机器学习系列14-为什么要做“深度”学习
Why Deep?
如果本文对你有帮助,请给我的github打个star叭,上面附有全系列目录和内容!
注:更多优质内容欢迎关注我的微信公众号“Sakura的知识库”:

本文主要围绕Deep这个关键词展开,重点比较了shallow learning和deep learning的区别:
shallow:不考虑不同input之间的关联,针对每一种class都设计了一个独立的model检测
deep:考虑了input之间的某些共同特征,所有class用同个model分类,share参数,modularization思想,hierarchy架构,更有效率地使用data和参数
Shallow V.s. Deep
Deep is Better?
我们都知道deep learning在很多问题上的表现都是比较好的,越deep的network一般都会有更好的performance
那为什么会这样呢?有一种解释是:
- 一个network的层数越多,参数就越多,这个model就越复杂,它的bias就越小,而使用大量的data可以降低这个model的variance,performance当然就会更好
如下图所示,随着layer层数从1到7,得到的error rate不断地降低,所以有人就认为,deep learning的表现这么好,完全就是用大量的data去硬train一个非常复杂的model而得到的结果
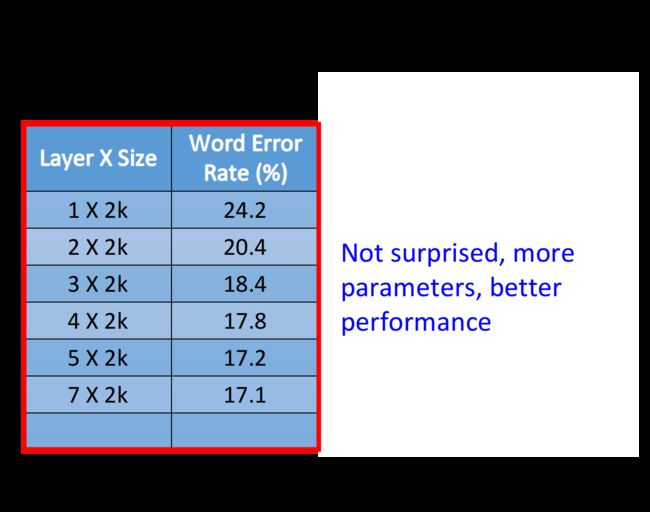
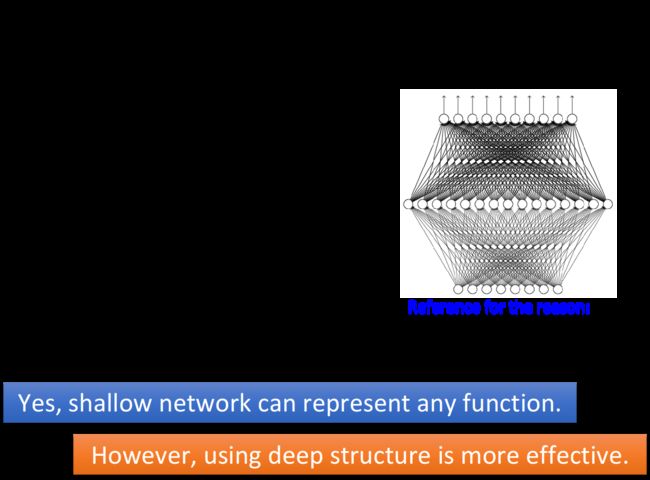
既然大量的data加上参数足够多的model就可以实现这个效果,那为什么一定要用DNN呢?我们完全可以用一层的shallow neural network来做同样的事情,理论上只要这一层里neuron的数目足够多,有足够的参数,就可以表示出任何函数;那DNN中deep的意义何在呢?
Fat + Short v.s. Thin + Tall
其实深和宽这两种结构的performance是会不一样的,这里我们就拿下面这两种结构的network做一下比较:

值得注意的是:如果要给Deep和Shallow的model一个公平的评比,你就要故意调整它们的形状,让它们的参数是一样多的,在这个情况下Shallow的model就会是一个矮胖的model,Deep的model就会是一个瘦高的model
在这个公平的评比之下,得到的结果如下图所示:
左侧表示的是deep network的情况,右侧表示的是shallow network的情况,为了保证两种情况下参数的数量是比较接近的,因此设置了右侧1*3772和1*4634这两种size大小,它们分别对应比较左侧5*2k和7*2k这两种情况下的network(注意参数数目和neuron的数目并不是等价的)
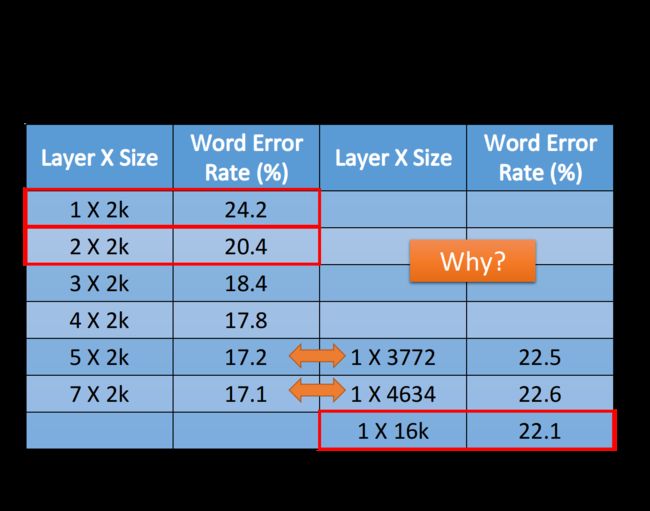
这个时候你会发现,在参数数量接近的情况下,只有1层的network,它的error rate是远大于好几层的network的;这里甚至测试了1*16k大小的shallow network,把它跟左侧也是只有一层,但是没有那么宽的network进行比较,由于参数比较多所以才略有优势;但是把1*16k大小的shallow network和参数远比它少的2*2k大小的deep network进行比较,结果竟然是后者的表现更好
也就是说,只有1层的shallow network的performance甚至都比不过很多参数比它少但层数比它多的deep network,这是为什么呢?
有人觉得deep learning就是一个暴力辗压的方法,我可以弄一个很大很大的model,然后collect一大堆的data,就可以得到比较好的performance;但根据上面的对比可知,deep learning显然是在结构上存在着某种优势,不然无法解释它会比参数数量相同的shallow learning表现得更好这个现象
Modularization
introduction
DNN结构一个很大的优势是,Modularization(模块化),它用的是结构化的架构
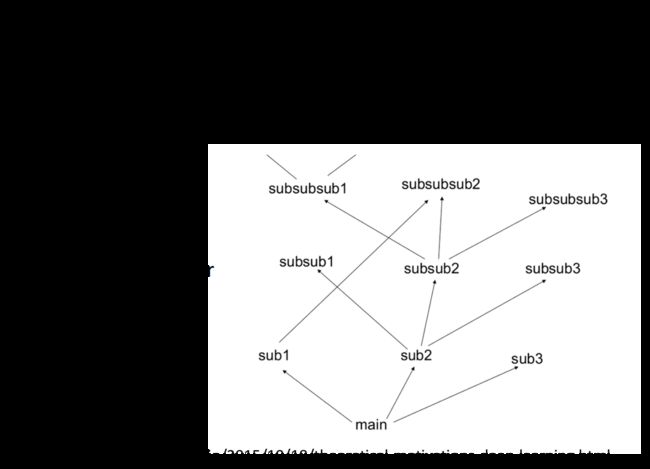
就像写程序一样,shallow network实际上就是把所有的程序都写在了同一个main函数中,所以它去检测不同的class使用的方法是相互独立的;而deep network则是把整个任务分为了一个个小任务,每个小任务又可以不断细分下去,以形成modularization,就像下图一样
在DNN的架构中,实际上每一层layer里的neuron都像是在解决同一个级别的任务,它们的output作为下一层layer处理更高级别任务的数据来源,低层layer里的neuron做的是对不同小特征的检测,高层layer里的neuron则根据需要挑选低层neuron所抽取出来的不同小特征,去检测一个范围更大的特征;neuron就像是一个个classifier ,后面的classifier共享前面classifier的参数
这样做的好处是,低层的neuron输出的信息可以被高层不同的neuron重复使用,而并不需要像shallow network一样,每次在用到的时候都要重新去检测一遍,因此大大降低了程序的复杂度
example
这里举一个分类的例子,我们要把input的人物分为四类:长头发女生、长头发男生、短头发女生、短头发男生
如果按照shallow network的想法,我们分别独立地train四个classifier(其实就相当于训练四个独立的model),然后就可以解决这个分类的问题;但是这里有一个问题,长头发男生的data是比较少的,没有太多的training data,所以,你train出来的classifier就比较weak,去detect长头发男生的performance就比较差
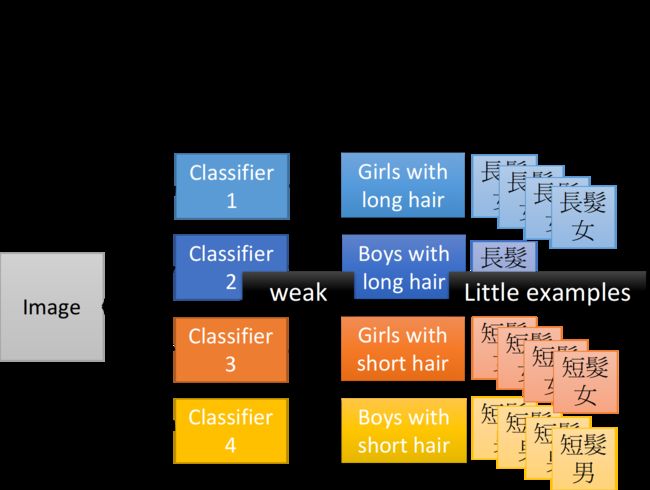
但其实我们的input并不是没有关联的,长头发的男生和长头发的女生都有一个共同的特征,就是长头发,因此如果我们分别独立地训练四个model作为分类器,实际上就是忽视了这个共同特征,也就是没有高效地用到data提供的全部信息,这恰恰是shallow network的弊端
而利用modularization的思想,使用deep network的架构,我们可以训练一个model作为分类器就可以完成所有的任务,我们可以把整个任务分为两个子任务:
- Classifier1:检测是男生或女生
- Classifier2:检测是长头发或短头发
虽然长头发的男生data很少,但长头发的人的data就很多,经过前面几层layer的特征抽取,就可以头发的data全部都丢给Classifier2,把男生或女生的data全部都丢给Classifier1,这样就真正做到了充分、高效地利用数据,最终的Classifier再根据Classifier1和Classifier2提供的信息给出四类人的分类结果
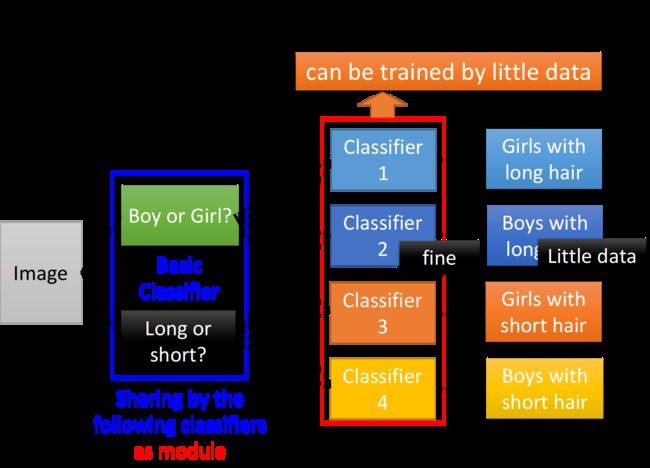
你会发现,经过层层layer的任务分解,其实每一个Classifier要做的事情都是比较简单的,又因为这种分层的、模组化的方式充分利用了data,并提高了信息利用的效率,所以只要用比较少的training data就可以把结果train好
deep -> modularization
做modularization的好处是把原来比较复杂的问题变得简单,比如原来的任务是检测一个长头发的女生,但现在你的任务是检测长头发和检测性别,而当检测对象变简单的时候,就算training data没有那么多,我们也可以把这个task做好,并且所有的classifier都用同一组参数检测子特征,提高了参数使用效率,这就是modularization、这就是模块化的精神
由于deep learning的deep就是在做modularization这件事,所以它需要的training data反而是比较少的,这可能会跟你的认知相反,AI=big data+deep learning,但deep learning其实是为了解决less data的问题才提出的
每一个neuron其实就是一个basic的classifier:
- 第一层neuron,它是一个最basic的classifier,检测的是颜色、线条这样的小特征
- 第二层neuron是比较复杂的classifier,它用第一层basic的classifier的output当作input,也就是把第一层的classifier当作module,利用第一层得到的小特征分类出不同样式的花纹
- 而第三层的neuron又把第二层的neuron当作它module,利用第二层得到的特征分类出蜂窝、轮胎、人
- 以此类推
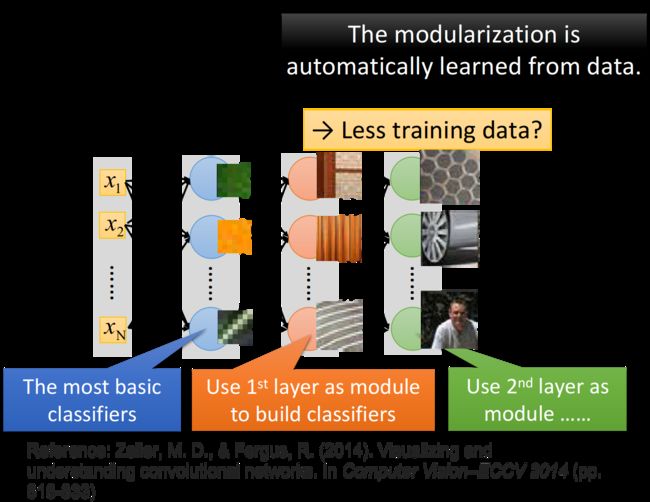
这边要强调的是,在做deep learning的时候,怎么做模块化这件事情是machine自动学到的,也就是说,第一层要检测什么特征、第二层要检测什么特征…这些都不是人为指定的,人只有定好有几层layer、每层layer有几个neuron,剩下的事情都是machine自己学到的
传统的机器学习算法,是人为地根据domain knowledge指定特征来进行提取,这种指定的提取方式,甚至是提取到的特征,也许并不是实际最优的,所以它的识别成功率并没有那么高;但是如果提取什么特征、怎么提取这件事让机器自己去学,它所提取的就会是那个最优解,因此识别成功率普遍会比人为指定要来的高
Speech
前面讲了deep learning的好处来自于modularization(模块化),可以用比较efficient的方式来使用data和参数,这里以语音识别为例,介绍DNN的modularization在语音领域的应用
language basics
当你说what do you think的时候,这句话其实是由一串phoneme所组成的,所谓phoneme,中文翻成音素,它是由语言学家制订的人类发音的基本单位,what由4个phoneme组成,do由两个phoneme组成,you由两个phoneme组成,等等
同样的phoneme也可能会有不太一样的发音,当你发d uw和y uw的时候,心里想要发的都是uw,但由于人类发音器官的限制,你的phoneme发音会受到前后的phoneme所影响;所以,为了表达这一件事情,我们会给同样的phoneme不同的model,这个东西就叫做tri-phone
一个phoneme可以拆成几个state,我们通常就订成3个state

以上就是人类语言的基本构架
process
语音辨识的过程其实非常复杂,这里只是讲语音辨识的第一步
你首先要做的事情是把acoustic feature(声学特征)转成state,这是一个单纯的classification的problem
大致过程就是在一串wave form(声音信号)上面取一个window(通常不会取太大,比如250个mini second大小),然后用acoustic feature来描述这个window里面的特性,每隔一个时间段就取一个window,一段声音信号就会变成一串vector sequence,这个就叫做acoustic feature sequence

你要建一个Classifier去识别acoustic feature属于哪个state,再把state转成phoneme,然后把phoneme转成文字,接下来你还要考虑同音异字的问题…这里不会详细讲述整个过程,而是想要比较一下过去在用deep learning之前和用deep learning之后,在语音辨识上的分类模型有什么差异
classification
传统做法
传统的方法叫做HMM-GMM
GMM,即Gaussian Mixture Model ,它假设语音里的每一个state都是相互独立的(跟前面长头发的shallow例子很像,也是假设每种情况相互独立),因此属于每个state的acoustic feature都是stationary distribution(静态分布)的,因此我们可以针对每一个state都训练一个GMM model来识别
但这个方法其实不太现实,因为要列举的model数目太多了,一般中英文都有30几、将近40个phoneme,那这边就假设是30个,而在tri-phone里面,每一个phoneme随着contest(上下文)的不同又有变化,假设tri-phone的形式是a-b-c,那总共就有30*30*30=27000个tri-phone,而每一个tri-phone又有三个state,每一个state都要很用一个GMM来描述,那参数实在是太多了
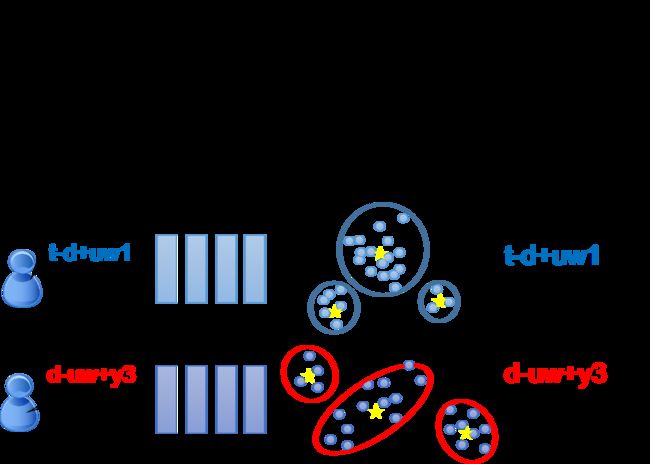
在有deep learning之前的传统处理方法是,让一些不同的state共享同样的model distribution,这件事情叫做Tied-state,其实实际操作上就把state当做pointer(指针),不同的pointer可能会指向同样的distribution,所以有一些state的distribution是共享的,具体哪些state共享distribution则是由语言学等专业知识决定
那这样的处理方法太粗糙了,所以又有人提出了subspace GMM,它里面其实就有modularization、有模块化的影子,它的想法是,我们先找一个Gaussian pool(里面包含了很多不同的Gaussian distribution),每一个state的information就是一个key,它告诉我们这个state要从Gaussian pool里面挑选哪些Gaussian出来
比如有某一个state 1,它挑第一、第三、第五个Gaussian;另一个state 2,它挑第一、第四、第六个Gaussian;如果你这样做,这些state有些时候就可以share部分的Gaussian,那有些时候就可以完全不share Gaussian,至于要share多少Gaussian,这都是可以从training data中学出来的
思考
HMM-GMM的方法,默认把所有的phone或者state都看做是无关联的,对它们分别训练independent model,这其实是不efficient的,它没有充分利用data提供的信息
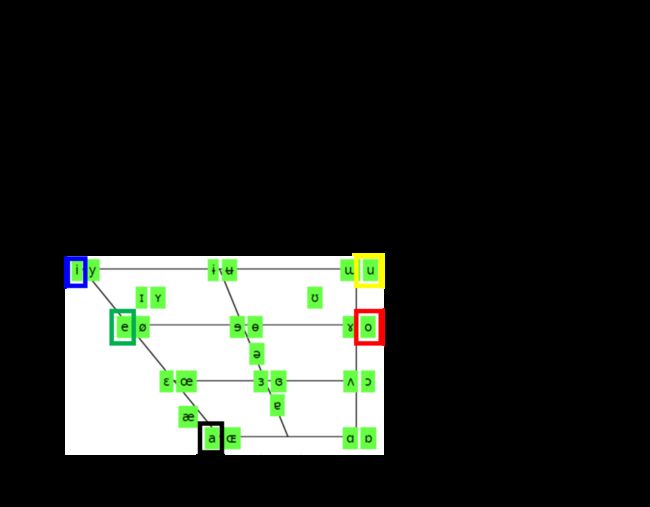
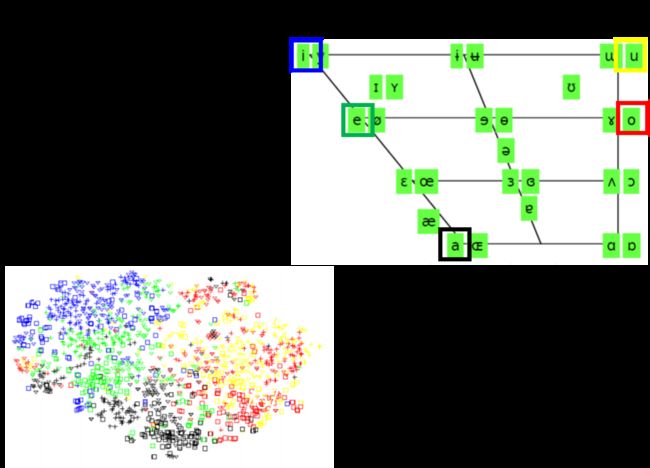
对人类的声音来说,不同的phoneme都是由人类的发音器官所generate出来的,它们并不是完全无关的,下图画出了人类语言里面所有的元音,这些元音的发音其实就只受到三件事情的影响:
- 舌头的前后位置
- 舌头的上下位置
- 嘴型
比如图中所标英文的5个元音a,e,i,o,u,当你发a到e到i的时候,舌头是由下往上;而i跟u,则是舌头放在前面或放在后面的差别;在图中同一个位置的元音,它们舌头的位置是一样的,只是嘴型不一样
DNN做法
如果采用deep learning的做法,就是去learn一个deep neural network,这个deep neural network的input是一个acoustic feature,它的output就是该feature属于某个state的概率,这就是一个简单的classification problem
那这边最关键的一点是,所有的state识别任务都是用同一个DNN来完成的;值得注意的是DNN并不是因为参数多取胜的,实际上在HMM-GMM里用到的参数数量和DNN其实是差不多的,区别只是GMM用了很多很小的model ,而DNN则用了一个很大的model
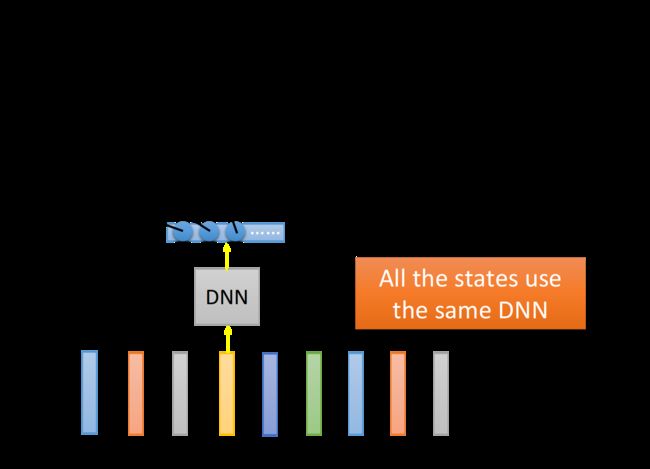
DNN把所有的state通通用同一个model来做分类,会是一种比较有效率的做法,解释如下
我们拿一个hidden layer出来,然后把这个layer里所有neuron的output降维到2维得到下图,每个点的颜色对应着input a,e,i,o,u,神奇的事情发生了:降维图上这5个元音的分布跟右上角元音位置图的分布几乎是一样的
因此,DNN并不是马上就去检测发音是属于哪一个phone或哪一个state,比较lower的layer会先观察人是用什么样的方式在发这个声音,人的舌头位置应该在哪里,是高是低,是前是后;接下来的layer再根据这个结果,去决定现在的发音是属于哪一个state或哪一个phone
这些lower的layer是一个人类发音方式的detector,而所有phone的检测都share这同一组detector的结果,因此最终的这些classifier是share了同一组用来detect发音方式的参数,这就做到了模块化,同一个参数被更多的地方share,因此显得更有效率
result
这个时候就可以来回答之前在8_Deep Learning中提到的问题了
Universality Theorem告诉我们任何的continuous的function都可以用一层足够宽的neural network来实现,在90年代,这是很多人放弃做deep learning的一个原因
但是这个理论只告诉了我们可能性,却没有说明这件事的效率问题;根据上面的几个例子我们已经知道,只用一个hidden layer来描述function其实是没有效率的;当你用multi-layer,用hierarchy structure来描述function的时候,才会是比较有效率的
Analogy
下面用逻辑电路和剪窗花的例子来更形象地描述Deep和shallow的区别
Logic Circuit
逻辑电路其实可以拿来类比神经网络
-
每一个逻辑门就相当于一个neuron
-
只要两级逻辑门就可以表示任何的boolean function;有一个hidden layer的network(input layer+hidden layer共两层)可以表示任何continuous的function
注:逻辑门只要根据input的0、1状态和对应的output分别建立起门电路关系即可建立两级电路
-
实际设计电路的时候,为了节约成本,会进行多级优化,建立起hierarchy架构,如果某一个结构的逻辑门组合被频繁用到的话,其实在优化电路里,这个组合是可以被多个门电路共享的,这样用比较少的逻辑门就可以完成一个电路;在deep neural network里,践行modularization的思想,许多neuron作为子特征检测器被多个classifier所共享,本质上就是参数共享,就可以用比较少的参数就完成同样的function
比较少的参数意味着不容易overfitting,用比较少的data就可以完成同样任务

剪窗花
我们之前讲过这个逻辑回归的分类问题,可能会出现下面这种linear model根本就没有办法分类的问题,而当你加了hidden layer的时候,就相当于做了一个feature transformation,把原来的x1,x2转换到另外一个平面,变成x1’、x2’
你会发现,通过这个hidden layer的转换,其实就好像把原来这个平面按照对角线对折了一样,对折后两个蓝色的点就重合在了一起,这个过程跟剪窗花很像:
- 我们在做剪窗花的时候,每次把色纸对折,就相当于把原先的这个多维空间对折了一次来提高维度
- 如果你在某个地方戳一个洞,再把色纸打开,你折了几折,在对应的这些地方就都会有一个洞;这就相当于在折叠后的高维空间上,画斜线的部分是某一个class,不画斜线的部分是另一个class,那你在这个高维空间上的某一个点,就相当于展开后空间上的许多点,由于可以对这个空间做各种各样复杂的对折和剪裁,所以二维平面上无论多少复杂的分类情况,经过多次折叠,不同class最后都可以在一个高维空间上以比较明显的方式被分隔开来
这样做==既可以解决某些情况下难以分类的问题,又能够以比较有效率的方式充分利用data==(比如下面这个折纸,高维空间上的1个点等于二维空间上的5个点,相当于1笔data发挥出5笔data的作用)

下面举了一个小例子:
左边的图是training data,右边则是1层hidden layer与3层hidden layer的不同network的情况对比,这里已经控制它们的参数数量趋于相同,试验结果是,当training data为10w笔的时候,两个network学到的样子是比较接近原图的,而如果只给2w笔training data,1层hidden layer的情况就完全崩掉了,而3层hidden layer的情况会比较好一些,它其实可以被看作是剪窗花的时候一不小心剪坏了,然后展开得到的结果
注:关于如何得到model学到的图形,可以用固定model的参数,然后对input进行梯度下降,最终得到结果,具体方法见前几章

End-to-end Learning
introduction
所谓的End-to-end learning,指的是只给model input和output,而不告诉它中间每一个function要怎么分工,让它自己去学会知道在生产线的每一站,自己应该要做什么事情;在DNN里,就是叠一个很深的neural network,每一层layer就是生产线上的一个站

Speech Recognition
End-to-end Learning在语音识别上体现的非常明显
在传统的Speech Recognition里,只有最后GMM这个蓝色的block,才是由training data学出来的,前面绿色的生产线部分都是由过去的“五圣先贤”手动制订出来的,其实制订的这些function非常非常的强,可以说是增一分则太肥,减一分则太瘦这样子,以至于在这个阶段卡了将近20年
后来有了deep learning,我们就可以用neural network把DCT、log这些部分取代掉,甚至你从spectrogram开始都拿deep neural network取代掉,也可以得到更好的结果,如果你分析DNN的weight,它其实可以自动学到要做filter bank这件事情(filter bank是模拟人类的听觉器官所制定出来的filter)

那能不能够叠一个很深很深的neural network,input直接就是time domain上的声音信号,而output直接就是
文字,中间完全不要做feature transform之类,目前的结果是,现在machine做的事情就很像是在做Fourier transform,它学到的极限也只是做到与Fourier feature transform打平而已,或许DFT已经是信号处理的极限了
有关End-to-end Learning在Image Recognition的应用和Speech Recognition很像,这里不再赘述
Complex Task
那deep learning还有什么好处呢?
有时候我们会遇到非常复杂的task:
-
有时候非常像的input,它会有很不一样的output
比如在做图像辨识的时候,下图这个白色的狗跟北极熊其实看起来是很像的,但是你的machine要有能力知道,看到左边这张图要output狗,看到右边这张图要output北极熊
-
有时候看起来很不一样的input,output其实是一样的
比如下面这两个方向上看到的火车,横看成岭侧成峰,尽管看到的很不一样,但是你的machine要有能力知道这两个都是同一种东西

如果你的network只有一层的话,就只能做简单的transform,没有办法把一样的东西变得很不一样,把不一样的东西变得很像;如果要实现这些,就需要做很多层次的转换,就像前面那个剪窗花的例子,在二维、三维空间上看起来很难辨别,但是到了高维空间就完全有可能把它们给辨别出来
这里以MNIST手写数字识别为例,展示一下DNN中,在高维空间上对这些Complex Task的处理能力
如果把28*28个pixel组成的vector投影到二维平面上就像左上角所示,你会发现4跟9的pixel几乎是叠在一起的,因为4跟9很像,都是一个圈圈再加一条线,所以如果你光看input的pixel的话,4跟9几乎是叠在一起的,你几乎没有办法把它分开
但是,等到第二个、第三个layer的output,你会发现4、7、9逐渐就被分开了,所以使用deep learning的deep,这也是其中一个理由

Conclusion
Deep总结:
- 考虑input之间的内在关联,所有的class用同一个model来做分类
- modularization思想,复杂问题简单化,把检测复杂特征的大任务分割成检测简单特征的小任务
- 所有的classifier使用同一组参数的子特征检测器,共享检测到的子特征
- 不同的classifier会share部分的参数和data,效率高
- 联系logic circuit和剪纸画的例子
- 多层hidden layer对complex问题的处理上比较有优势
