armlink 第四章 scatter文件举例
armlink 第四章 scatter文件举例
在前面学习了基本术语和概念之后,本章是加强scatter编写能力的章节。
4.1 什么时候使用scatter文件
scatter文件通常用于嵌入式系统中,因为这些系统含有ROM,RAM,还有一些内存映射的外设。下面的场景常使用scatter文件:
-
复杂的内存映射:放在不同内存区域的section,需要使用scatter文件来更精细的操控放置的位置
-
不同的存储类型:许多系统包含各种各样的存储设备,如flash,ROM,SDRAM,SRAM等。这时可以使用scatter文件,将更适合的存储区域放置更适合的代码。例如:中断代码放置在SRAM中,已达到快速响应的目的;而不频繁访问的配置信息可以放置在flash存储中。
-
内存映射的外设:在内存映射机制下,scatter文件可以在一个精确的地址放置数据section。这样访问这个数据section就相当于访问对应的外设。
-
在固定地址存放函数:即使修改并重新编译了应用程序,而跟应用程序紧密相关的函数还是可以放置在一个固定的位置。这个对于跳转表的实现非常有用。
-
使用符号标记堆和栈:当应用被链接时,可以为堆和栈定义符号
4.2 在scatter文件中指定堆和栈
在c语言中,常常需要两个存储区域,堆和栈。在所有的内存都由我们分配的情况下,堆和栈也需要我们进行分配。
在程序开始运行之前,会调用__user_setup_stackheap()函数,它负责初始化堆和栈。而这个函数根据我们在scatter文件中的设置来初始化。
要想正确的初始化堆和栈。我们需要在scatter文件中定义两个特殊的执行region。分别叫做ARM_LIB_HEAP 和ARM_LIB_STACK。这两段内存由c库进行初始化,所以不能放置任何输入section,此时应该设置EMPTY属性。同时也可以给这两个内存区域设置基址和大小。如下:
LOAD_FLASH …
{
…
ARM_LIB_STACK 0x40000 EMPTY -0x20000 ; 栈区,向下增长
{ }
ARM_LIB_HEAP 0x28000000 EMPTY 0x80000 ; 堆区向上增长
{ }
…
}
当然还有更简单的用法,只需要定义一个特殊的执行region,叫做ARM_LIB_STACKHEAP,同样他需要有EMPTY属性,并设置基址和大小
4.3 使用scatter文件描述一个简单的镜像
如下图,是一个简单的镜像内存视图。

下面根据这个图,来写一个scatter文件
LOAD_ROM 0x0000 0x8000 ; 加载region的名字叫LOAD_ROM
; 基址0x0000
; 最大大小0x8000
{
EXEC_ROM 0x0000 0x8000 ; 第一执行region的名字叫做EXEC_ROM
; 基址0x000
; 最大大小0x8000
{
* (+RO) ; 放置所有的代码和RO数据
}
SRAM 0x10000 0x6000 ; 第二个执行region叫SRAM
; 基址 0x10000
; 最大大小 0x6000
{
* (+RW, +ZI) ; 放置所有的RW数据和ZI数据
}
}
4.4 使用scatter文件描述一个稍微复杂的镜像
如下图

下面的例子展示了上图对应的scatter描述
LOAD_ROM_1 0x0000 ; 第一个加载region的基址为0x0000
{
EXEC_ROM_1 0x0000 ; 第一个执行region的基址为0x0000
{
program1.o (+RO) ; 放置programe1.o中的所有的代码和RO数据
}
DRAM 0x18000 0x8000 ; 这个执行region的基址为0x18000,最大大小为0x8000
{
program1.o (+RW, +ZI) ; 放置program1.o中的所有的RW数据和ZI数据
}
}
LOAD_ROM_2 0x4000 ; 第二个加载region的基址为0x4000
{
EXEC_ROM_2 0x4000
{
program2.o (+RO) ; 放置programe2.o中的所有的代码和RO数据
}
SRAM 0x8000 0x8000
{
program2.o (+RW, +ZI) ; 放置program2.o中所有的RW数据,和ZI数据
}
}
注意:在上面这个例子中,如果再次新增一个program3.o文件。我们需要将program3.o也放置进去。当然,你也可以使用通配符*,或者.ANY来匹配剩下的所有文件。
4.5 在指定地址放置函数和数据
为了单独放置函数和数据,需要将这些函数和数据与源文件中的剩下的部分分开来对待。
链接器有两种方法使我们能够在指定位置放置section:
- 在scatter文件中定义一个指定位置的执行region,然后在这个region中放置需要的section。
- 定义"__at" section .这些特殊section能够根据名字而获得放置地址。
为了将函数或者数据放置在一个特殊位置,他们必须放置在某个section中。下面几种方式可以达到此目的:
- 放置函数和数据在他们自己单独的源文件中
- 使用__attribute__((at(address)))将变量放置在指定位置的section中
- 使用__attribute__((section(“name”)))将函数或者变量放置在指定名字的section中。
- 在汇编代码中,使用AREA伪指令。因为AREA伪指令是汇编当中最小的可定位的单元
- 使用–split_sectoins 编译选项,为每个源文件中的函数生成一个section
下面举例说明。
4.5.1 不使用scatter,在指定的地址放置变量
- 创建main.c源文件包含下面的代码
#include - 创建function.c源文件包含下面的代码
int sqr(int n1)
{
return n1*n1;
}
- 编译并连接源文件:
armcc -c -g function.c
armcc -c -g main.c
armlink --map function.o main.o -o squared.axf
--map表示显示内存映射。
在上面例子中,__attribute__((at(0x5000)))指示全局变量gSquared放置于绝对地址0x5000处。
内存映射如下:
…
Load Region LR$$.ARM.__at_0x00005000 (Base: 0x00005000, Size: 0x00000000, Max: 0x00000004,ABSOLUTE)
Execution Region ER$$.ARM.__at_0x00005000 (Base: 0x00005000, Size: 0x00000004, Max:0x00000004, ABSOLUTE, UNINIT)
Base Addr Size Type Attr Idx E Section Name Object
0x00005000 0x00000004 Zero RW 13 .ARM.__at_0x00005000 main.o
4.5.2 使用scatter,在一个命名的section中放置变量
- 创建main.c包含如下源文件
#include - 创建functio.c包含下面代码
int sqr(int n1)
{
return n1*n1;
}
- 创建scatter文件scatter.scat 包含如下配置
LR1 0x0000 0x20000
{
ER1 0x0 0x2000
{
*(+RO) ; 余下的代码和只读数据放置在此处
}
ER2 0x8000 0x2000
{
main.o
}
ER3 0x10000 0x2000
{
function.o
*(foo) ; 将gSquared放置在此处
}
; RW和ZI数据放置在0x200000处
RAM 0x200000 (0x1FF00-0x2000)
{
*(+RW, +ZI)
}
ARM_LIB_STACK 0x800000 EMPTY -0x10000
{
}
ARM_LIB_HEAP +0 EMPTY 0x10000
{
}
}
ARM_LIB_STACK 和 ARM_LIB_HEAP region是必须的,因为程序和c库进行链接
- 编译并链接源文件
armcc -c -g function.c
armcc -c -g main.c
armlink --map --scatter=scatter.scat function.o main.o -o squared.axf
上例,__attribute__((section(“foo”))) 指示了gSquared 被放置在名字叫foo的section中。scatter文件也说明了将foo section放置在ER3执行region中。
内存映射如下:
Load Region LR1 (Base: 0x00000000, Size: 0x00001570, Max: 0x00020000, ABSOLUTE)
…
Execution Region ER3 (Base: 0x00010000, Size: 0x00000010, Max: 0x00002000, ABSOLUTE)
Base Addr Size Type Attr Idx E Section Name Object
0x00010000 0x0000000c Code RO 3 .text function.o
0x0001000c 0x00000004 Data RW 15 foo main.o
…
4.5.3 在指定位置放置变量
- 创建main.c文件,如下;
#include - 创建functon.c源文件,如下:
int sqr(int n1)
{
return n1*n1;
}
- 创建scatter文件scatter.scat如下:
LR1 0x0
{
ER1 0x0
{
*(+RO) ; 剩下的只读代码
}
ER2 +0
{
function.o
*(.ARM.__at_0x10000) ; 放置gValue在0x10000
}
; RW和ZI放置在0x200000
RAM 0x200000 (0x1FF00-0x2000)
{
*(+RW, +ZI)
}
ARM_LIB_STACK 0x800000 EMPTY -0x10000
{
}
ARM_LIB_HEAP +0 EMPTY 0x10000
{
}
}
- 编译并链接源文件
armcc -c -g function.c
armcc -c -g main.c
armlink --no_autoat --scatter=scatter.scat --map function.o main.o -o squared.axf
从内存映射图中,可以看到变量在ER2中的0x10000处
…
Execution Region ER2 (Base: 0x00001578, Size: 0x0000ea8c, Max: 0xffffffff, ABSOLUTE)
Base Addr Size Type Attr Idx E Section Name Object
0x00001578 0x0000000c Code RO 3 .text function.o
0x00001584 0x0000ea7c PAD
0x00010000 0x00000004 Data RO 15 .ARM.__at_0x10000 main.o
…
在这个例子中,ER1的大小未知。因此,gValue可能被放置ER1也可能放置在ER2中。
为了保证放在ER2中,你必须在ER2中包含对应的section匹配文字。并且在链接的时候,还必须指定--no_autoat命令行选项。
如果忽略了--no_autoat选项,gValue将被单独放置,对应于
LR$$.ARM.__at_0x10000加载region。
该region包含的执行region为
ER$$.ARM.__at_0x10000
注意:at形式的缩写。
//放置 variable1 在 .ARM.__AT_0x00008000处 int variable1 __attribute__((at(0x8000))) = 10; //放置 variable2 在.ARM.__at_0x8000处 int variable2 __attribute__((section(".ARM.__at_0x8000"))) = 10;上面的section名字,忽略大小写
__at具有如下的限制:
- __at section的地址范围内不能覆盖。
- __at section不准放在位置无关的执行region中
- __at section不能引用链接器定义的这些符号:
$$Base,$$Limit,$$Length.
- __at section 不准用在SysV,BPABI,以及BPABI的动态链接库上。
- __at section 的地址必须是对齐的整数倍
- __at section 忽略+FIRST后者+LAST
4.6 __at section的自动放置
链接器自动放置__at section。当然也可以手动放置,在下一小节中介绍
链接器通过--autoat指示链接器自动放置__at setcion。这个选项默认是打开的。
当使用--autoat链接时,__at section 不会被放置在scatter文件中的与section模式字符串匹配的region中。而是将这个section放在一个兼容的region中。如果没有兼容的region,则创建兼容的region。
带有--autoat选项的所有链接器,创建的region都有UNINIT属性。如果需要将这个__at section放置在一个ZI region中,则必须放置在兼容region中。
兼容region满足如下条件:
-
__at 的地址刚好处在执行region的地址范围内。如果一个region没有设置最大大小,链接器将排除__at section之后,计算大小,这个大小再加上一个常量作为其最后的大小。这个常量默认值为10240字节。他可以通过--max_er_extension命令行选项来调整。
-
这个执行region还需要满足如下的条件:
- 具有模式字符串,并能够匹配这个section
- 至少有一个section和__at section 具有相同的类型(RO,RW,ZI)
- 没有EMPTY属性
来个例子:
//放置RW变量在叫做.ARM.__at_0x02000的section中
int foo __attribute__((section(".ARM.__at_0x2000"))) = 100;
//放置ZI变量在.ARM.__at_0x4000的section中
int bar __attribute__((section(".ARM.__at_0x4000"),zero_init));
//放置ZI变量在.ARM.__at_0x8000的section中
int variable __attribute__((section(".ARM.__at_0x8000"),zero_init));
对应的scatter文件如下:
LR1 0x0
{
ER_RO 0x0 0x2000
{
*(+RO) ; .ARM.__at_0x0000 lies within the bounds of ER_RO
}
ER_RW 0x2000 0x2000
{
*(+RW) ; .ARM.__at_0x2000 lies within the bounds of ER_RW
}
ER_ZI 0x4000 0x2000
{
*(+ZI) ; .ARM.__at_0x4000 lies within the bounds of ER_ZI
}
}
; 链接器为.ARM.__at_0x8000创建一个加载和执行region。因为它超出了所有候选region的大小。
4.7 手动放置__at section
使用--no_autoat命令行选项,然后使用标准的模式匹配字符串去控制__at section的放置。
举例如下:
//放置RO变量在.ARM.__at_0x2000
const int FOO __attribute__((section(".ARM.__at_0x2000"))) = 100;
//放置RW变量在.ARM.__at_0x4000
int bar __attribute__((section(".ARM.__at_0x4000")));
对应的scatter文件如下:
LR1 0x0
{
ER_RO 0x0 0x2000
{
*(+RO) ; .ARM.__at_0x0000 is selected by +RO
}
ER_RO2 0x2000
{
*(.ARM.__at_0x02000) ; .ARM.__at_0x2000 is selected by the section named
; .ARM.__at_0x2000
}
ER2 0x4000
{
*(+RW +ZI) ; .ARM.__at_0x4000 is selected by +RW
}
}
4.8 使用__at 映射一个外设寄存器
为了将一个未初始化的变量映射为一个外设寄存器。可以使用ZI __at section。
假设这个寄存器的地址为0x10000000,定义一个section叫做.ARM.__at_0x10000000.如下:
int foo __attribute__((section(".ARM.__at_0x10000000"),zero_init))
手动放置的scatter文件如下:
ER_PERIPHERAL 0x10000000 UNINIT
{
*(.ARM.__at_0x10000000)
}
4.9 使用.ANY 来放置未分配的 section
在大多数情况下,单个.ANY 等价于使用*。但是,.ANY 可以出现在多个执行region中。
4.9.1 多个.ANY 的放置规则
当使用多个.ANY时,链接器有自己默认的规则来组织section。
当多个.ANY 存在于scatter文件中时,链接器以section的大小,从大到小排序。
如果多个执行region都有相同特性(后文称为等价)的.ANY,那么这个section会被分配到具有最多可用空间的region中。
例如:
- 如果有两个等价的执行region,一个大小为0x2000,另一个没有限制。那么.ANY匹配的section会放置在第二个中。
- 如果有两个等价的执行region,一个大小为0x2000,另一个为0x3000. 那么.ANY匹配的section会先放置在第二个中,直到第二个的大小小于第一个。
相当于这个两个执行region在交替放置。
4.9.2 命令行选项控制多个.ANY的放置
可以通过命令行选项,控制.ANY的排序,下面的命令行选项是可用的:
-
--any_placement=algorithm algorithm是如下之一:first_fit,worst_fit,best_fit,或者next_fit
-
--any_sort_order=order.此处order是如下之一:cmdline或者descending_size
当你想要按照顺序填充region时,使用first_fit
当你想要填满整个region时,使用best_fit
当你想要均匀填充region时,使用worst_fit
当你想要更精确的填充时,使用next_fit
因为,链接器会产生veneer代码以及填充数据,而这些代码的是在.ANY匹配之后产生的。所以,如果.ANY将region填满,则很有可能导致整个regoin无法放置,链接器产生的代码。链接器会产生如下的错误。
Error: L6220E: Execution region regionname size (size bytes) exceeds limit (limit bytes)
--any_contingency选项防止链接器将region的大小填满。它保留region的一部分空间。当链接器产生的代码没有空间时,就使用这部分保留的空间。
first_fit和best_fit 默认打开这个选项。
4.9.3 优先级
.ANY 还可以指定优先级。
优先级通过后面接一个数字来表示,从0开始递增。数字越大优先级越高。
例子如下:
lr1 0x8000 1024
{
er1 +0 512
{
.ANY1(+RO) ; 优先级较低,和er3交替均匀填充
}
er2 +0 256
{
.ANY2(+RO) ; 优先级最高,先填充这个
}
er3 +0 256
{
.ANY1(+RO) ;优先级较低,和er1交替均匀填充
}
}
4.9.4 指定.ANY的最大大小
使用ANY_SIZE max_size 指定最大大小。
例子如下:
LOAD_REGION 0x0 0x3000
{
ER_1 0x0 ANY_SIZE 0xF00 0x1000
{
.ANY
}
ER_2 0x0 ANY_SIZE 0xFB0 0x1000
{
.ANY
}
ER_3 0x0 ANY_SIZE 0x1000 0x1000
{
.ANY
}
}
上面例子中:
- ER_1 有0x100的保留空间,该保留空间用于链接器产生的内容
- ER_2 有0x50的保留空间
- ER_3 没有保留空间。region将会被填满。应该将ANY_SIZE的大小,限制在region大小的98%以内。以预留2%用于链接器产生的内容。
4.9.5 例子1
有6个同样大小的section。如下:
| 名字 | 大小 |
|---|---|
| sec1 | 0x4 |
| sec2 | 0x4 |
| sec3 | 0x4 |
| sec4 | 0x4 |
| sec5 | 0x4 |
| sec6 | 0x4 |
对应的scatter文件如下:
LR 0x100
{
ER_1 0x100 0x10
{
.ANY
}
ER_2 0x200 0x10
{
.ANY
}
}
- 对于first_fit: 首先分配所有section到ER_1中,然后再是ER_2中
- 对于next_fit:跟first_fit一样,但是ER_1会被填满,然后被标记为FULL。
- 对于best_fit: 首先sec1分配到ER_1中,然后ER_2和ER_1优先级相同,且ER_2空间比ER_1空间大,接着分配sec2到ER_1中。直到ER_1填满
- 对于worst_fit:首先分配sec1到ER_1中,然后ER_2空间比ER_1大,接着分配sec2到ER_2中。剩下的两个region空间一样大,且优先级相同,然后选择scatter的第一个,将sec3分配到ER_1中,依次类推。
4.9.6 例子2——使用next_fit
有下面的section:
| 名字 | 大小 |
|---|---|
| sec1 | 0x14 |
| sec2 | 0x14 |
| sec3 | 0x10 |
| sec4 | 0x4 |
| sec5 | 0x4 |
| sec6 | 0x4 |
对应的scatter如下:
LR 0x100
{
ER_1 0x100 0x20
{
.ANY1(+RO-CODE)
}
ER_2 0x200 0x20
{
.ANY2(+RO)
}
ER_3 0x300 0x20
{
.ANY3(+RO)
}
}
详细步骤如下:
- 首先sec1 被分配给ER_1.因为ER_1有更佳的匹配。ER_1现在还剩下0x6个字节
- 链接器尝试将sec2分配给ER_1,因为它有更佳的匹配。但是ER_1没有足够的空间。因此ER_1被标记为FULL,并且在后续的过程中再也不会考虑给ER_1分配section。链接器选择ER_3,因为它有更高的优先级
- 链接器尝试将sec3分配给ER_3,但是无法放入,因此被标记为FULL,接着链接器将sec3放在ER_2中。
- 链接器现在处理sec4.它大小为0x4,适合ER_1和ER_3.但是这两个在前面步骤中被标记为FULL。因此剩下的section被放置在ER_2中。
- 如果还有一个section叫做sec7,且大小为0x8.他将链接失败。
4.9.7 例子三
有两个文件sections_a.o和sections_b.o,如下:
| 名字 | 大小 |
|---|---|
| seca_1 | 0x4 |
| seca_2 | 0x4 |
| seca_3 | 0x10 |
| seca_4 | 0x14 |
| 名字 | 大小 |
|---|---|
| secb_1 | 0x4 |
| secb_2 | 0x4 |
| secb_3 | 0x10 |
| secb_4 | 0x14 |
使用如下命令:
--any_sort_order=descending_size sections_a.o sections_b.o --scatter scatter.txt
排序之后,如下:
| 名字 | 大小 |
|---|---|
| seca_4 | 0x14 |
| secb_4 | 0x14 |
| seca_3 | 0x10 |
| secb_3 | 0x10 |
| seca_1 | 0x4 |
| seca_2 | 0x4 |
| secb_1 | 0x4 |
| secb_2 | 0x4 |
如果使用如下命令:
--any_sort_order=cmdline sections_a.o sections_b.o --scatter scatter.txt
排序之后如下:
| 名字 | 大小 |
|---|---|
| seca_1 | 0x4 |
| secb_1 | 0x4 |
| seca_2 | 0x4 |
| secb_2 | 0x4 |
| seca_3 | 0x10 |
| secb_3 | 0x10 |
| seca_4 | 0x14 |
| secb_4 | 0x14 |
4.10 控制venner的放置
在scatter文件中,还可以放置venner代码。使用Venner$$Code来匹配venner代码。
4.11 带有OVERLAY属性的放置
可以在同一个地址中,放置多个执行region。因此在某一个时刻,只有一个执行region被激活。
如下面的例子:
EMB_APP 0x8000
{
...
STATIC_RAM 0x0
{
*(+RW,+ZI)
}
OVERLAY_A_RAM 0x1000 OVERLAY
{
module1.o (+RW,+ZI)
}
OVERLAY_B_RAM 0x1000 OVERLAY
{
module2.o (+RW,+ZI)
}
...
}
被OVERLAY标记的region,在启动的时候,不会被c库初始化。而这部分内存的内容由overlay 管理器负责。如果这部分region包含有初始化数据。需要使用NOCOMPRESS属性来阻止RW 数据的压缩。
OVERLAY 属性还可以用在单个执行region中,因此,这个region可以被用作:防止c库初始化某个region
OVERLAY region也可以使用相对基址。如果他们有相同的偏移,则连续放置在一起。
如下例子:
EMB_APP 0x8000{
CODE 0x8000
{
*(+RO)
}
# REGION1 的基址为 CODE的结尾
REGION1 +0 OVERLAY
{
module1.o(*)
}
# REGION2 的基址为REGION1的基址
REGION2 +0 OVERLAY
{
module2.o(*)
}
# REGION3 的基址和REGION2的基址相同
REGION3 +0 OVERLAY
{
module3.o(*)
}
# REGION4 的基址为 REGION3的结尾+4
Region4 +4 OVERLAY
{
module4.o(*)
}
}
4.12 预留一个空region
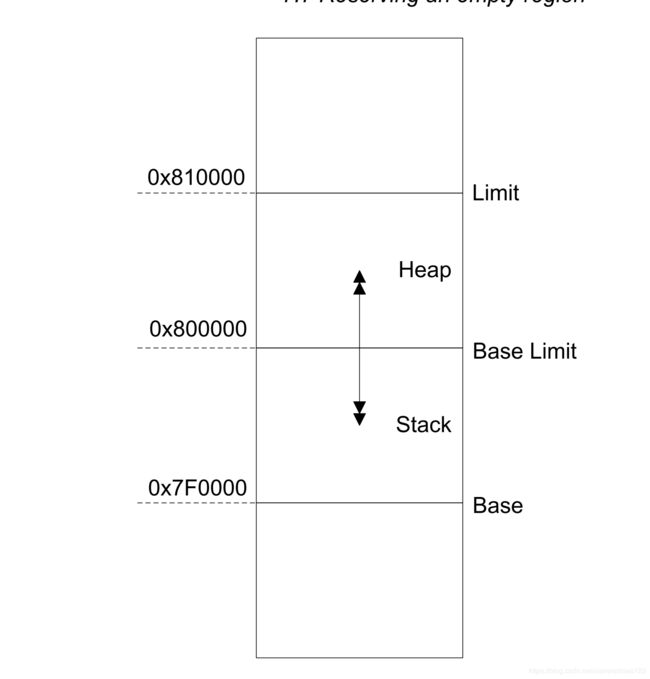
可以在scatter文件中,预留一个空的内存区域,比如:将此区域用于栈。使用EMPTY属性可以达到此效果。
为了预留一个空的内存用于栈。对应的加载region没有,执行region在执行时被分配。它被当做dummy ZI region对待,链接器使用下面的符号访问它:
1. Image$$region_name$$ZI$$Base
2. Image$$region_name$$ZI$$Limit
3. Image$$region_name$$ZI$$Length
注意:dummy ZI region 在运行时并不会被初始化为0
如果长度为负数,给定的地址就是结束地址。
例子如下:
LR_1 0x80000 ;加载region从0x80000开始
{
STACK 0x800000 EMPTY -0x10000 ;region 结束地址为0x800000,开始地址使用长度进行计算
{
;空region用于放置栈
}
HEAP +0 EMPTY 0x10000 ; region从上一个region结束处开始。
{
}
...
}
下图展示了这个例子:
4.13 c和c++ 库代码的放置
可以在scatter文件中,放置c和c++ 库代码。
在scatter文件中使用,*armlib* 或者 *cpplib* 来索引库名字。一些ARM c c++库的section必须放在root region中。例如:__main.o,__scatter*.o,__dc*.o,*Region$$Table.
链接器可以在InRoot$$Sections中自动的,可靠的,放置这些section。
例子1如下:
ROM_LOAD 0x0000 0x4000
{
ROM_EXEC 0x0000 0x4000 ; 在0x0处的root region
{
vectors.o (Vect, +FIRST) ; 向量表
* (InRoot$$Sections) ; 所有的库section 必须放置在root region中。如__main.o,__scatter*.o,__dc*.o,*Region$$Table
}
RAM 0x10000 0x8000
{
* (+RO, +RW, +ZI) ; 所有的其他的section
}
}
例子2:arm c库的例子
ROM1 0
{
* (InRoot$$Sections)
* (+RO)
}
ROM2 0x1000
{
*armlib/c_* (+RO) ; 所有arm支持的c库函数
}
ROM3 0x2000
{
*armlib/h_* (+RO) ; just the ARM-supplied __ARM_*
; redistributable library functions
}
RAM1 0x3000
{
*armlib* (+RO) ; 其他的arm支持的库,如,浮点库
}
RAM2 0x4000
{
* (+RW, +ZI)
}
名称ARM lib表示位于install_directory\lib\armlib目录中的ARM C库文件
例子3:arm c++ 库代码的放置
#include 为了放置c++ 库代码,定义如下的scatter文件
LR 0x0
{
ER1 0x0
{
*armlib*(+RO)
}
ER2 +0
{
*cpplib*(+RO)
*(.init_array) ; .init_array 必须显示放置,因为它被两个region共享,链接器无法决定怎么放置
}
ER3 +0
{
*(+RO)
}
ER4 +0
{
*(+RW,+ZI)
}
}
名称install_directory\lib\armlib表示位于armlib目录中的ARM C库文件
名称install_directory\lib\cpplib表示位于cpplib目录中的ARM c++库文件
4.14 scatter文件的预处理
在scatter文件的第一行,设置一个预处理命令。然后链接器会调用相应的预处理器先处理这个文件。预处理命令的格式如下:
#! preprocessor [pre_processor_flags]
最常见的预处理命令如下:
#! armcc -E
举例如下:
#! armcc -E
#define ADDRESS 0x20000000
#include "include_file_1.h"
lr1 ADDRESS
{
}
也可以在命令行中,进行预处理,如下:
armlink --predefine="-DADDRESS=0x20000000" --scatter=file.scat
armlink 系列完。
下一篇 从arm汇编到使用汇编点亮一个LED。