又双叒叕来更新啦!Hadoop——HDFS篇
文章目录
- HDFS(存储)
- 概述
- HDFS的Shell操作
- 常用命令实操
- HDFS客户端操作
- 环境准备
- HDFS的API操作
- HDFS的I/O流操作
- HDFS数据流
- 写数据的过程
- 网络拓扑——节点距离计算
- 机架感知
- 读数据的过程
- NN和2NN
- 工作机制
- Edits和FSimage
- CheckPoint触发条件设置设置
- NN故障处理
- 集群安全模式
- 安全模式相关常用命令
- NameNode多目录配置
- DataNode
- DataNode工作机制
- 数据的完整性
- DataNode掉线时限参数配置
- 服役新数据节点
- 退役旧数据节点
- 添加白名单
- 黑名单退役
- DataNode多目录配置
- HDFS 2.X 新特性
- 集群间的数据拷贝
- 小文件存档
- 回收站
- 快照管理
- Hadoop HA (高可用)
HDFS(存储)
概述
HDFS背景
大数据的背景下,单台服务器的操作系统无法管理所有的海量数据,我们就需要将数据分开放在多台主机的磁盘中,但是这样不便于管理和维护,我们迫切需要一种系统能够同时管理多台机器上的文集,分布式文件管理系统随之诞生,HDFS就是其中之一。
HDFS定义
HDFS(Hadoop Distributed File System),是一个文件系统,比如Windows上使用的NTFS,也是一种文件系统。用于存储文件,通过目录树来定位文件;其次他是分布式的,由很多服务器联合起来实现其功能,集群中的服务器有各自的角色。
HDFS的适用/不适用场景
一次性写入,不支持修改。
HDFS特点:
- 高容错性、可构建在廉价机器上
- 适合批处理
- 适合大数据处理
- 流式文件访问
HDFS局限:
- 不支持低延迟访问
- 不适合小文件存储
- 不支持并发写入
- 不支持修改
HDFS优点
-
高容错性
具体实现:
数据自动保存多个(默认三个)副本,以此提高容错性。
且当某一个副本丢失,他会自动恢复,以保证副本数量
-
适合处理大数据
- 可以处理的GB、TB、PB规模的数据
- 能够处理百万规模以上的文件
-
可以构建在廉价机器上
通过副本提高可靠性
HDFS缺点
- 不适合低延时的数据访问
- 无法高效对大量的小文件进行存储
- 因为不管是存大文件存储小文件,都会占用相同的NameNode大量的内存来存储目录和块信息。相比较下存储大文件空间利用率更高
- 小文件的存储寻址时间会超过读取时间
- 不支持并发写入、文件随机修改
- 不允许多个线程同时写入
- 近支持数据append,不支持修改
HDFS架构
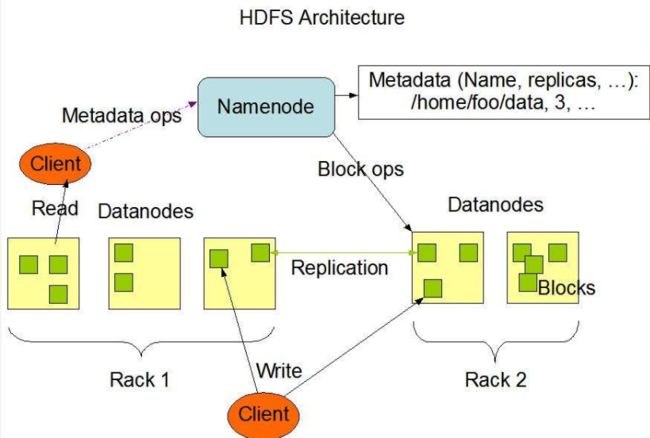
NameNode:Master,一个主管、管理者身份
- 管理HDFS命名空间
- 配置副本策略
- 管理数据块(Blocks)映射信息
- 处理客户端读写请求
DataNode:Slave,一个执行者身份,由NameNode下达命令,DataNoda执行
- 存储实际的数据块
- 执行数据的读/写操作
Client
- 文件切分。文件数据写入的适合,先将文件切分成一个个Block,然后进行上传写入。
- 和NameNode交互,获取文件位置信息
- 和DataNode交互,读取或写入数据
- 提供一些命令管理HDFS,例如NameNode的格式化
- 也可以使用命令来访问HDFS,例如对HDFS的增删改查
Secondary NameNode:并非NameNode的热备份,当NameNode故障,它并不能立即代替NameNode提供服务
- 辅助NameNode,为其分担工作量,例如定期合并Fsimage和Edits,并推送给NameNode
- 在紧急情况下,可以辅助NameNode进行恢复。
HDFS文件块大小
HDFS中的文件在物理空间中是以块(Block)形式存储,默认的块大小是128MB,可以在hdfs-default.xml中查看dfs.blocksize,旧版本(1.x)中是64MB
![]()
为什么128MB?由什么决定?
假设对Block的寻址时间是10ms,那么按照寻址时间是传输时间(数据写入时间)是1%为最佳状态,传输的时间就是1s,我们现在的机械硬盘读写速度一般稳定在80~120MB/s的范围内,那么也就说当我们寻找到Block的地址后,传输一秒的数据大小最接近块大小是最合适的,也就100MB左右,当然以上数据都是粗略数据,并没有那么精确。
所以说块的大小,与硬盘的读写速度相关联
为什么块的大小不能太小,也不能太大?
块大小,存储/读取一个文件需要找到多个块,程序就要不断寻址块进行存储/读取。
块太大,磁盘传输数据耗时长。
HDFS的Shell操作
基本命令:hdfs dfs ...或者Hadoop fs
常用命令实操
-
启动集群
start-dfs.sh start-yarn.sh -
命令帮助 -help
hadoop -help command -
基本命令
-ls:显示目录信息-mkdir: 创建目录-moveFromLocal: 从本地剪切粘贴-copyFromLocal: 从本地复制粘贴-appendToFile: 追加一个文件到已存在文件的末尾-cat: 查看文件内容-chgrp-chmod-chown: 修改所有组、所有者、文件权限-copyToLocal: 从HDFS拷贝到本地-cp: HDFS中文件拷贝复制-mv: HDFS中文件移动-get: 等同于copyToLocal-getmerge: 合并下载多个文件-put: 等同于copyFromLocal-tail: 显示一个文件的末尾,-f动态监视一个文件-rm: 删除文件、目录-du: 统计文件大小- -s 仅显示总计,只列出最后加总的值。
- -h 以K,M,G为单位,提高信息的可读性。
-setrep: 设置HDFS中文件的副本数量
HDFS客户端操作
环境准备
windows Hadoop客户端环境搭建
- 将Hadoop解压缩到环境文件夹中
- 添加环境变量HADOOP_HOME,变量值为Hadoop的根目录
- PATH中添加%HADOOP_HOME%\bin
- 重启,使用
hadoop version测试验证
项目搭建
Maven构建项目,并导入依赖,注意Hadoop组件的版本要和环境的版本一致
pom.xml
<dependencies>
<dependency>
<groupId>junitgroupId>
<artifactId>junitartifactId>
<version>4.13version>
dependency>
<dependency>
<groupId>org.apache.logging.log4jgroupId>
<artifactId>log4j-coreartifactId>
<version>2.12.1version>
dependency>
<dependency>
<groupId>org.apache.hadoopgroupId>
<artifactId>hadoop-commonartifactId>
<version>2.7.7version>
dependency>
<dependency>
<groupId>org.apache.hadoopgroupId>
<artifactId>hadoop-clientartifactId>
<version>2.7.7version>
dependency>
<dependency>
<groupId>org.apache.hadoopgroupId>
<artifactId>hadoop-hdfsartifactId>
<version>2.7.7version>
dependency>
dependencies>
编写Log4j的配置文件:log4j.properties
log4j.rootLogger = INFO ,stdout
### 输出到控制台 ###
log4j.appender.stdout = org.apache.log4j.ConsoleAppender
log4j.appender.stdout.Target = System.out
log4j.appender.stdout.layout = org.apache.log4j.PatternLayout
log4j.appender.stdout.layout.ConversionPattern = %d %p [%c]- %m%n
### 输出到日志文件 ###
log4j.appender.file = org.apache.log4j.FileAppender
log4j.appender.file.File = target/spring.log
log4j.appender.file.layout = org.apache.log4j.PatternLayout
log4j.appender.file.layout.ConversionPattern = %d %p [%c]- %m%n
Java代码操作HDFS
public class HDFSClient {
public static void main(String[] args) throws IOException {
// 配置信息
Configuration conf = new Configuration();
// 配置NameNode的地址 host文件中配置了hadoop102的映射地址是192.168.52.202
conf.set("fs.defaultFs", "hdfs://hadoop102:9000");
// 文件系统对象
FileSystem fs = FileSystem.get(conf);
// 创建一个目录
fs.mkdirs(new Path("/test/hello"));
// 关闭资源
fs.close();
System.out.println("over");
}
}
代码解释:
- 第一步是我们要获取一个FileSystem对象(org.apache.hadoop.fs包下的!!)
- 获取这个兑用需要一个Configuration对象(也是Hadoop包下的!),也就是配置信息。
- 使用FileSystem对象进行相应的操作
- 关闭文件系统资源
这样就可以了吗?!NoNoNoNo!
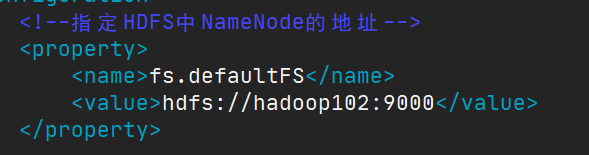
既然是要操作远程的文件系统,就需要指明NameNode的地址,记得我们在
core-site.xml中配置的第一条配置项fs.defaultFS就是指明NameNode的地址的。所以为我们创建的Configuration对象,set这条信息。启动!
此时运行还是会报错:

这个错误可以忽略,因为我们操作的远程Linux上的HDFS,真正要解决的问题是这个:
![]()
操作控制异常,由于我们使用Windows去连接使用Linux上的HDFS适合,用户名并不一致,所以在我们要在运行参数中设置一个参数-DHADOOP_USER_NAME=sakura
然后重新运行,再刷新HDFS的网页,就可以看到新创建的目录啦!
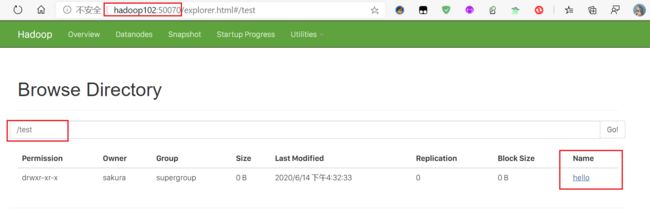
这样的做法显得有点麻烦,能不能用代码一步搞定呢?!答案是:可以!
使用FileSystem.get(URI uri, Configuration conf, String user),就可以将NameNode、UserName一步搞定!
public class HDFSClient {
public static void main(String[] args) throws IOException, URISyntaxException, InterruptedException {
// 配置信息
Configuration conf = new Configuration();
// 文件系统对象
FileSystem fs = FileSystem.get(new URI("hdfs://hadoop102:9000"), conf, "sakura");
// 创建一个目录
fs.delete(new Path("/test/hello"));
// 关闭资源
fs.close();
System.out.println("over");
}
}
HDFS的API操作
文件上传
copyFromLocal
public void testCFL() throws URISyntaxException, IOException, InterruptedException {
Configuration conf = new Configuration();
FileSystem fs = FileSystem.get(new URI("hdfs://hadoop102:9000"), conf, "sakura");
fs.copyFromLocalFile(new Path("src\\main\\resources\\hello.txt"), new Path("/"));
fs.close();
}
参数优先级问题
关于Hadoop的参数,现在可以又三个地方进行设置
- 集群上Hadoop的etc/hadoop/目录中的配置文件中配置(会覆盖官方的默认配置)
- 项目中resource目录中创建的xml配置文件中配置
- 代码中Configuration对象使用set方法设置
优先级递增,代码设置 > 项目中配置文件 > 服务器配置文件 > 官方默认配置
文件下载
copyToLocalFile
@Test
public void testCTL() throws URISyntaxException, IOException, InterruptedException {
Configuration conf = new Configuration();
FileSystem fs = FileSystem.get(new URI("hdfs://hadoop102:9000"), conf, "sakura");
fs.copyToLocalFile( new Path("/hello.txt"), new Path("F:/hello.txt"));
fs.close();
}
这样使用copyToLocalFile会报错,而应该使用重载的方法
源码中可以看到这个moveToLocalFile和copyToLocalFile都是通过对这个方法重载得到的:
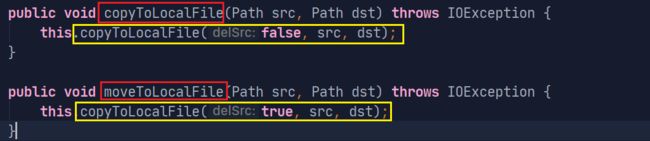
我们继续向上锁定,找到最终目标:
copyToLocalFile(boolean delSrc, Path src, Path dst, boolean useRawLocalFileSystem)
四个参数:
- delSrc(boolean):是否删除源文件
- src: 源文件地址
- dst: 拷贝的目的地址
- userRawLocalFileSystem(boolean): 下载的文件是否使用本地原生文件系统
经过测试检验,第一个参数根据是使用剪切还是复制进行自由设置,但是最后一个参数貌似只能设置true,如果设置为false,在下载时候会连带下载一个.crc校验文件,但是测试中设置false会报错,目前没有找到解决办法。
所以正确姿势:
@Test
public void testCTL() throws URISyntaxException, IOException, InterruptedException {
Configuration conf = new Configuration();
FileSystem fs = FileSystem.get(new URI("hdfs://hadoop102:9000"), conf, "sakura");
fs.copyToLocalFile( false,new Path("/hello.txt"), new Path("F:/hello.txt"),true);
fs.close();
}
HDFS文件删除
delete
public void testDel() throws URISyntaxException, IOException, InterruptedException {
Configuration conf = new Configuration();
FileSystem fs = FileSystem.get(new URI("hdfs://hadoop102:9000"), conf, "sakura");
fs.delete(new Path("/test"), true);
fs.close();
}
delete(Path f, boolean recursive)
第二个参数recursive,决定删除是否使用递归删除,作用等同于rm中的-r选项。
文件重命名
rename()
Linux中文件重命名是在同一目录中使用mv实现,这里也是一样:
public void testRename() throws URISyntaxException, IOException, InterruptedException {
Configuration conf = new Configuration();
FileSystem fs = FileSystem.get(new URI("hdfs://hadoop102:9000"), conf, "sakura");
fs.rename(new Path("/hello.txt"), new Path("/test.txt"));
fs.close();
}
文件信息
fileStatus(名称、权限、长度、块信息、所有者等)查看
public void fileInfo() throws URISyntaxException, IOException, InterruptedException {
Configuration conf = new Configuration();
FileSystem fs = FileSystem.get(new URI("hdfs://hadoop102:9000"), conf, "sakura");
// 获取文件迭代器
RemoteIterator<LocatedFileStatus> listFiles = fs.listFiles(new Path("/"), true);
// 遍历
while (listFiles.hasNext()) {
// 返回文件的状态信息
LocatedFileStatus fileStatus = listFiles.next();
System.out.println("文件路径:" + fileStatus.getPath().getName());
System.out.println("文件大小:" + fileStatus.getLen());
System.out.println("权限:" + fileStatus.getPermission());
System.out.println("文件块大小:" + fileStatus.getBlockSize());
System.out.println("所有者:" + fileStatus.getOwner());
// 获取文件块的位置
System.out.println("文件副本:");
BlockLocation[] blockLocations = fileStatus.getBlockLocations();
for (BlockLocation blockLocation : blockLocations) {
// 获取块所在的主机号
String[] hosts = blockLocation.getHosts();
for (String host : hosts) {
System.out.println(host);
}
}
}
fs.close();
}
输出:
文件路径:test.txt
文件大小:17
权限:rw-r--r--
文件块大小:134217728
所有者:sakura
文件副本:
hadoop102
hadoop103
判断是文件还是目录
isFIle和isDirectory
public void fileOrDir() throws URISyntaxException, IOException, InterruptedException {
Configuration conf = new Configuration();
FileSystem fs = FileSystem.get(new URI("hdfs://hadoop102:9000"), conf,"sakura");
FileStatus[] fileStatuses = fs.listStatus(new Path("/"));
for (FileStatus fileStatus : fileStatuses) {
if (fileStatus.isFile()) {
System.out.println("f:" + fileStatus.getPath().getName());
} else {
System.out.println("d:" + fileStatus.getPath().getName());
}
}
fs.close();
}
HDFS的I/O流操作
文件上传
public void fileUpload() throws URISyntaxException, IOException, InterruptedException {
// 获取fs对象
Configuration conf = new Configuration();
FileSystem fs = FileSystem.get(new URI("hdfs://hadoop102:9000"), conf, "sakura");
// 获取本地文件输入流,用于将文件读取到程序中
FileInputStream fis = new FileInputStream(new File("f:\\banner.txt"));
// 获取文件的输出流,用于讲文件输出到HDFS中
FSDataOutputStream fsDataOutputStream = fs.create(new Path("/banner.txt"));
// 流的对接拷贝
IOUtils.copyBytes(fis, fsDataOutputStream, conf);
//资源释放
IOUtils.closeStream(fsDataOutputStream);
IOUtils.closeStream(fis);
fs.close();
}
步骤流程:
- 获取普通的文件输入流,用将本地的文件读取到程序中
- 使用FileSystem获取HDFS的文件输出流,用于将内容输出到HDFS中
- 使用IOUtils(hadoop.io),进行流的对接拷贝
- 按顺序释放资源(先开后关)
文件下载
public void fileDownload() throws URISyntaxException, IOException, InterruptedException {
// 获取fs对象
Configuration conf = new Configuration();
FileSystem fs = FileSystem.get(new URI("hdfs://hadoop102:9000"), conf, "sakura");
// 获取输入流
FSDataInputStream fis = fs.open(new Path("/test.txt"));
// 获取输出流
FileOutputStream fos = new FileOutputStream(new File("f:\\test.txt"));
// 流的对接拷贝
IOUtils.copyBytes(fis, fos, conf);
// 关闭资源
IOUtils.closeStream(fos);
IOUtils.closeStream(fis);
fs.close();
}
定位读取文件
当文件分块之后,只想下载某一个块,如何解决?
public void fileSeek() throws URISyntaxException, IOException, InterruptedException {
// 获取fs对象
Configuration conf = new Configuration();
FileSystem fs = FileSystem.get(new URI("hdfs://hadoop102:9000"), conf, "sakura");
FSDataInputStream fis = fs.open(new Path("/hadoop-2.7.7.tar.gz"));
FileOutputStream fos = new FileOutputStream(new File("f:\\hadoop-2.7.7.tar.gz.part0"));
// 创建一个1M的缓存数组
byte[] buf = new byte[1024];
// 循环拷贝128次
for (int i = 0; i < 1024 * 128; i++) {
fis.read(buf);
fos.write(buf);
}
// 资源关闭
IOUtils.closeStream(fos);
IOUtils.closeStream(fis);
fs.close();
}
以上这种方式只适合下载第一块,如果要指定开始读取的位置需要用到FSDataInputStream中的seek()方法来指定起始位置
public void fileSeek02() throws URISyntaxException, IOException, InterruptedException {
// 获取fs对象
Configuration conf = new Configuration();
FileSystem fs = FileSystem.get(new URI("hdfs://hadoop102:9000"), conf, "sakura");
FSDataInputStream fis = fs.open(new Path("/hadoop-2.7.7.tar.gz"));
// 指定从文件的128M的位置开始
fis.seek(1024 * 1024 * 128);
FileOutputStream fos = new FileOutputStream(new File("f:\\hadoop-2.7.7.tar.gz.part1"));
IOUtils.copyBytes(fis, fos, conf);
IOUtils.closeStream(fos);
IOUtils.closeStream(fis);
fs.close();
}
这样以后日志产生新的数据,我们就只需要下载最新的部分即可,不用下载完整的文件了。
HDFS数据流
写数据的过程
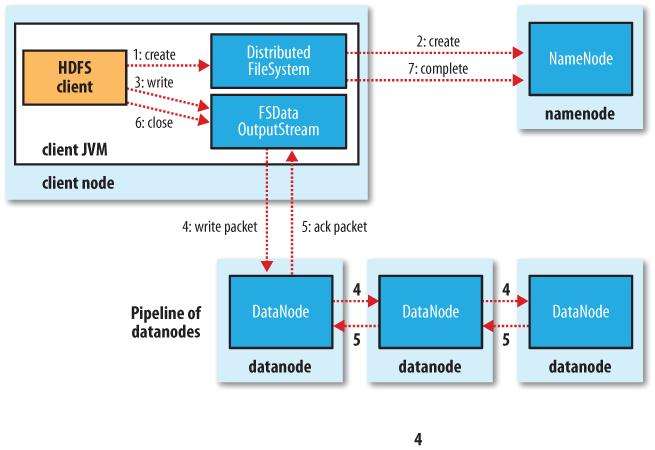
首先客户端要完成对数据的分片
- 创建一个DistributeFileSystem
- 在NameNode中创建元数据,并向NameNode请求存储文件,NameNode检查文件是否存在并给出应答,告诉客户端在哪些节点进行存储
- 客户端创建一个FSDataOutputStream用于传输数据,并与对于的DataNode建立连接。
- 将数据以packet为单位依次写入每个节点的内存(直接写入磁盘增加IO次数,效率较低),最后将内存中的数据落盘到磁盘中。
- 数据传输完成等待的DataNode发出应答。
- 关闭FSDataOutputStream
- 通知NameNode,数据传输完毕,断开连接。
网络拓扑——节点距离计算
在上面数据写入阶段,NameNode会通过计算客户端与节点的距离,给出优先写入数据的DataNode。
节点间距离:
两个节点到达它们共同祖先的距离总和
机架感知
推荐阅读:https://www.jianshu.com/p/16b854b842c3
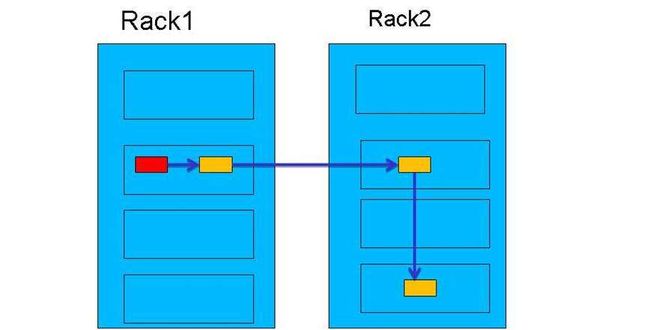
什么是机架感知?
通俗易懂的说法就是:让Hadoop知道每台服务器处于网络中的那个位置
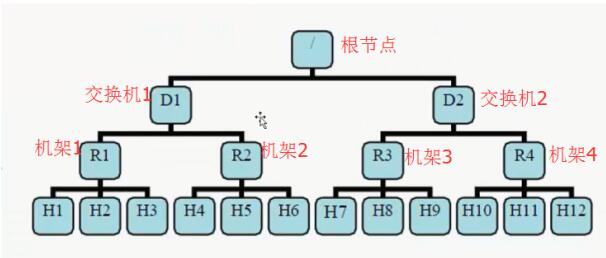
图中R1~R4就是四个机架(Rack),每个机架下面管理若干台主机H1,H2…。
默认情况
- 默认情况下HDFS没有开启机架感知,所有的机器默认都是在同一个机架下,名为: /default-rack
- HDFS不能够自动判断集群中各个datanode的网络拓扑情况,HDFS写入block是随机的
为什么开启机架感知?
- 开启机架感知,NN可以知道DN所处的网络位置
- 根据网络拓扑图可以计算出rackid,通过rackid信息可以计算出任意两台DN之间的距离
- 在HDFS写入block时,会根据距离,调整副本放置策略
- 写入策略会将副本写入到不同的机架上,防止某一机架挂掉,副本丢失的情况。同时可以降低在读取时候的网络I/O。但是会增加写操作的成本。
默认的副本放置策略
默认的副本数量是3,由于未开启机架感知,所以block副本的存放,完全是随机选择。
开启机架感知后,副本放置策略
- 当上传主机不是机架上的服务器时,随机挑选机架上的一个DN,进行数据写入,后面我们称其为DN1,若上传的主机就是一个DN,那么则在其本地创建文件,其本身就是DN1。
- 第二个副本是在与DN1同机架的DN中随机选择并存放副本,我们称这个DN为DN2。
- 第三个副本存放在与DN1、DN2不同机架的其他一个随机的DN上。
最终目的就是尽量将副本存放到不同机架上,以保证可靠性。
读数据的过程
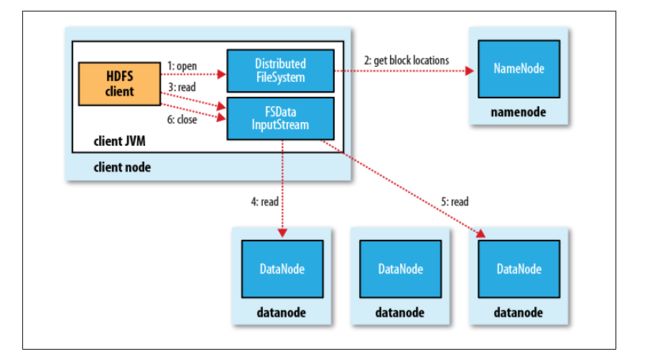
具体步骤分解:
- 获取一个DistributeFileSystem,用于与NameNode交互
- 向NameNode请求读取数据,获取对应数据的元数据,从元数据中获取文件块所在的主机地址
- 获取FSDataInputStream,用于从DataNode上读取数据
- 到指定的DataNode上读取数据,数据的读取过程是串行的!而非并行读取
- 等待上一次数据读取完毕,开始新一次的数据读取操作。
- 数据读取完毕,关闭流资源。
NN和2NN
工作机制
NameNode的元数据存在在哪?
内存中?若元数据都放到内存中,一旦机器断电,元数据全部丢失,集群就无法继续工作了。❌
磁盘中?客户端频繁请求读写数据,过多的IO操作使得工作效率低下。❌
综合以上两点,集群工作时,将元数据放在内存中用户处理用户的请求,同时备份元数据到磁盘中,磁盘中的元数据备份我们称为FSimage(镜像),但是仅仅这样操作,仍然需要大量的IO操作将内存中的元数据存入磁盘中,或者从磁盘中读取数据到内存中。
于是又引出了EditsLog(编辑日志文件),将内存中对修改后的元数据追加写入到Edits中, 而不是直接同步到磁盘中,这样以来,即时断电内存中的元数据丢失,也可以通过Edist文件和磁盘中的FSimage合并然后恢复元数据。但是问题又显现出来了,不断地文件追加,Edits日志文件的体积会不断变大,逐渐恢复元数据的时间就会增加。
于是我们需要定期将Edits文件和FSimage文件合并,以减小Edit的文件体积,减少元数据恢复的时间,那这份工作交给谁来做呢?NameNode吗?它太忙了而且它随时有挂掉的可能性,于是SecondaryNameNode就可以发挥作用了,2NN的工作中就包含了定期合并Edits文件FSimage文件并推送给NN。
示意图:
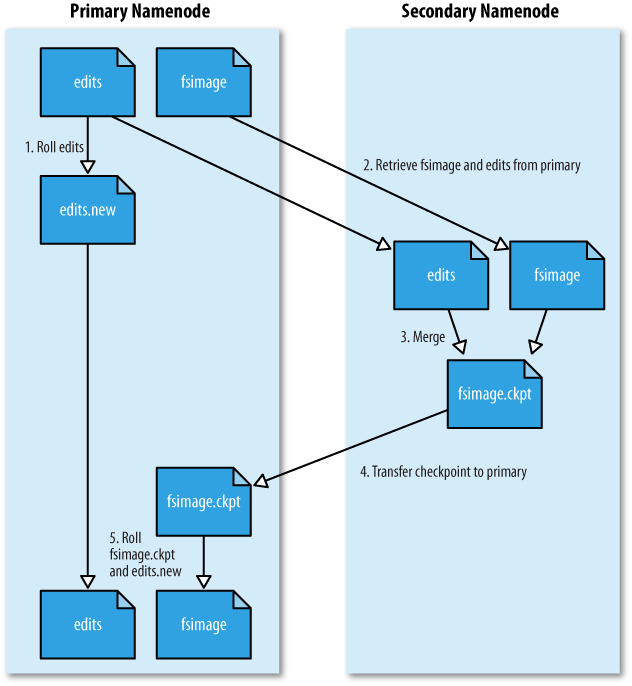
-
客户端的请求不会首先接触到内存,而是先更新Edits,正在写的Edits会进行滚动更新
-
满足以下任意一个条件,会触发2NN一个检查点(checkpoint)
- 检查点定时结束(3600s,也就是一小时)。
- Edits中数据为饱满状态(100W条数据)
在执行CheckPoint时,2NN会捕获Edits,FSimage文件
-
对两个文件进行合并(Merge),然后产生一个fsimage.ckpt文件
-
将这个文件拷贝到NN中
-
将文件重命名为fsimage替换之前的fsimage
Edits和FSimage
我们一直讨论的这俩文件到底在哪呢?里面是些什么内容呢?来一探究竟
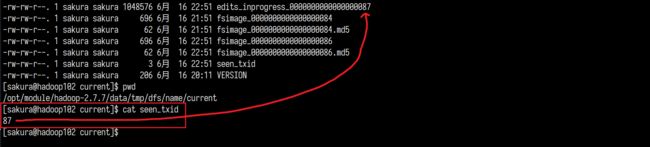
NameNode节点上:

除此以外2NN所在主机上应该也有
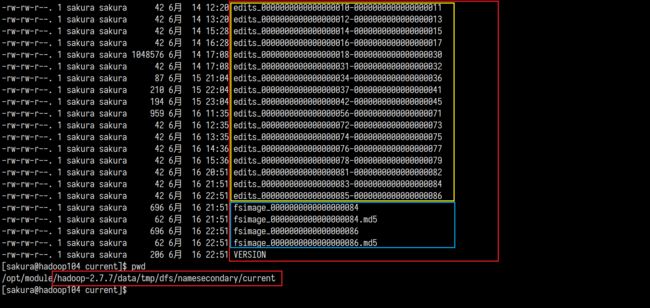
这么多文件,到底哪一个才是最新的呢?
NameNode中可以看到一个与众不同的命名edits_inprogress_000xxxx,其实这个文件就是当前正在用于记录的日志文件!那个不怎么起眼的seen_txid就记录着当前正在使用的edits的文件编号。
那我来看看edits和fsimage文件里面究竟是藏的什么东西:

其实这种情况是打开方式不对,hdfs中有专用的命令用于查看这两种文件:

通过这hdfs oiv和hdfs oev可以将fsimage和edits文件转化为我们能够阅读的格式
它们有一些共同的选项:

- -i: 用于指定要加工的文件,即edits、fsimages文件
- -o: 加工产生文件的输出路径及文件名
- -p: 是指定加工的格式,支持binary、XML、stats,oev默认是XML。oiv是需要用-p选项指定格式的!!
我们生成edits.xml一个试试看:
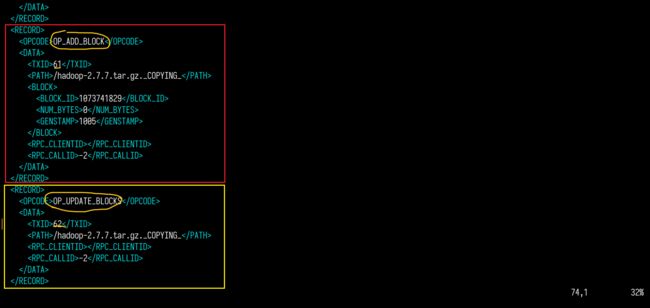
edits生成的xml文件中,以RECORD为单位记录每一次元数据的修改。使用OPCODE指明操作类型。
再来看看fsimage生成出来的文件长什么样:
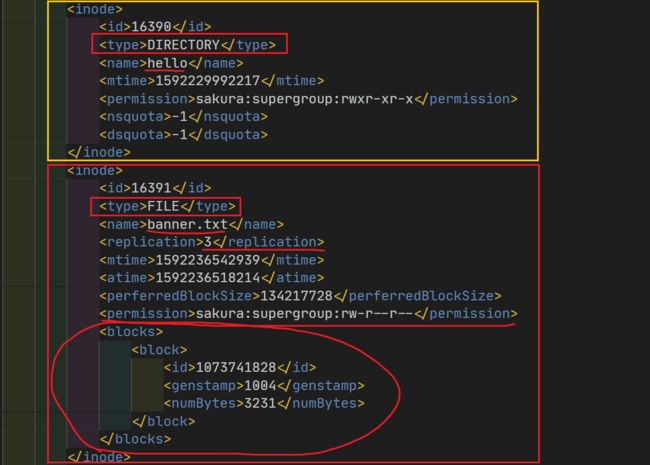
xml中以inode为单位记录着hdfs上每一个文件/目录的信息,包括文件/目录名,操作权限,所有者以及组,副本数量,文件块的信息等。
为什么其中没有存放文件块所在节点的IP呢?
为了避免DataNode挂掉,导致文件块无法正常读取,NameNode不会再文件中静态写明文件块的地址,而是通过DataNode定时地向NameNode汇报文件块信息,以保证NameNode可以感知到各个DataNode的状态。
CheckPoint触发条件设置设置
上面说到CheckPoint的触发条件有两个:
- 距离上一次CheckPoint时间达到了3600秒
- Edits文件中的操作记录(Record)数达到了100W条
这个配置在官方给出的hdfs配置已经写明:
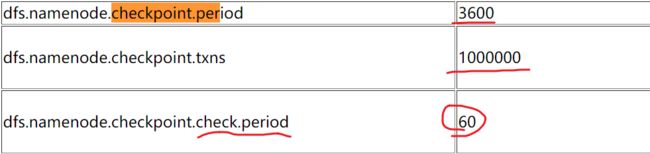
至于这个60呢,就是间隔多久检查一次Edits中的记录数量。默认是60秒。
这三个配置是完全可以自定义修改的。
NN故障处理
方式一:将2NN中的元数据,拷贝一份到NN中进行数据恢复。
因为2NN中的存放元数据与NN中相差无几。
scp -r sakura@hadoop104:/opt/module/hadoop-2.7.7/data/tmp/dfs/namesecondary/* sakura@hadoop102:/opt/module/hadoop-2.7.7/data/tmp/dfs/name
方式二:使用-importCheckpoint选项,启动NameNode的守护线程,将2NN中的数据恢复到NameNode中
-
修改配置文件hdfs-site.xml
<property> <name>dfs.namenode.checkpoint.periodname> <value>120value> property> <property> <name>dfs.naenode.name.dirname> <value>/opt/module/hadoop-2.7.7/data/tmp/dfs/namevalue> property>修改完成后,记得将修改文件进行集群分发
xsync ... -
将2NN的中
namesecondary整个目录拷贝到NN的Name同级目录scp -r sakura@hadoop104:/opt/module/hadoop-2.7.7/data/tmp/dfs/nameseconday sakura@hadoop102:/opt/module/hadoop-2.7.7/data/tmp/dfs并删除NN拷贝的目录中的
in_use.lock文件 -
开启NameNode的守护线程,并使用
-importCheckpoint选项导入检查点。hdfs namenode -importCheckpoint -
等待导入检查完毕,然后再启动NameNode即可恢复。
集群安全模式
什么是安全模式?
NameNode处于安全模式时,对于客户端来说文件系统是只读的!
何时处于安全模式?
当集群启动的时候,==NameNode首先将当前使用的FSimage载入内存,并执行使用中Edits的各项操作,重新建立完整的元数据,一旦元数据恢复完成,就会生成一个新的FSimage,以及一个空的Edits。==此过程中文件系统是不会处理任何写请求的,避免数据恢复过程中写操作会被遗漏,造成数据错误。所以整个过程中NameNode处于安全模式,对于客户端来说这段时间文件系统是只读的。
DataNode启动:==由于所有的文件块的信息并不是由NameNode进行维护,而是各个DataNode以块列表的形式进行维护管理。==集群启动的时候,每个DataNode就会向NameNode上报自己文件块的信息,NameNode接收到以后,会将这些块位置信息保留再内存中!便于文件系统的高效运行。在NameNode没有接收到足够的块信息的时候,就会处于安全模式
安全模式何时退出?
当满足“最小副本条件”的时候,NameNode会在30秒之后退出安全模式。
何为最小副本条件?
当整个文件系统中99.9%(不是100%具有一定的容错性)的文件块均满足最小副本级别(default:dfs.replication.min=1)。说人话就是文件系统中99.9%的文件块都必须至少有1个或以上的副本
特例
一个刚进行格式化的NameNode中是没有任何数据的,所以也就不会进入安全模式!
安全模式相关常用命令
hdfs dfsadmin -safemode get:查看安全模式状态hdfs dfsadmin -safemode enter:进入安全模式hdfs dfsadmin -safemode leave:离开安全模式hdfs dfsadmin -safemode wait:等待安全模式
除了使用命令可以查看安全模式,在hdfs的web页面上也可以进行查看:
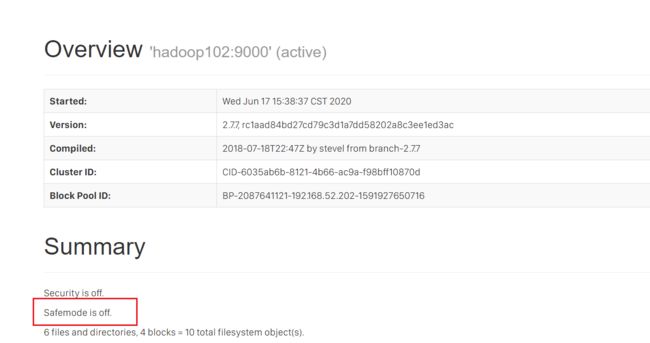

打开安全模式,测试以下上传文件:

拒绝了我们上传文件的操作,一切修改文件系统内容的操作都不允许。
至于这个等待安全模式,可能难以理解
所谓等待安全模式就是,由于安全模式下有些操作无法进行,我们必须等待安全模式结束,才能进行操作。而这条命令就会阻塞式判断安全模式,直到安全模式关闭。
我们用一个脚本来演示:
-
编写一个脚本
#!/bin/bash # 等待安全模式 hdfs dfsadmin -safemode wait # 安全模式关闭,立即执行以下命令 hdfs dfs -rm /test.txt -
开启安全模式
-
执行脚本,会一直处于阻塞状态等待安全模式关闭
-
然后在另一个终端上关闭安全模式
-
然后脚本阻塞结束,立即向下执行:

NameNode多目录配置
多一个备份,多一份保障,提高数据的可靠性。
-
任何修改前,先关闭集群
-
在
hdfs-site.xml中配置dfs.namenode.name.dir<property> <name>dfs.namenode.name.dirname> <value>file:///${hadoop.tmp.dir}/dfs/name1,file:///${hadoop.tmp.dir}/dfs/name2value> property>之前我们在core-site.xml中配置了hadoop.tmp.dir=/opt/module/hadoop-2.7.7/data/tmp,这里直接使用。
-
配置完毕,分发给各个节点
-
删除NameNode和2NN上的 data/ logs/目录准备格式化NameNode
-
格式化NameNode,
hdfs namenode -format
格式化后,我们到NameNode的目录中查看就能发现我们配置的两个目录:
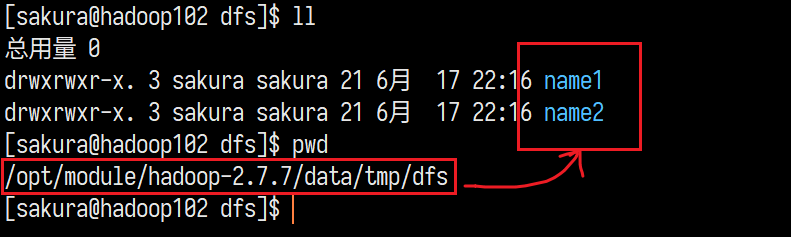
并且两个目录中存放的数据完全相同:
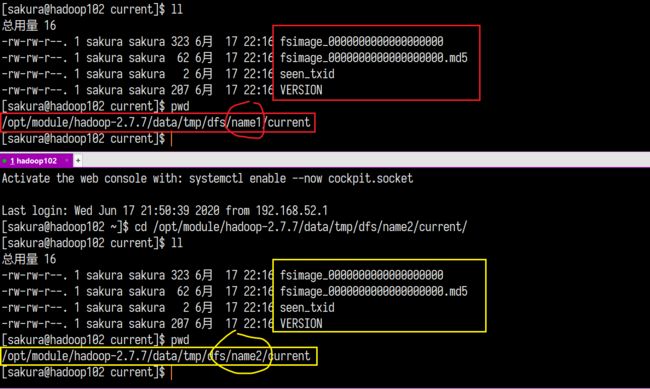
这样等同于我们为NameNode创建一份伪备份,提高了数据可靠性。
DataNode
DataNode工作机制
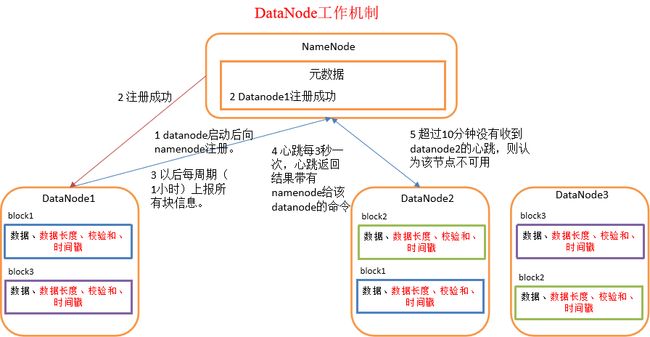
- 集群启动,DataNode向NameNode上报各自的文件块信息,NameNode接收并在内存中保留。
- NameNode应答DataNode
- 之后每间隔一段时间(默认:1小时),重新上报数据信息。
- NameNode接收来自各个DataNode的心跳(每三秒),以确保DataNode的存活状态,NameNode连续30秒没有收到DataNode的心跳,将DataNode标记为过时。(参考默认配置中的
dfs.heartbeat.interval和dfs.namenode.stale.datanode.interval) - 超过10分钟未接收到DataNode的心跳,则认为这个DataNode不可用。
数据的完整性
为了解决传输数据的不可靠问题,在传输数据的时候,不能之传输数据内容,并且要加上一系列的加密和校验的计算,校验数据的方法著名的有:奇偶校验、海明码校验、CRC校验(循环冗余校验)。DataNode就是使用的CRC校验,标志性的就是在一些主机上下载HDFS中文件的时候,会同时下载一个.crc文件。
DataNode掉线时限参数配置
在DataNode 的工作机制中,提到DataNode会持续向NameNode返回心跳(每3秒),但当DataNode停止了心跳,连续30秒没有收到心跳,NameNode不会立刻判断其死亡,而是标记为过时并等待一段时间(10分钟),如果这段时间内仍然没有收到心跳,则默认此DataNode已经死亡。
也就是DataNode掉线后的10分钟+30秒后NameNode就会默认其死亡。
这个时限与两个参数有关:可以在hdfs-site.xml中进行修改。
-
dfs.namenode.heartbeat.recheck-interval:NameNode检查过期DataNode的时间间隔描述:This time decides the interval to check for expired datanodes. With this value and dfs.heartbeat.interval, the interval of deciding the datanode is stale or not is also calculated. The unit of this configuration is millisecond.
默认值:300000毫秒=300秒=5分钟
其中提到了结合另一个参数,可以计算DataNode的过期检查时间,也就10分30秒
-
dfs.heartbeat.interval:DataNode的心跳间隔描述:Determines datanode heartbeat interval in seconds. Can use the following suffix (case insensitive): ms(millis), s(sec), m(min), h(hour), d(day) to specify the time
默认值: 3s
掉线时限时间=2*dfs.namenode.heartbeat.recheck-interval+10*dfs.heartbeat.interval
服役新数据节点
当集群中数据不断增长,当前的数据节点不足够存放数据的时候,最好的办法就是新增数据节点。
具体步骤:
-
与现存集群保存相同的配置
-
启动DataNode、NodeManager?
如果是从现有集群中克隆的一台机器,只是修改了IP和主机名,没有删除hadoop中的data/ logs/目录的话,直接启动会导致克隆和被克隆的机器交替服役,频繁切换。这种现象是不允许出现的!!
-
解决以上问题,就是删除data/ logs/目录
这样简单的操作,一旦NameNode的主机位置暴露了,其他人就可以通过向NameNode所在集群添加一个数据节点,就可以获取到集群中的数据,存在安全威胁。
退役旧数据节点
当集群中某些节点是我们不希望存在的(包括退役的数据节点和外来不明的数据节点),可以通过添加白名单和黑名单来对集群中的节点进行控制。
添加白名单
只允许名单中的节点服役于本集群,一般在集群搭建之初就创建。
-
在/opt/module/hadoop-2.7.7/etc/hadoop/目录下创建一个
dfs.hosts文件,并在文件中添加节点IP名单。(同样不允许有多余空格、空行)例如:
hadoop103 192.168.52.204 192.168.52.xxx -
在hdfs-site.xml中配置
dfs.hosts并分发。<property> <name>dfs.hostname> <value>/opt/module/hadoop-2.7.7/etc/hadoop/dfs.hostsvalue> property>注意一定是完整的路径名,若文件为空则表示允许所有主机可以连接到NameNode。
-
重启集群?不用!直接刷新即可
hdfs dfsadmin -refreshNodes和yarn rmadmin -refreshNodes,会发现数据块副本跟着一起退役了,而并没有产生新的副本,对比学习黑名单退役 -
当新增节点后,如果出现数据不均衡的情况,可以执行
start-balancer.sh对集群中数据再平衡。
黑名单退役
于白名单相反,不允许名单中的节点服役于本集群
-
还是那个目录,创建
dfs.hosts.exclude文件,在其中添加要退役的节点IP。 -
在hdfs-site.xml中配置
dfs.hosts.exclude,并分发<property> <name>dfs.hosts.excludename> <value>/opt/module/hadoop-2.7.7/etc/hadoop/dfs.hosts.excludevalue> property> -
刷新NameNode、ResourceManager
hdfs dfsadmin -refreshNodes、yarn rmadmin -refreshNodes -
执行刷命令后,被退役的节点,会将主机上的数据拷贝到其他节点上,数据越大退役时间越长。
-
退役节点,单节点退出即可。数据不均衡还是使用
start-balancer.sh
注意!!白名单和黑名单可以同时存在!但是!!!两份名单中不能有相同的节点IP
DataNode多目录配置
既然NameNode可以存在多个目录,那DataNode也 可以。
操作步骤:
-
关闭集群
-
在
hdfs-site.xml中配置dfs.datanode.data.dir默认值是:file://${hadoop.tmp.dir}/dfs/data,这里的hadoop.tmp.dir在core-site.xml中我们已经配置
<property> <name>dfs.datanode.data.dirname> <value>file://${hadoop.tmp.dir}/dfs/data1,file://${hadoop.tmp.dir}/dfs/data2value> property>配置完成进行分发。
-
删除所有节点上(NN,DN,2NN)的 data/ logs/目录,准备好对NameNode进行格式化。
-
此时进到DataNode的这个目录下,就会发现data1、data2两个目录
==注意!==在NN中,多目录name1, name2中的数据是完全相同的,起数据备份的作用,提高数据可靠性。
但是 DN上这两个目录却不是这种关系,它们就相当于两个数据目录,存放的也是不同数据。
HDFS 2.X 新特性
集群间的数据拷贝
在搭建环境之初,我们使用scp完成了服务器之间的数据拷贝。但是在开发过程中,测试和生产使用的是两个独立的集群,此时数据拷贝应该使用hadoop distcp命令。
hadoop distcp hdfs://hadoop102:9000/user/sakura/test.txt hdfs://hadoop103:9000/user/sakura/test.txt
使用这个命令就完成了两个集群之间的HDFS的数据拷贝。
小文件存档
问题描述:
由于在HDFS中文件存储采用的是按块存储,每个文件块都有对应的元数据存放在NameNode中,虽然不会因为文件大小的原因浪费文件块的存储容量,但是过量的小文件会产生大量的元数据,从而快速耗尽NameNode的内存容量。
解决方案
HDFS存档文件或HAR文件,是一个高效的文件存档工具,将文件存入HDFS块,在减少NameNode内存使用的同时,允许对文件进行透明的访问。
简单说就是,经过存档后的文件,对于内部来说是一个个的独立个体,对于NameNode来说就是一个整体
具体操作
-
首先在文件夹中准备若干个小文件

-
检查Yarn进程启动
-
开始归档文件,将/user/input目录中的文件归档为一个叫input.har的归档文件,并将归档文件放入/output目录中
用到了hadoop archive命令
hadoop archive -archiveName input.har -p /user/input /user/output -
通过执行过程,其实是进行了一次MapReduce,生成的input.har其实是一个目录,目录中文件似乎与被归档的文件并没有什么关联。

-
一一查看这几个文件的内容,好像意义并不是很大,除了_index和part-0有一些相关的信息:
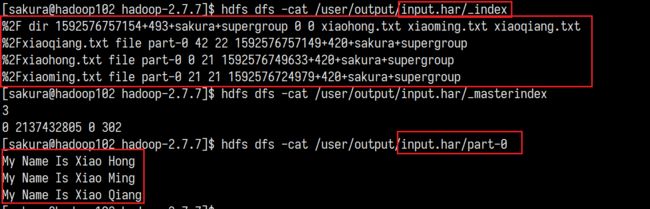
-
其实真正的正确打开方式应该是:解归档文件
hadoop fs -cp har:///user/output/input.har/* /user/output,har是不同于hdfs的一个新的协议!执行完成后,这三个文件又重新出现在视野中:

回收站
开启回收站功能,可以避免数据误删,方便恢复近期删除的数据。此功能默认是关闭的!
要开启Hadoop的回收站功能有两个重要的参数需要配置(core-site.xml)
fs.trash.interval:回收站内文件存活的时限,默认为0表示不支持回收站功能,单位:分钟fs.trash.checkpoint.interval:回收站文件检查间隔,若不配置或为0,此参数与fs.trash.interval值相同,即文件删除后进入回收站,直到文件被自动清除只会检查一次。
要求fs.trash.interval >= fs.trash.checkpoint.interval,否则文件都过期清除了检查就没有意义了。
启动后发现权限不够不能访问:
![]()
默认的用户是dr.who,我需要将其修改(core-site.xml)
<property>
<name>hadoop.http.staticuser.username>
<value>sakuravalue>
property>
现在就会看到/user/sakura/.Trash这个目录,这个目录就是一个回收站,我们删除文件试试看:

一分钟以后这个文件就会被自动删除。
从回收站恢复数据
其实就是使用mv命令将数据从回收站目录移动到其他目录即可。
清空回收站
这里的清空和我们使用回收站清空不同,它只是对回收站中数据进行一个时间戳分类。
hadoop fs -expunge
清空前:

清空后:

快照管理
快照,snapshoot,相当于相机拍照片,保存那一刻节点的状态,后面可以使用快照回到那个状态。
Hadoop HA (高可用)
待补充…