下面是今天的第二个爬虫,听名字就感觉比之前那个有意思了很多hhhhhhh。
```
from urllib import request
from urllib import parse
import json
url='http://fanyi.youdao.com/translate?smartresult=dict&smartresult=rule'
Form_Data={}
Form_Data['i']='love'
Form_Data['from']='Auto'
Form_Data['to']='Auto'
Form_Data['smartresult']='dict'
Form_Data['client']='fanyideskweb'
Form_Data['salt']='1510400502943'
Form_Data['sign']='dfdd0d2494764cd83f2cab4e39f29f85'
Form_Data['doctype']='json'
Form_Data['version']='2.1'
Form_Data['keyfrom']='fanyi.web'
Form_Data['action']='FY-BY-REALTIME'
Form_Data['typoResult']='flase'
data=parse.urlencode(Form_Data).encode('utf-8')
response=request.urlopen(url,data)
html=response.read().decode('utf-8')
translate_results=json.loads(html)
#translate_results=translate_results['translateResult'][0][0]['tgt']
print("翻译内容: %s" % (translate_results['translateResult'][0][0]['tgt']))
```
话说这个粘代码的到底怎么搞。。。
首先引入urllib库的request函数和parse函数。request函数之前已经提到过了,不过这次的调用与上次略有不同,稍后和parse函数还有jason库细讲。
下面打开有道页面,输入一个字并点翻译。介于今天是单身狗节,我输了一个love。
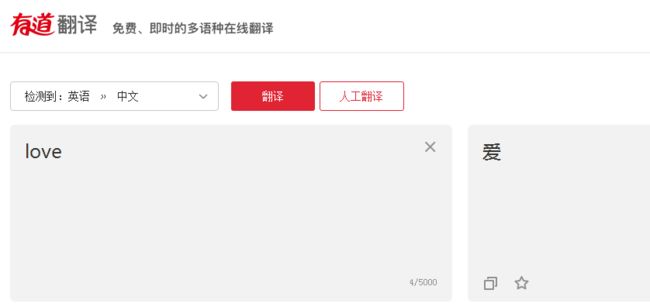
接下来右键——>检查/审查元素

点左边那栏那个translate_os?smartresult,然后就会出来右边那一堆东西。
点击Network——>Headers,下面需要留意一些东西:
1.General下显示本页面的url

2.Form Data

Form_Data={}用于创建一个字典,接下去那几行结构类似的代码均根据刚才Form Data那的值直接对字典中不存在的key进行赋值来添加。
字典属性的特性和操作网上的讲解太多啦不赘述了。
下面说一下urlopen的data参数
我们可以使用data参数,向服务器发送数据。根据HTTP规范,GET用于信息获取,POST是向服务器提交数据的一种请求,再换句话说:
从客户端向服务器提交数据使用POST;
从服务器获得数据到客户端使用GET(GET也可以提交,暂不考虑)。
如果没有设置urlopen()函数的data参数(就像之前我们的调用),HTTP请求采用GET方式,也就是我们从服务器获取信息,如果我们设置data参数,HTTP请求采用POST方式,也就是我们向服务器传递数据。
data参数有自己的格式,它是一个基于application/x-www.form-urlencoded的格式,具体格式我们不用了解, 因为我们可以使用urllib.parse.urlencode()函数将字符串自动转换成上面所说的格式。
可以说,urlencode()主要作用就是将url附上要提交的数据。Post的数据必须是bytes或者iterable of bytes,不能是str,因此需要进行encode()编码。这里提一下,在计算机内存中,统一使用Unicode编码,当需要保存到硬盘或者需要传输的时候,就转换为UTF-8编码。具体的字符编码的问题见这里:
www.liaoxuefeng.com/wiki/0014316089557264a6b348958f449949df42a6d3a2e542c000/001431664106267f12e9bef7ee14cf6a8776a479bdec9b9000
接下来读取信息并解码。JSON是一种轻量级的数据交换格式,我们需要从爬取到的内容中找到JSON格式的数据,这里面保存着我们想要的翻译结果,再将得到的JSON格式的翻译结果进行解析。

下面运行看看,一开始失败了,然后据说是有道改变了翻译接口现在爬不了了有点失望。但又看到说把url那里的_o去掉即可。试了一下果然可以。原因是现在抓包获取的请求地址有问题,不是最后的翻译接口,应该是后续需要处理,而有道翻译的处理恰好是去掉那_o。
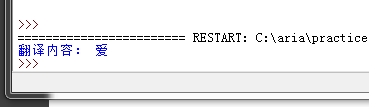
再多提一句json:
分别print(html)和print(translate_results)观察json的效果:

可以看到,通过loads的方法,把字符串转换成字典。
具体的在这里:www.cnblogs.com/bainianminguo/p/6676067.html