop,就要在配置文件里做些修改。
添加新的export HADOOP_HOME语句。
vi + /etc/profile
export JAVA_HOME=/usr/bin/java
export HADOOP_HOME=/opt/smy/hadoop-2.6.5
export PATH=$PATH:/usr/java/jdk1.7.0_67/bin:$HADOOP_HOME/bin:$HADOOP_HOME/sbin
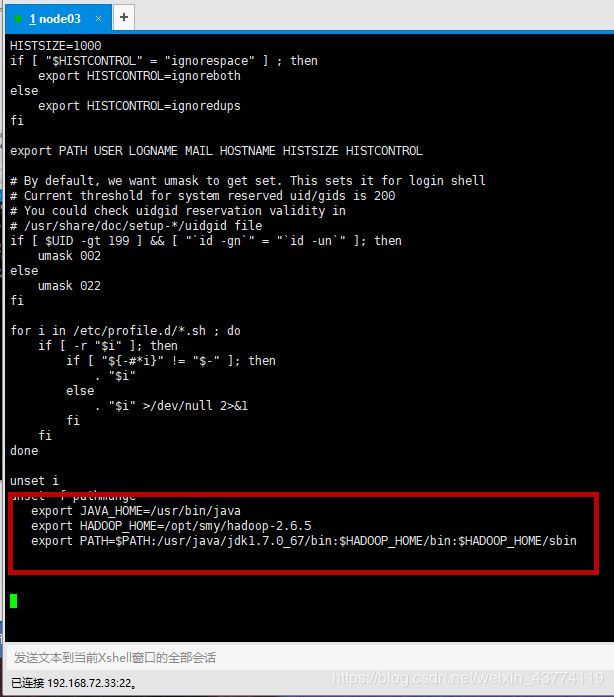
修改完后不要忘记
source /etc/profile
若输入hd按Tab键可以联想出hdfs
输入start-d按Tab键可以联想出start-dfs
就表示配置成功了
2.4修改Hadoop配置文件信息
cd /opt/smy/hadoop-2.6.5/etc/hadoop
注:以上路径的etc可不是根目录下的etc
我们可以看到该目录下有许多文件
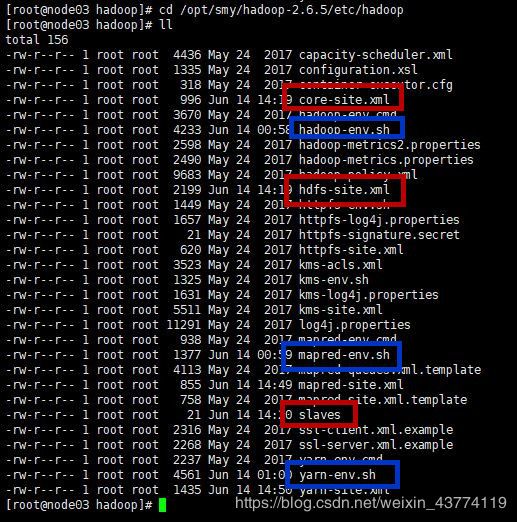
修改蓝色框的里三个文件
vi hadoop-env.sh
vi mapred-env.sh
vi yarn-env.sh
给这三个文件里的JAVA_HOME都改成绝对路径/usr/java/jdk1.7.0_67
若export之前有“#”,则把“#”删除
配置红色框里三个文件的信息
配置 vi core-site.xml
在与</configuration>之间插入下面代码
<!--配置主节点信息-->
fs.defaultFS</name>
hdfs://node03:9000</value>
</property>
<!--NameNode的元数据信息和DataNode的数据文件本来默认是保存一个临时的tmp文件里,不安全,所以现在要改一下-->
hadoop.tmp.dir</name>
/var/smy/hadoop/pseudo</value>
</property>
配置 vi hdfs-site.xml
在与</configuration>之间插入下面代码
<!--block的副本数-->
dfs.replication</name>
1</value>
</property>
<!--配置secondaryNameNode-->
dfs.namenode.secondary.http-address</name>
node03:50090</value>
</property>
配置slaves文件
vi slaves
将里面的内容删除,添加node03
2.5格式化hdfs
hdfs namenode -format
(只能格式化一次,再次启动集群不要执行,否则clusterID变了)
之前/var/smy/hadoop/pseudo这个文件不存在,格式化后就存在了,检查一下看存在没
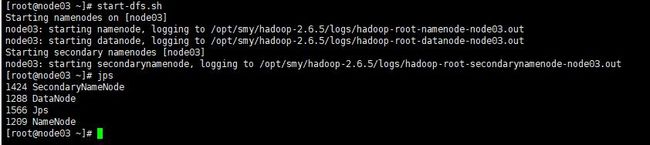
2.6启动集群
start-dfs.sh
启动后输入jps查看有哪些进程启动了起来。
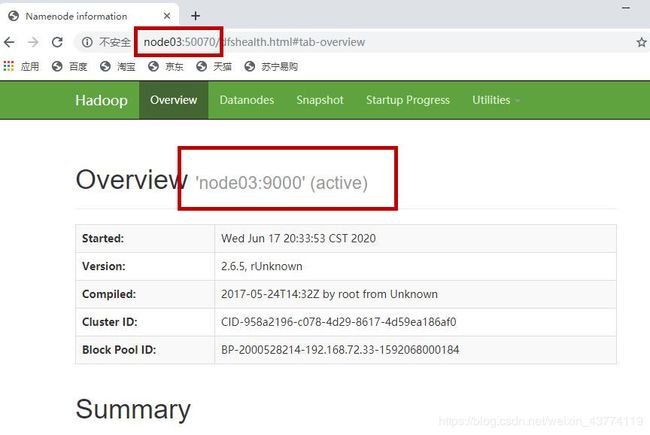
2.7在浏览器中打开node03:50070
2.8Hadoop伪分布式下运行wordcount
1.在hdfs里建立输入目录和输出目录
hdfs dfs -mkdir -p /data/input
hdfs dfs -mkdir -p /data/output
2.将要统计数据的文件上传到输入目录并查看
hdfs dfs -put 500miles.txt /data/input
hdfs dfs -ls /data/input
3.进入MapReduce目录
cd /opt/smy/hadoop-2.6.5/share/hadoop/mapreduce/
- 运行wordcount
hadoop jar hadoop-mapreduce-examples-2.6.5.jar wordcount /data/input /data/output/result
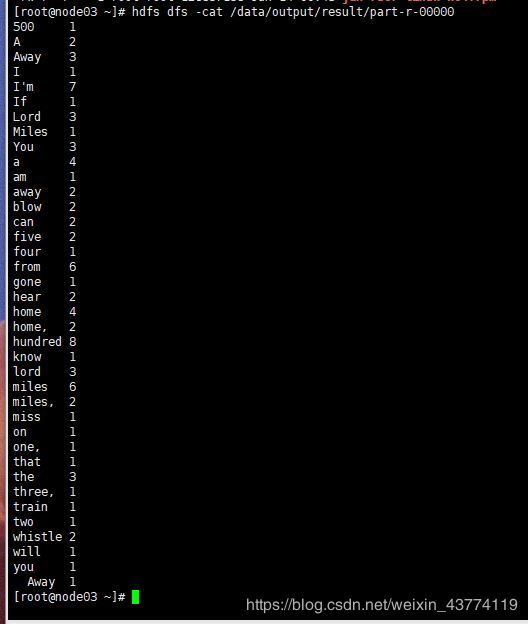
5.查看运行结果
hdfs dfs -ls /data/output/result
hdfs dfs -cat /data/output/result/part-r-00000
2.9关闭集群
打开集群记得关闭
stop-dfs.sh
恭喜你荣升白银,接下来我们朝着黄金出发吧!!
第三章 Hadoop高可用安装
3.1安装方案
这是在每台node上需要安装的内容
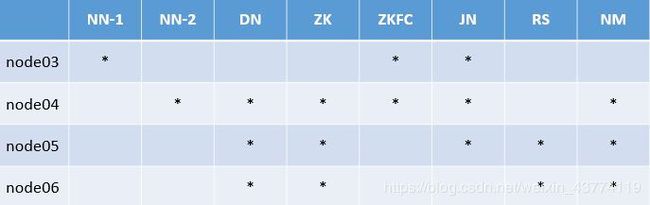
只有三台机子的同学,把NN-2也放成node03,DN放成node04和node05
3.2分发jdk和profile到node04、05、06
3.2.1分发jdk
先cd回到家目录,再分发jdk
scp jdk-7u67-linux-x64.rpm node04:`pwd`
scp jdk-7u67-linux-x64.rpm node05:`pwd`
scp jdk-7u67-linux-x64.rpm node06:`pwd`
注意:` 这一符号是数字1左边这个键
分发完成后,在Xshell的全部会话栏里一起ll,看jdk是否发送成功。
3.2.2安装jdk
分别在node04、05、06上执行rpm安装命令
rpm -i jdk-7u67-linux-x64.rpm
3.2.4分发profile文件
在node03上cd /etc,在此目录下把profile文件分发到node04、05、06上。
scp profile node04:`pwd`
scp profile node05:`pwd`
scp profile node06:`pwd`
利用Xshell全部会话栏,source /etc/profile
利用Xshell全部会话栏,jps,看04、05、06这三台机子的jdk是否装好。
3.3同步服务器时间
3.3.1查看时间
全部会话,查看每台机子当前的时间
date
时间不能差太大,否则集群启动后某些进程跑不起来
3.3.2同步时间
若时间不同步,则需要同步时间
1.yum进行时间同步器的安装
yum -y install ntp
2.执行同步命令
ntpdate time1.aliyun.com
和阿里云服务器时间同步
3.4装机之前的配置文件检查
3.4.1查看HOSTNAME是否正确
cat /etc/sysconfig/network
3.4.2查看IP映射是否正确
cat /etc/hosts
若不正确,可以修改文件,也可以把node03上的用scp分发过去。
3.4.3查看SELINUX是否正确
cat /etc/sysconfig/selinux
SELINUX=disabled
3.4.4查看防火墙是否关闭
service iptables status
3.5NN与其他三台机子之间的免密钥设置
- 在家目录下 ll –a看下有无.ssh文件,如果没有就ssh loalhost一下,记住要exit
- cd .ssh ,并ll查看一下
- 把node03的公钥发给其他三台机子
scp id_dsa.pub node04:`pwd`/node03.pub
scp id_dsa.pub node05:`pwd`/node03.pub
scp id_dsa.pub node06:`pwd`/node03.pub

在node03上分别ssh node04,ssh node05,ssh node06,看是否能免密钥登录(每次ssh不要忘记exit)
4. 在node04的.ssh目录下看是否有node03.pub
如果有,那就追加到authorized_keys
cat node03.pub >> authorized_keys
并且在node03上ssh node04看是否免密钥了,给node05、06都追加一下node03.pub,也就是在node05、06的.ssh目录下执行cat node03.pub >> authorized_keys
3.6NN之间的免密钥
node03与node04间互相免密钥: node03可免密钥登录node04,那现需node04上能免密钥登node03,所以在node04上:
ssh-keygen -t dsa -P '' -f ~/.ssh/id_dsa
cat ~/.ssh/id_dsa.pub >> ~/.ssh/authorized_keys
ssh localhost验证一下
再输入下面指令,分发到node03上:
scp id_dsa.pub node03:`pwd`/node04.pub
在node03的.ssh目录下追加node04.pub
cat node04.pub >> authorized_keys
在node04上ssh node03验证一下可否免密钥登录
3.7修改NameNode的配置信息
3.7.1修改配置hdfs-site.xml文件
1、进入目录
cd cd /opt/smy/hadoop-2.6.5/etc/hadoop
2、修改配置文件 hdfs-site.xml
vi hdfs-site.xml
去掉snn的配置,将下述代码从文件中删除。
dfs.namenode.secondary.http-address</name>
node03:50090</value>
</property>
(以下代码,你需要根据自己情况修改节点和目录)
3、修改配置文件 hdfs-site.xml
vi hdfs-site.xml
增加以下property
<!-- 为namenode集群定义一个services name -->
dfs.replication</name>
3</value>
</property>
dfs.nameservices</name>
mycluster</value>
</property>
<!-- nameservice 包含哪些namenode,为各个namenode起名 -->
dfs.ha.namenodes.mycluster</name>
nn1,nn2</value>
</property>
<!-- 名为nn1的namenode的rpc地址和端口号,rpc用来和datanode通讯 -->
dfs.namenode.rpc-address.mycluster.nn1</name>
node03:8020</value>
</property>
dfs.namenode.http-address.mycluster.nn1</name>
node03:50070</value>
</property>
<!-- 名为nn2的namenode的rpc地址和端口号,rpc用来和datanode通讯 -->
dfs.namenode.rpc-address.mycluster.nn2</name>
node04:8020</value>
</property>
dfs.namenode.http-address.mycluster.nn2</name>
node04:50070</value>
</property>
<!-- namenode间用于共享编辑日志的journal节点列表 -->
dfs.namenode.shared.edits.dir</name>
qjournal://node03:8485;node04:8485;node05:8485/mycluster</value>
</property>
<!-- journalnode 上用于存放edits日志的目录 -->
dfs.journalnode.edits.dir</name>
/var/smy/hadoop/ha/jn</value>
</property>
dfs.client.failover.proxy.provider.mycluster</name>
org.apache.hadoop.hdfs.server.namenode.ha.ConfiguredFailoverProxyProvider</value>
</property>
<!-- 一旦需要NameNode切换,使用ssh方式进行操作 -->
dfs.ha.fencing.methods</name>
sshfence</value>
</property>
<!-- 如果使用ssh进行故障切换,使用ssh通信时用的密钥存储的位置 -->
dfs.ha.fencing.ssh.private-key-files</name>
/root/.ssh/id_dsa</value>
</property>
<!-- 指定该集群出现故障时,是否自动切换到另一台namenode -->
dfs.ha.automatic-failover.enabled</name>
true</value>
</property>
3.7.2修改配置core-site.xml文件
修改配置文件 core-site.xml
vi core-site.xml
添加下面property
<!– 集群名称mycluster-->
fs.defaultFS</name>
hdfs://mycluster</value>
</property>
<!– zookeeper布署的位置-->
ha.zookeeper.quorum</name>
node04:2181,node05:2181,node06:2181</value>
</property>
3.7.3修改配置slaves文件
修改配置文件 slaves
vi slaves
在文件里增加你的另外三台虚拟机
node04
node05
node06
3.7.4安装另外三台的hadoop
1.首先,进入/opt目录
cd /opt
2.再,将其下的smy目录分发到node04、05、06
scp –r smy/ node04:`pwd`
scp –r smy/ node05:`pwd`
scp –r smy/ node06:`pwd`
3.8安装ZOOKEEPER
3.8.1解压安装
将事先准备好的zookeeper-3.4.6.tar.gz,解压安装
tar xf zookeeper-3.4.6.tar.gz -C /opt/smy
3.8.2修改配置文件
1.修改zookeeper的配置文件
先进入zookeeper-3.4.6所在目录
cd /opt/smy/zookeeper-3.4.6/conf
给zoo_sample.cfg改名(这里为了不出错,直接复制拷贝一份文件,在进行修改)
cp zoo_sample.cfg zoo.cfg
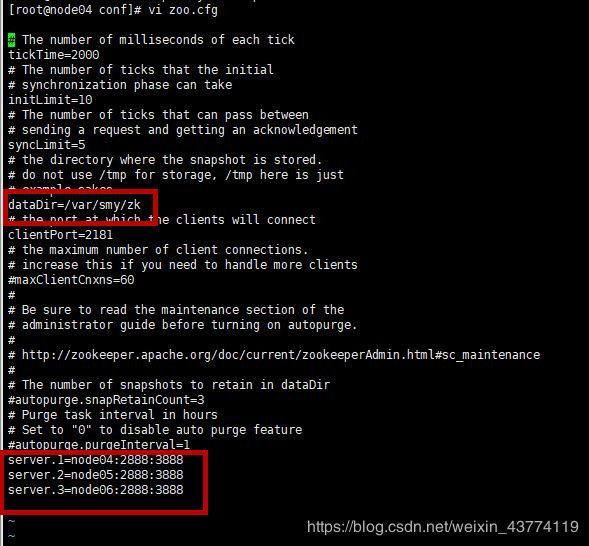
2.修改zoo.cfg文件
vi zoo.cfg
修改dataDir的值
dataDir=/var/smy/zk
并在末尾追加如下代码。(其中2888主从通信端口,3888是当主挂断后进行选举机制的端口)
server.1=node04:2888:3888
server.2=node05:2888:3888
server.3=node06:2888:3888
3.8.3分发zk
scp -r zookeeper-3.4.6/ node05:`pwd`
scp -r zookeeper-3.4.6/ node06:`pwd`
用ll /opt/smy检查下看分发成功没
3.8.4配置编号
给每台机子创建刚配置文件里的路径
mkdir -p /var/smy/zk
给每台机子配置其编号(必须是阿拉伯数字)
在node04下输入:
echo 1 > /var/smy/zk/myid
cat /var/smy/zk/myid
在node05下输入:
echo 2 > /var/smy/zk/myid
cat /var/smy/zk/myid
在node06下输入:
echo 3 > /var/smy/zk/myid
cat /var/smy/zk/myid
3.8.5配置ZOOKEEPER_HOME
在/etc/profile里面配置
vi + /etc/profile
添加ZOOKEEPER_HOME和增加PATH值
export ZOOKEEPER_HOME=/opt/smy/zookeeper-3.4.6
export PATH=$PATH:/usr/java/jdk1.7.0_67/bin:$HADOOP_HOME/bin:$HADOOP_HOME/sbin:$ZOOKEEPER_HOME/bin
3.8.6分发profile
在把/etc/profile分发到其他node05、node06
scp /etc/profile node05:/etc
scp /etc/profile node06:/etc
然后在node04、05、06里source /etc/profie
验证source这句是否完成,输入zkCli.s,按Tab可以把名字补全zkCli.sh
3.8.7启动zk
启动zookeeper
全部会话:
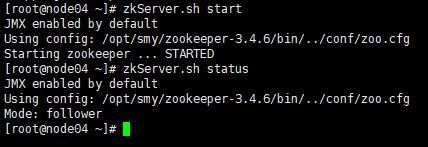
zkServer.sh start
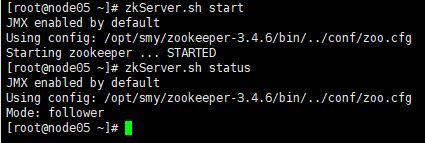
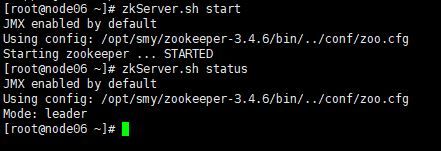
接着查看每个zookeeper节点的状态(有1个leader,2个follower,一般来说leader是最大的那个)
zkServer.sh status
注意:如果启动不起来,请把/etc/profile里的JAVA_HOME改
成绝对路径。
三台node的zookeeper结果如下图所示:
3.8.8关闭zk
zkServer.sh stop
3.9启动journalnode
启动journalnode是为了使两台namenode间完成数据同步
在03、04、05三台机子上分别把journalnode启动起来
hadoop-daemon.sh start journalnode
用jps检查下进程启起来了没
3.10格式化NameNode
首先,随意挑一台namenode上执行,另一台namenode不用执行,否则clusterID变了,找不到集群了。
hdfs namenode –format
然后,启动刚刚格式化的这台namenode
hadoop-daemon.sh start namenode
最后,我们要给另一台namenode同步一下数据,
hdfs zkfc -formatZK
在node04上执行zkCli.sh打开zookeeper客户端看hadoop-ha是否打开
3.11启动hdfs集群
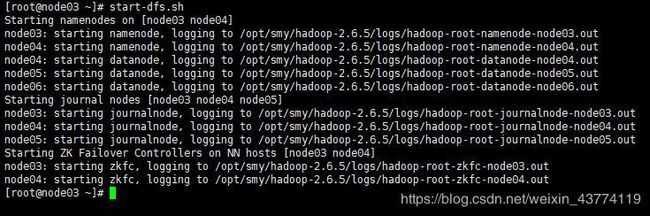
在node03上启动hdfs集群
start-dfs.sh
如果某个节点没起来,那么到hadoop目录下去看那个node的日志文件log
注意:你下一次启动hdfs集群的时候不需要再用hadoop-daemon.sh start journalnode命令启动journalnode
只要start-dfs.sh就可以了。我们之前启动journalnode是为了同步两个namenode之间的信息。
然后,全部会话jps看一下都起来些什么进程。
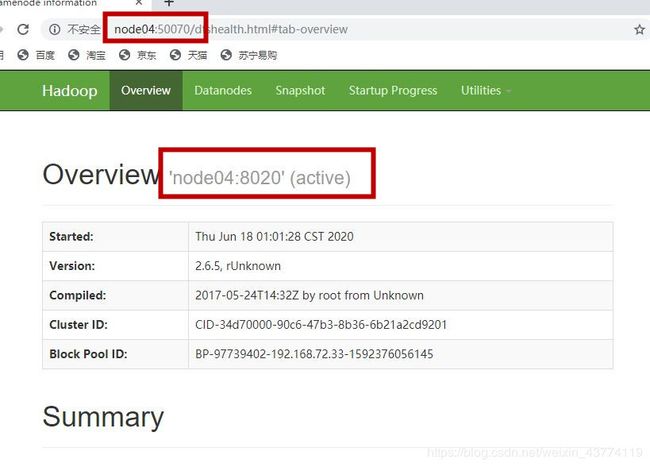
3.12用浏览器访问node03:50070和node04:50070
可以看到其中有一台node是active,另一台node是standby。

3.12为MapReduce做准备
3.12.1备份mapred-site
先进入下述目录找到mapred-site.xml.template
cd /opt/smy/hadoop-2.6.5/etc/hadoop
把mapred-site.xml.template留个备份,并且改下名字
cp mapred-site.xml.template mapred-site.xml
3.12.2修改配置mapred-site.xml
vi mapred-site.xml
在mapred-site.xml里添加如下property
mapreduce.framework.name</name>
yarn</value>
</property>
3.12.3修改配置yarn-site.xml
vi yarn-site.xml
在yarn-site.xml里添加如下property
yarn.nodemanager.aux-services</name>
mapreduce_shuffle</value>
</property>
yarn.resourcemanager.ha.enabled</name>
true</value>
</property>
yarn.resourcemanager.cluster-id</name>
cluster1</value>
</property>
yarn.resourcemanager.ha.rm-ids</name>
rm1,rm2</value>
</property>
yarn.resourcemanager.hostname.rm1</name>
node05</value>
</property>
yarn.resourcemanager.hostname.rm2</name>
node06</value>
</property>
yarn.resourcemanager.zk-address</name>
node04:2181,node05:2181,node06:2181</value>
</property>
3.12.4分发mapred-site.xml和yarn-site.xml
把mapred-site.xml和yarn-site.xml 分发到node04、05、06
scp mapred-site.xml yarn-site.xml node04:`pwd`
scp mapred-site.xml yarn-site.xml node05:`pwd`
scp mapred-site.xml yarn-site.xml node06:`pwd`
3.12.5node05和node06免密钥
由于node05和node06都是resourcemanager,所以它俩应该相互免密钥
————————————————————
1、node05上免密钥登录node06:
在node05的.ssh目录下生成密钥
ssh-keygen -t dsa -P '' -f ./id_dsa
并追加到自己authorized_keys
cat id_dsa.pub >> authorized_keys
用ssh localhost验证看是否需要密码,别忘了exit
将node05 的公钥分发到node06
scp id_dsa.pub node06:`pwd`/node05.pub
在node06的.ssh目录下,追加node05.pub
cat node05.pub >> authorized_keys
在node05上ssh node06,看是否免密钥
————————————————————
————————————————————
2、 node06上免密钥登录node05:
在node06的.ssh目录下生成密钥
ssh-keygen -t dsa -P '' -f ./id_dsa
并追加到自己authorized_keys
cat id_dsa.pub >> authorized_keys
用ssh localhost验证看是否需要密码,别忘了exit
将node06 的公钥分发到node05
scp id_dsa.pub node05:`pwd`/node06.pub
在node05的.ssh目录下,追加node06.pub
cat node06.pub >> authorized_keys
在node06上ssh node05,看是否免密钥
3.12.6启动集群并查看进程
1.启动zookeeper,全部会话
zkServer.sh start
2.在node03上启动hdfs,大致情况如下图所示
start-dfs.sh
3.在node03上启动yarn,大致情况如下图所示
start-yarn.sh

4.在node05、06上分别启动resourcemanager,
yarn-daemon.sh start resourcemanager
5.全部会话jps,看进程全不全(每台机子的进程大概如下)
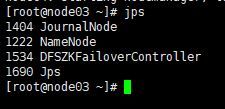
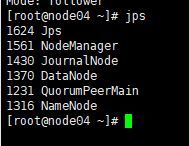
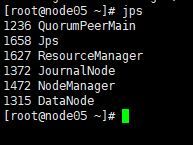
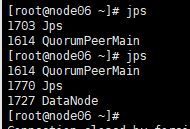
3.12.7浏览器访问node05:8088
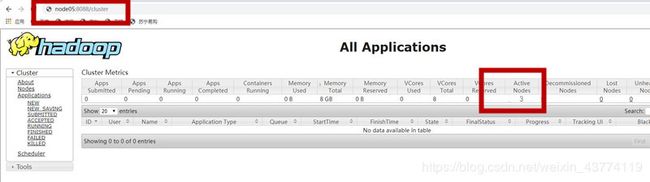
在浏览器访问node05:8088,查看resourcemanager管理的内容。
在ActiveNodes里显示的数值应该为3.(刚打开网页时,可能显示的是1,稍等一会再刷新网页看看)
3.13跑一个wordcount试试
1.进入目录
cd /opt/smy/hadoop-2.6.5/share/hadoop/mapreduce
2.在hdfs里建立输入目录和输出目录
hdfs dfs -mkdir -p /data/in
hdfs dfs -mkdir -p /data/out
3.将要统计数据的500miles.txt文件上传到输入目录并查看
hdfs dfs -put ~/500miles.txt /data/in
hdfs dfs -ls /data/in
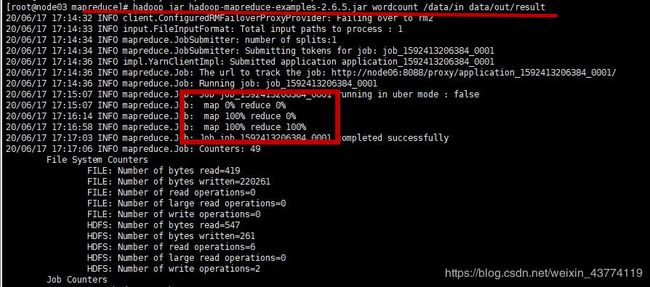
4.运行wordcount(注意:此时的/data/out必须是空目录)
hadoop jar hadoop-mapreduce-examples-2.6.5.jar wordcount /data/in /data/out/result
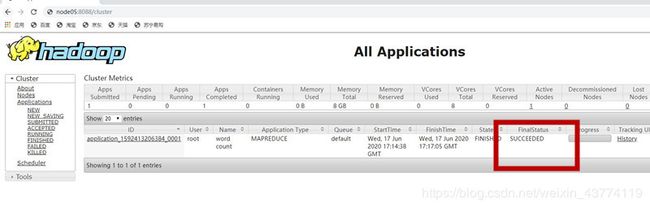
5.查看运行结果
该运行结果应该与"2.8Hadoop伪分布式下运行wordcount"里的运行结果相似
hdfs dfs -ls /data/out/result
hdfs dfs -cat /data/out/result/part-r-00000
3.14关闭集群
node03: stop-dfs.sh
node03: stop-yarn.sh (停止nodemanager)
node05,node06: yarn-daemon.sh stop resourcemanager
Node04、05、06:zkServer.sh stop
恭喜你,你已经是黄金了!!接下来让我们在Windows里配置hadoop环境吧
第四章 在windows下配置hadoop环境
4.1准备hadoop-usr压缩包
把事先准备好的hadoop-usr压缩包解压后的这三个文件夹放到一个usr文件夹里,把usr存放到一个你可以记得的磁盘中。
4.2配置环境变量
1.“此电脑”右键—属性—高级系统设置—环境变量
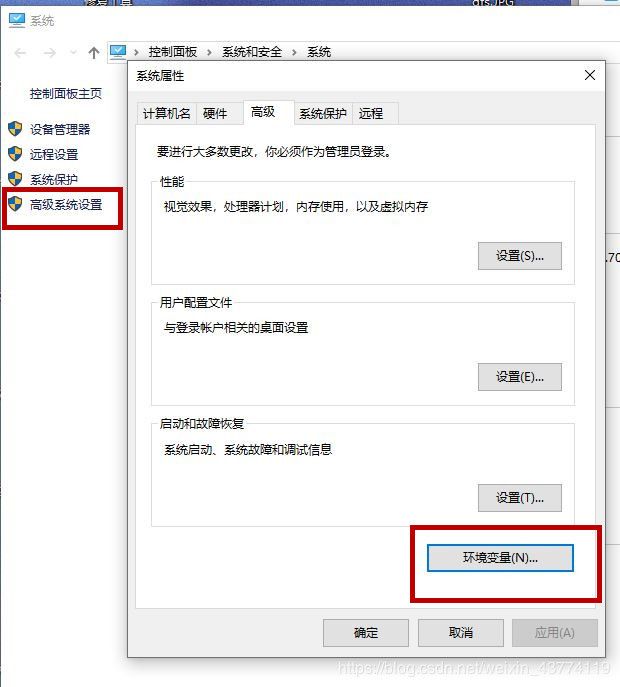
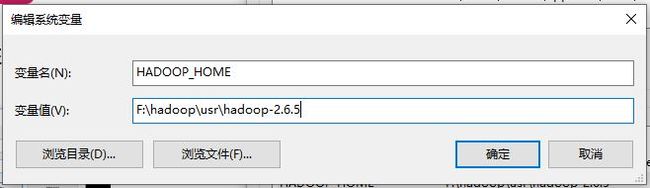
2.更改环境变量,增加HADOOP_HOME
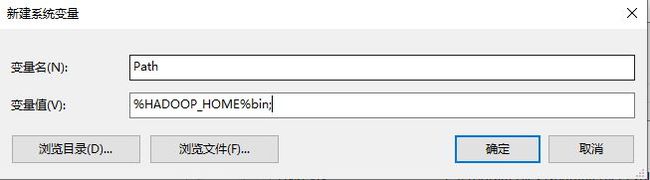
3.给path后追加HADOOP_HOME的bin目录,注意:Windows里path的路径分隔符是分号;,而不是冒号:
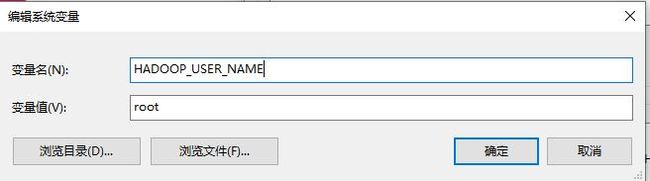
4.再新建一个变量HADOOP_USER_NAME
4.3拷贝hadoop.dll
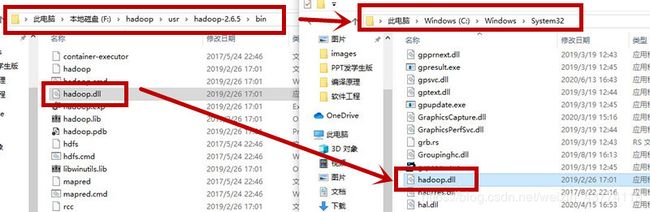
把usr\hadoop-2.6.5\bin中的hadoop.dll拷贝到C:\Windows\System32路径
4.4安装ecipse-mars
此版本的eclipse带插件,可以可视化的看到hadoop的一些东西,比较方便
如果eclipse界面下方没有小象图标,操作如下图。
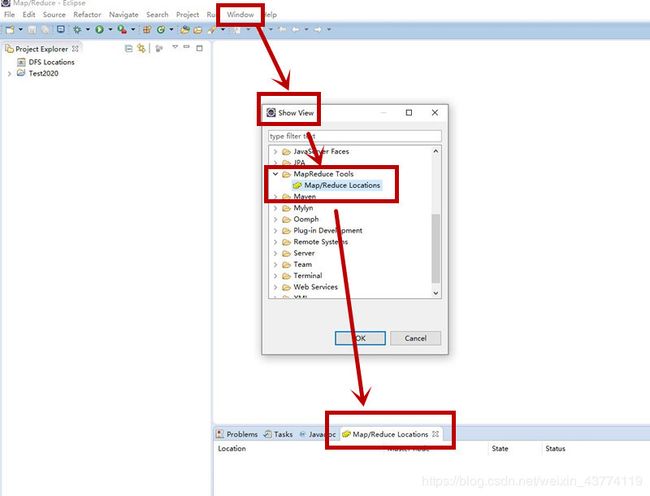
4.5在eclipse里填写hadoop相关信息
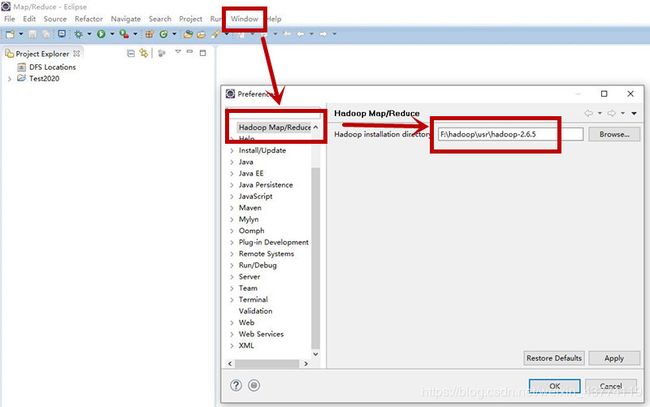
Window—preferecens—Data Management—Hadoop Map/Reduce
将“4.1usr”中的hadoop-2.6.5路径填写到下图位置中。
4.6新建hadoop localtion
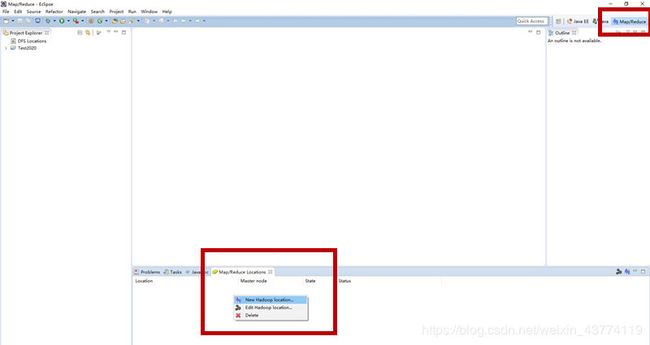
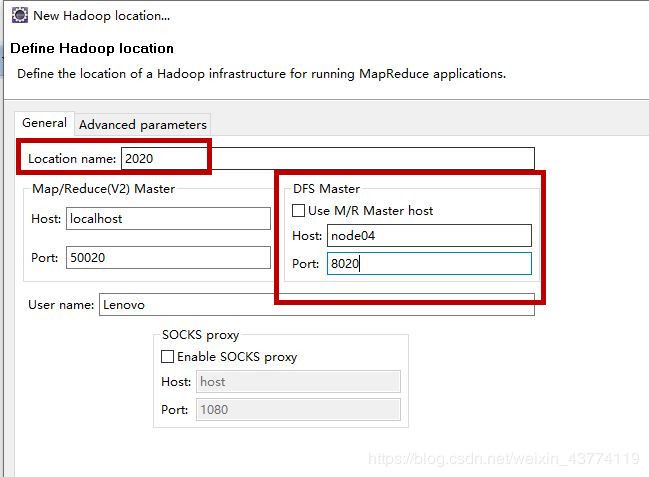
1.在小象 Map/Reduce Locations中,右键—创建New Hadoop Location
下图中的Hosts的值填写的是在浏览器运行中显示为active的node。(在“3.12用浏览器访问node03:50070和node04:50070”这一小节中,显示了我的active是node04)
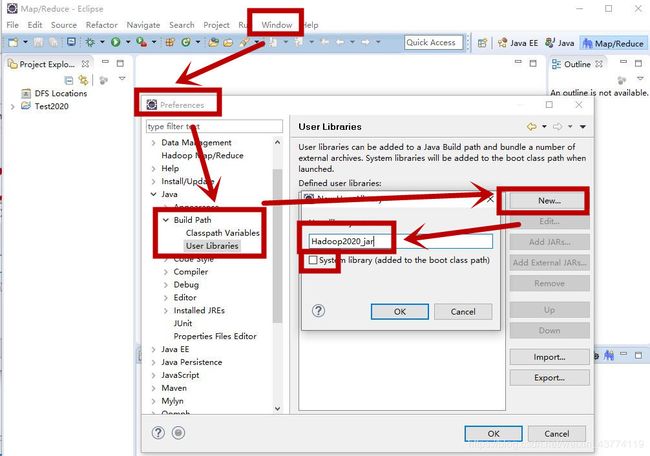
4.7在eclipse里导入hadoop-jar包库
1.第一步,先建立一个hadoop-jar包库
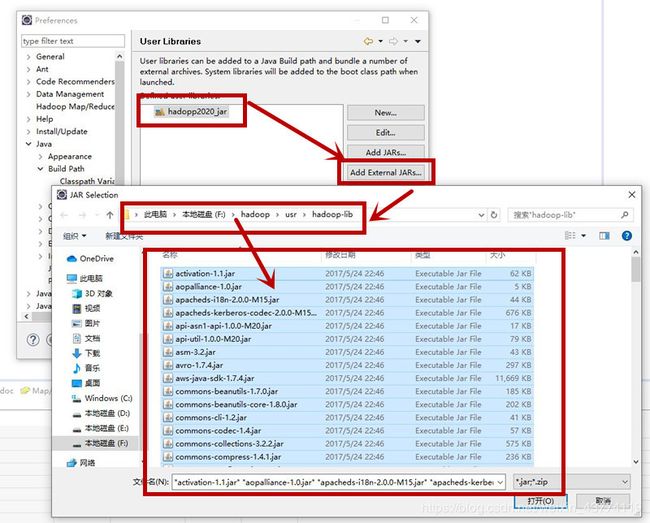
2.第二步,把jar包导入刚建的包库
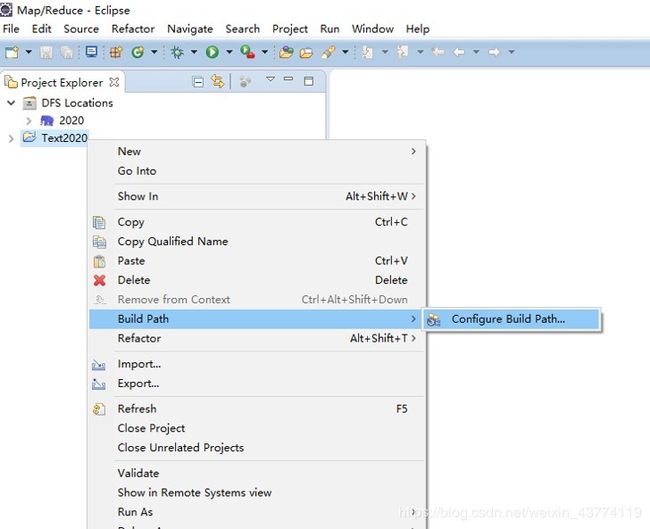
4.8把包库引入到project里
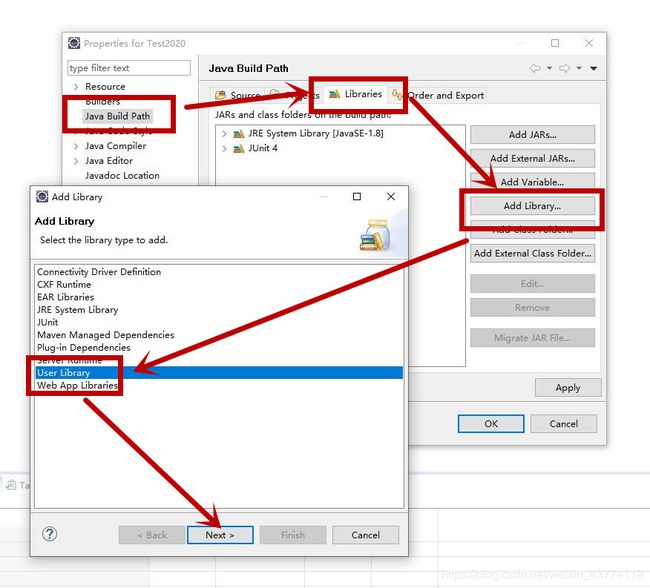
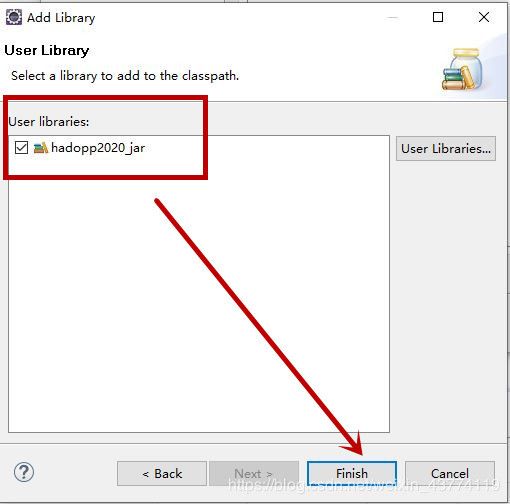
1、选择一个project,右键—Build Path—Configure Build Path…
2、选择包,并导入,操作步骤如下两张图。
4.9把JUnit包库引入到project里
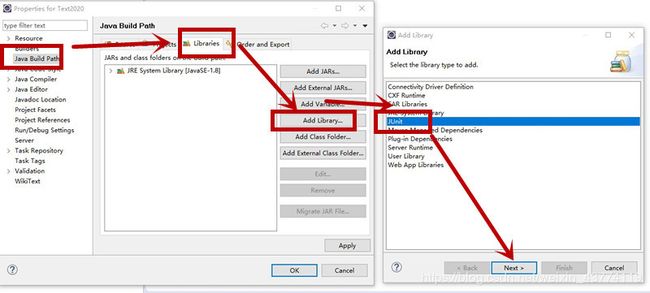
1、选择一个project,右键—Build Path—Configure Build Path…
2、操作下图的步骤。
4.10把.xml文件放到project的src目录。
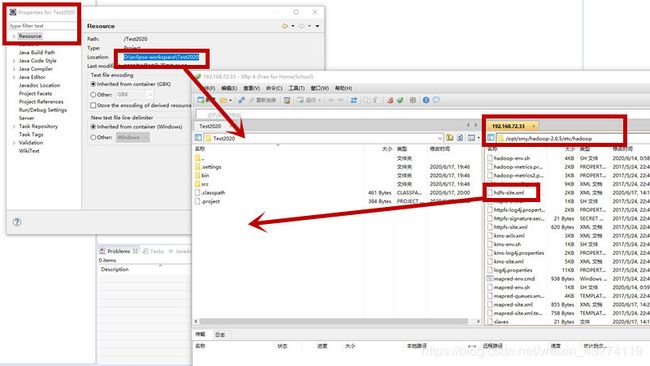
1、选择一个project,右键—Build Path—Configure Build Path…
2、在Xshell里利用xftp把hdfs-site.xml,core-site.xml等几个xml放到project的src目录。
3、操作步骤如下图。
第五章 总结遇到的问题和解决方法
第一个遇到的问题参考链接如下。
VMware Workstation 的提醒:此主机支持 Intel VT-x,但 Intel VT-x 处于禁用状态
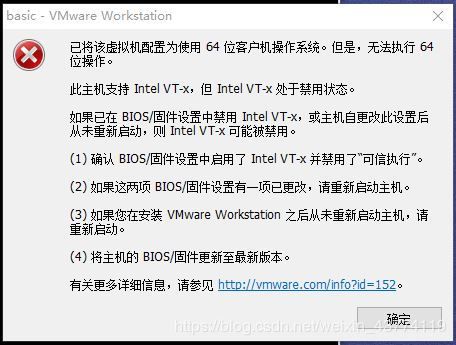
第二个问题是物理内存不足,我找了几个网上的办法,都不能解决我的问题(大概是因为我的电脑内存本就小吧)
最后我是直接按照它告诉我的需要将虚拟机内存设置为多大进行修改,这个内存虽然减少了,但还是够跑完整个作业的。(我觉得这个办法对于小白和不太需要内存的,是最简单快速的。跑了几天虚拟机后我提升了一下这台虚拟机的内存,发现没有提示内存不足,我也不知道咋回事)
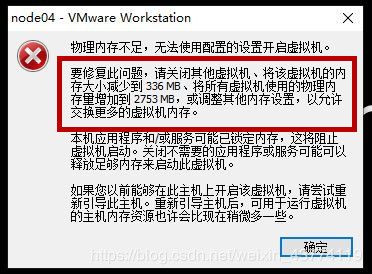
第三个问题是因为格式化多了出问题,用了某位同学告诉的方法就解决了。
cd到有hadoop-root/dfs/data/current/的这个目录下修改VERSION
vi VERSION
要保证node02,node03,node04的VERSION文件中的clusterID一样
第四个问题是同步另一台NameNode时,jps没有namenode
用了下面的两个语句,就可以了。
hdfs namenode –bootstrapStandby
hadoop-daemon.sh start namenode
——————————————————————————
虽然说我的虚拟机到达了黄金阶段,但我对它的了解还是青铜,哈哈哈哈(不要脸的笑一下)
好了,
我的第一次虚拟机之旅到这里就结束了,期待下一次的旅行!