5.1 SAP BW on HANA 数据建模特性
本章节主要介绍优化理念(optimized concepts)、新特性(new features)、对ABAP开发的影响(impact on ABAP development)
5.1.1 Optimized Concepts for SAP BW on SAP HANA
以前使用infoCube是出于性能的考虑(星型模型和减少数据量)。在SAP BW on HANA中,由于HANA的高性能,我们可以直接从DSO出具报表,它的速度会和infoCube一样快。在做完BW on HANA迁移之后就可以考虑是否可以不再使用InfoCube。如果你主要是基于MultiProviders创建查询,在理想的情况下,你可以很容易的使用数据传输层相应的DSO替代相关的InfoCube。当创建新的数据模型的时候,通常就不再考虑使用InfoCube。
首先,如果数据在DSO和InfoCube中都存在,我们可以删除一些数据量比较大的InfoCube,这样不仅能减少内存的需求量,而且能够减少或者简化运维任务。例如,可以减少数据库备份的时间和备份文件的大小,同时由于可以跳过DSO往infoCube上数的这个过程,从而可以减少BW处理链的执行时间。由于几乎所有的数据都保留在内存里面,巨大的数据量会导致内存的紧缺,必须要升级硬件或者是归档数据(例如使用NLS,近线存储方案),这种情况下,删除InfoCube就可以更加有效的使用内存,释放的内存可以应用于未来的数据增长。
然而,还是有一些原因需要你在BW on HANA的环境下面继续使用InfoCube,例如
- 从使用InfoCube转换到使用DSO需要付出巨大的工作量
- 当数据抽取到InfoCube的时候包含逻辑转换
- 非累计关键值(non-cumulative key figures)的使用,例如库存模块
- BW集成规划模块的实时InfoCube
- 通过RSDRI接口访问InfoCube
- 使用virtual Info Providers
- 模型需要超过16个主键(key fields)(DSO最多只能创建16个key fields)
HANA-optimized InfoCube
如果由于这些原因你想继续使用InfoCube,你可以将它转化为HANA-optimized InfoCube,后面会介绍它与传统的InfoCube有什么区别
New CompositeProvider as the basis for BEx queries
到目前为止,SAP推荐不要直接基于InfoCube或者是DSO创建Query,而是基于MutiProvider,主要原因是使用MutiProvider可以结合不同的InfoProvider的数据。即便是Query是从一个InfoProvider中出的,为了方便以后的扩展也推荐使用MutiProvider。在BW on HANA (7.4 SPS 05之后).中,SAP放弃了这个建议,CompositeProvider将替代MutiProvider,从长远的来看,它会替代InfoSets, TransientProviders 和 VirtualProviders。
Merging SAP BW data and data from SAP HANA views
SAP BW on HANA可以合并HANA View的数据。你可以通过SAP Lumira 和 SAP BusinessObjects Design Studio等工具直接消费HANA里面的数据,一些特殊的数据模型必须直接在HANA里面创建,过往的经验表明,你可以有效的结合HANA和BW的优势,这个具体后面章节会详细介绍
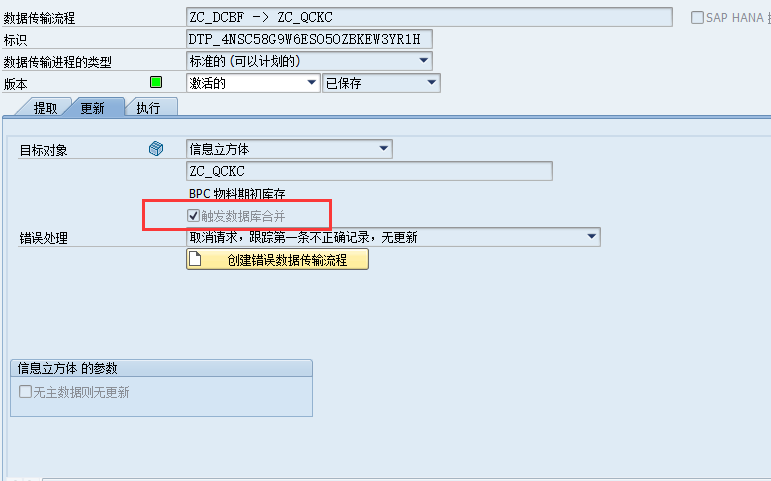
Delta merge and DTPs
在HANA里面,数据的更改最初是存储在delta storage中,通过delta merge的过程,改变的数据记录会异步传输到Main storage中。在激活之后,BW系统会自动检查每个DSO是否需要执行delta merge。这个与infoCube不同,对于标准的和HANA-optimized的InfoCube,你可以使用DTP中的一个选项TRIGGER DATABASE MERGE去设置在数据加载之后是否需要delta merge。如果你希望在整个数据加载过程之后执行delta merage,这个选项是很有用的。
5.1.2 New Features in SAP BW on SAP HANA
SAP BW on HANA新特性如下表

5.1.2.1 Smart Data Access
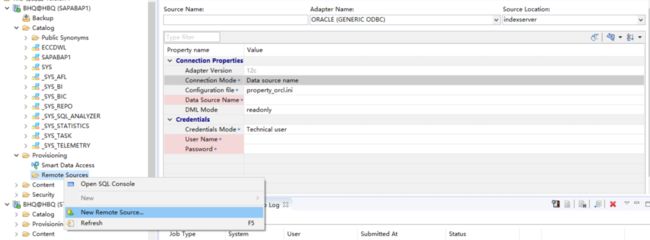
在HANA SPS 6以后,我们就可以使用SDA了。通过SDA你可以在HANA里面创建virtual table,它可以被BW当作数据源来使用,而且不需要在本地保存原始的数据。
支持以下数据库

创建SDA
5.1.2.2 Open ODS View
在以往的BW中,你需要做很多步骤才能出具报表,例如从数据抽取到创建key figure和character,再到多维数据模型的创建。在BW on HANA中,你可以使用Open ODS View避免复杂的建模步骤,Open ODS View需要在HANA studio里面创建。Open ODS View与Smart Data Access的结合能够加快整个建模的过程,你可以通过创建一个ODS view来使用Smart Data Access产生的virtual table,这样你就不需要加载数据。创建Open ODS View的时候你也可以选择不分配InfoObject,但是这样就无法实现一些过于复杂的模型。
具体创建过程参照如下链接
http://blog.csdn.net/hqx8023/article/details/72188669
5.1.2.3 The HANA CompositeProvider (HCPR)
HANA CompositeProvider的意义在于它能够通过UINION或者是JION高效的合并BW中的数据,HANA CompositeProvider将来在BW的虚拟数据层会成为一个非常重要的对象,根据SAP的计划,HANA CompositeProvider是用来取代MultiProvider,Infoset,TransientProviders,VirtualProviders。
Providers Supported for Union Operations
- SAP HANA models (calculation views and analytic views)
- The following BW InfoProviders: InfoCube, DataStore object (creates SID values in reporting or when activated), semantically partitioned object, Open ODS view, InfoObject, analytic index, VirtualProvider, InfoSet, aggregation level
通过BW生成的HANA model是不支持的,MutiProvider也不支持
如果使用Open ODS Views只支持 CHAR, CUKY, CURR, DEC, DATS, FLTP, INT4, NUMC, TIMS, QUAN, UNIT这些数据类型
Providers Supported for Join Operations
- SAP HANA models (calculation views and analytic views)
- The following BW InfoProviders: InfoCube, DataStore object (with creation of SID values on activation), InfoObject, analytic index, semantically partitioned object
If the semantically partitioned object is based on DataStore objects, the option for creating SIDs when activating must be switched on. Only one semantically partitioned object can be used as a left join partner.
Providers Supported for Join and Union Operations
- SAP HANA models (calculation views and analytic views)
- The following BW InfoProviders: InfoCube, DataStore object (with creation of SID values), InfoObject, analytic index, semantically partitioned objects

5.1.2.4 Operational Data Provisioning (ODP)
使用Operational Data Provisioning能够从各种数据源抽取数据到BW中,BW会通过DTP从源系统直接抽取数据,不再将数据存储在PSA中。ODP也支持增量数据,增量数据保存在源系统的Operational Delta Queue (ODQ)中,同一数据源支持多消费者模式,使用ODQ有如下优点
- 减少数据冗余
- 保存在ODQ中的数据有很高的压缩比,根据SAP官方的说法,压缩比可以达到90%
下图是使用ODP将一个ERP系统的数据复制到两个BW系统中


5.1.2.5 Code Push-Down in Transformations
- DSO request激活:激活操作下沉到了HANA中,由于内存技术和大规模并行,整个激活过程非常快,而且应用层和数据库层不需要传输大量的数据,因为需要做的计算已经直接在数据库层面执行了。
- bw transformation转换:由于源表与目标表都在数据库中,所以把整个传输过程下沉到数据库层面就很有必要
在 SAP BW on SAP HANA 7.4 SPS 05,还不能在HANA上面执行所有的transformation,以下情况支持转换逻辑下沉
- 简单mapping
- 转换(时间、单位、货币)
- 公式
- 从DSO读取主数据
- 专家例程(使用HANA SQLScript)
5.1.2.6 Generating SAP HANA Views from lnfoProviders
在BW on HANA里面,勾选如下选项,可以从InfoProvider生成HANA View,通过这种方式生成的view不在BW系统中使用,是给外部的前端工具或者是HANA建模使用,
以下InfoProvider可以生成视图
- HANA CompositeProvider
- SID generation的DSO
- SAP HANA-optimized InfoCube
- InfoObject 类型是characteristic

生成视图路径可以通过如下方式指定
T-CODE:SPRO 路径:SAP NETWEAVER -> BUSINESS WAREHOUSE -> GENERAL SETTINGS -> SETTINGS
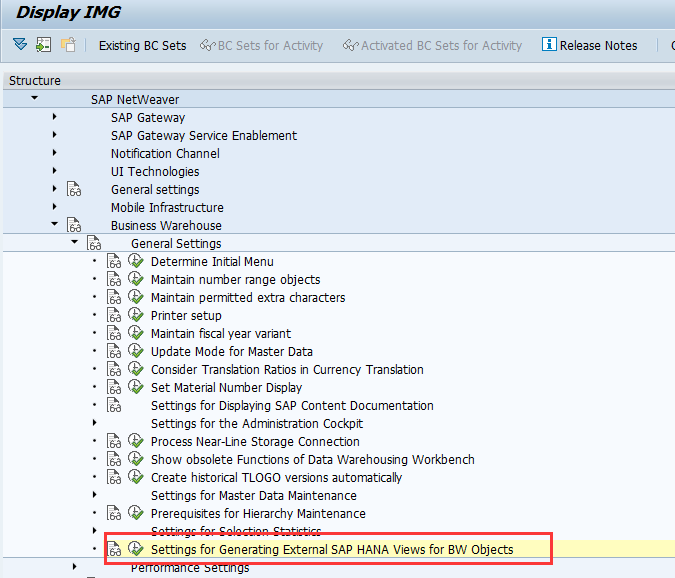
设置完之后,可以在相应的路径下面看到生成的视图

5.1.3 Impact of SAP BW on SAP HANA on ABAP Development
使用ABAP访问HANA遵循以下5个原则
- 尽可能缩小结果集(查询时添加where条件)
- 传输数据量最小化
- 数据传输数量最小化
- 最小化查询付出
- 避免不必要的数据加载
以下是传统ABAP例子和优化建议
Avoiding SELECT •
避免使用select * ,因为使用select * 会查询所有的列,由于HANA是列存储的,从列中读取数据的代价很大,所以在select语句中要明确查询的列。同样要避免使用select single
Using the WHERE condition
当处理海量数据和查询大表的时候,使用where条件缩小结果集,最小化在HANA上的查询时间
Using SAP HANA procedures
为了优化性能,可以创建HANA procedure,然后使用ABAP代码调用,类似于使用ABAP methods
Using standard functions
在过去,有时候需要编写ABAP,但是现在由于push-down的原则,HANA优化了很多标准function,例如使用READ MASTER DATA function读取主数据,使用READ FROM DATASTORE从DSO读取数据,如果你需要访问infocube或者是infoset,可以使用标准API RSDRI_INFOPROV_READ。使用ABAP Routine Analyzer ,你可以自动的分析data flow,process chain,transformation,这个工具后面会有介绍。