快速搭建elasticsearch和mysql数据库间的数据同步
标题:本文章讲解的是elasticsearch和数据库之间的同步
注:本教程是elasticsearch和Kibana是采用docker去安装的,在本地虚拟机去搭建,建议虚拟机内存调为2G以上
记得修改为你对应的虚拟机ip
docker安装就省略了,需要安装docker请百度
一,安装elasticsearch
docker命令
1.下载ES镜像问题
docker pull elasticsearch
2.运行ES
docker run -it --name elasticsearch -d -p 9200:9200 -p 9300:9300 -p 5601:5601 elasticsearch
3. 输入网址测试运行结果
http://192.168.248.157:9200/看到这个页面可以进行下一步了

二,安装Kibana
注:Kibana是elasticsearch的可视化工具
docker命令:
1.运行命令
docker run -it -d -e ELASTICSEARCH_URL=http://127.0.0.1:9200 --name kibana --network=container:elasticsearch kibana
2.输入网址测试运行结果
http://192.168.248.157:5601/app/kibana
看到这个页面就成功了

三,安装logstash
3.1通过百度云下载
链接:https://pan.baidu.com/s/1qW9b1q_6lFv8FaRgNBF-yA
提取码:m81n
下载好:通过工具传到/usr/local/目录下,请看下面的命令
3.2通过命令下载
1.进入到/usr/local目录
cd /usr/local
2.下载
wget https://artifacts.elastic.co/downloads/logstash/logstash-6.4.3.tar.gz
3.解压
tar –zxvf logstash-6.4.3.tar.gz
4.进入目录
cd logstash-6.4.3
5.安装logstash-input-jdbc
bin/logstash-plugin install logstash-input-jdbc
6.安装logstash-output-elasticsearch
bin/logstash-plugin install logstash-output-elasticsearch
安装工作就完成了,重要的操作来了,请看下面
四,配置文件
该步骤是配置多个conf,如果你连接一个就配一个就行了
4.1创建sql文件夹
1.还是在local目录下
cd /usr/local
2.创建sql文件夹
mkdir sql
cd sql
进入了sql目录下
4.2请进入下面链接下载对应的东西
链接:https://pan.baidu.com/s/1gLR73LIoEcOrnc-fjB5yZg
提取码:2pta 这个百度云链接有三个文件,把这三个文件按下面操作修改完就上传到sql这个目录里

4.3创建数据库
test数据库的user表
CREATE TABLE `user` (
`id` int(50) NOT NULL AUTO_INCREMENT,
`name` varchar(50) CHARACTER SET utf8 COLLATE utf8_general_ci NULL DEFAULT NULL,
`update_time` datetime(0) NOT NULL DEFAULT CURRENT_TIMESTAMP(0),
PRIMARY KEY (`id`) USING BTREE
) ENGINE = InnoDB AUTO_INCREMENT = 4 CHARACTER SET = utf8 COLLATE = utf8_general_ci ROW_FORMAT = Dynamic;
INSERT INTO `user` VALUES (1, 'hahah', '2020-03-06 15:10:04');
INSERT INTO `user` VALUES (2, '小二', '2020-03-07 15:10:21');
INSERT INTO `user` VALUES (3, '小三', '2020-03-07 15:20:28');
test2数据库的name表
DROP TABLE IF EXISTS `name`;
CREATE TABLE `name` (
`id` int(50) NOT NULL AUTO_INCREMENT,
`name` varchar(255) CHARACTER SET utf8 COLLATE utf8_general_ci NULL DEFAULT NULL,
`update_time` datetime(0) NULL DEFAULT NULL,
PRIMARY KEY (`id`) USING BTREE
) ENGINE = InnoDB AUTO_INCREMENT = 3 CHARACTER SET = utf8 COLLATE = utf8_general_ci ROW_FORMAT = Dynamic;
INSERT INTO `name` VALUES (1, '李1', '2020-03-07 19:59:36');
INSERT INTO `name` VALUES (2, '李2', '2020-03-07 20:00:25');4.4mysql.conf分析
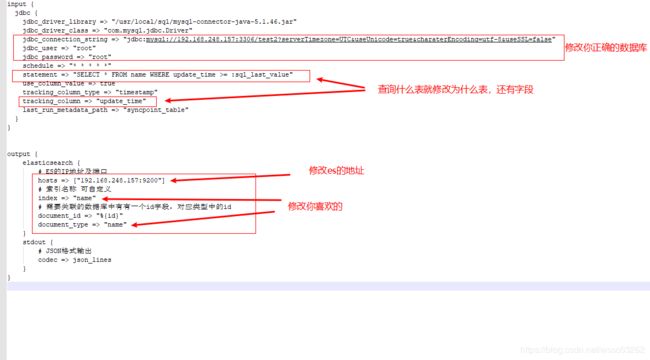
input {
jdbc {
#jar和驱动
jdbc_driver_library => "/usr/local/sql/mysql-connector-java-5.1.46.jar"
jdbc_driver_class => "com.mysql.jdbc.Driver"
#数据库连接,账号,密码
jdbc_connection_string => "jdbc:mysql://192.168.248.157:3306/test2"
jdbc_user => "root"
jdbc_password => "root"
#Crontab表达式以分为单位
schedule => "* * * * *"
#statement要执行的 sql,以 “:” 开头是定义的变量,可以通过 parameters 来设置变量,这里的
#sql_last_value 是内置的变量,表示上一次 sql 执行中 update_time 的值,这里 update_time
#条件是 >= 因为时间有可能相等,没有等号可能会漏掉一些增量
statement => "SELECT * FROM name WHERE update_time >= :sql_last_value"
#use_column_value:使用递增列的值
use_column_value => true
#tracking_column_type:递增字段的类型,numeric 表示数值类型, timestamp 表示时间戳类型
tracking_column_type => "timestamp"
#tracking_column:递增字段的名称,这里使用 update_time 这一列,这列的类型是 timestamp
tracking_column => "update_time"
#last_run_metadata_path: 同步点文件,这个文件记录了上次的同步点,重启时会读取这个文件
last_run_metadata_path => "syncpoint_table"
}
}
output {
elasticsearch {
# ES的IP地址及端口
hosts => ["192.168.248.157:9200"]
# 索引名称 可自定义
index => "name"
# 需要关联的数据库中有有一个id字段,对应类型中的id
document_id => "%{id}"
document_type => "name"
}
stdout {
# JSON格式输出
codec => json_lines
}
}
我们要修改的就这些地方
当你修改完上传后,进入最终操作
1.进入logstash-6.4.3目录
cd /usr/local/logstash-6.4.3
2.修改配置config/pipelines.yml
vi config/pipelines.yml
3.在pipelines.yml后加上下面4行,假设我们有两个表 table1 和 table2,对应两个配置文件
- pipeline.id: table1
path.config: "/usr/local/sql/mysql.conf"
- pipeline.id: table2
path.config: "/usr/local/sql/mysql_1.conf"
4.5运行
1.在/usr/local/logstash-6.4.3目录运行命令
./bin/logstash
要等一会,你就可以看到下面的内容证明和数据库同步成功

在浏览器输入地址http://192.168.248.157:5601/app/kibana#
点击左边导航栏的Dev Tools

这就表示成功啦
这时候在test2数据库name表手动插入一条新的数据测试看看


是不是很简单,嘿嘿