odps sql 窗口函数基础
窗口函数是一个查询利器,平时遇到棘手的问题,90%能够用窗口函数解决。
本篇内容主要介绍比较常用的窗口函数,看完这篇文章,基本能够解决大部分查询问题
本篇主要内容如下

本篇采用的数据集是 titanic的train.csv数据,截取前几行如下:
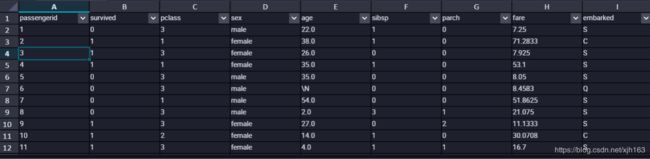
| 字段 | 含义 |
|---|---|
| passengerid | id |
| survived | 0 死亡 1 获救 |
| pclass | 船舱等级 |
| sex | 性别 |
| age | 年龄 |
| fare | 船票费用 |
1.排序函数

题目:不同性别下 年龄最大的人
SELECT sex
,age
,ROW_NUMBER()OVER(PARTITION BY sex ORDER BY age DESC) AS row_num
,RANK()OVER(PARTITION BY sex ORDER BY age DESC) AS rank_num
,dense_rank() OVER(PARTITION BY sex ORDER BY age DESC) AS dense_rank_num
FROM train
;
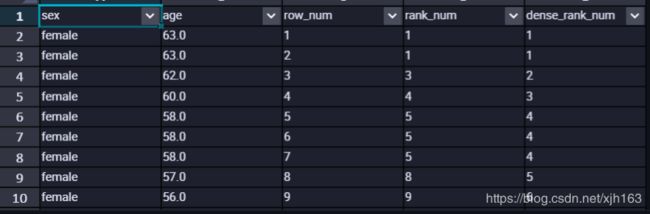
很容易看出区别:
row_number() over() 从1开始依次递增 1 2 3;
rank() over() 当出现重复时,排序也会重复,但占位 ;1 1 3
dense_rank() over() 当出现重复时,排序也会重复 但 不占位; 1 1 2
2.聚合函数
sum()over()主要用来求累计数量
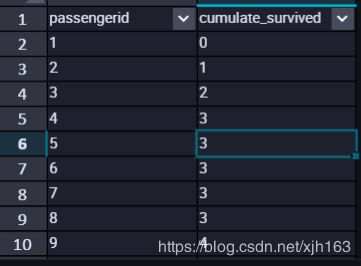
假设:passengerid 为统计的乘客id,survived=0代表死亡,survived=1代表获救
我们想知道截止到当前passengerid 有多少人获救
SELECT passengerid
,sum(survived)OVER(order by passengerid asc) AS cumulate_survived
FROM train
;
截止到当前passengerid 不同性别的有多少人获救:
SELECT passengerid
,sex
,sum(survived)OVER(PARTITION BY sex ORDER BY passengerid ASC) AS cumulate_survived
FROM train
;
截止目前获救的最大的年龄是多少
SELECT passengerid
,age
,max(age)OVER(ORDER BY passengerid ASC) AS max_age
FROM train
WHERE survived = 1
;
截止目前 不同性别获救的最大的年龄是多少
SELECT passengerid
,sex
,age
,max(age)OVER(PARTITION BY sex ORDER BY passengerid ASC) AS max_age
FROM train
WHERE survived = 1
;
其他聚合函数用法类似,不再赘述
3.分布函数

当前行占总行数的百分比(当前行数/总行数)
percent_rank()over() = (当前行-1)/(总行数-1)
cume_dist()over() = (当前行)/(总行数)
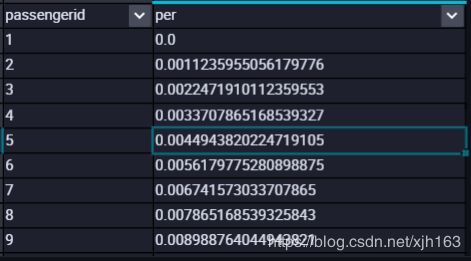
SELECT passengerid
,percent_rank()OVER(ORDER BY passengerid ASC) AS per
FROM train
;
SELECT passengerid
,cume_dist()OVER(ORDER BY passengerid ASC) AS per
FROM train
;

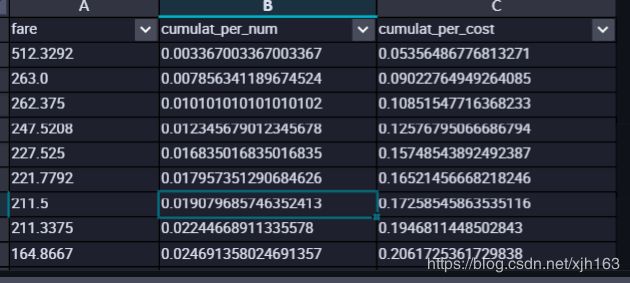
累计百分比的应用:我想看前XX%的用户贡献了XX%的总额
SELECT *
FROM (
SELECT fare
,cumulat_per_num
,max(cumulat_per_cost) AS cumulat_per_cost
FROM (
SELECT passengerid
,fare
,cume_dist()OVER(ORDER BY fare DESC) AS cumulat_per_num
,sum(fare)OVER(ORDER BY fare DESC )/sum(fare)OVER() AS cumulat_per_cost
FROM train
) AS a
GROUP BY fare
,cumulat_per_num
) AS b
ORDER BY cumulat_per_cost ASC
;
4.前后函数

这两个函数一般用来计算差值,埋点在上报的时候一般会上报时间戳,用户来到这个页面的时间,用户离开这个页面的时间,两个页面的时间相减,就是页面停留时长
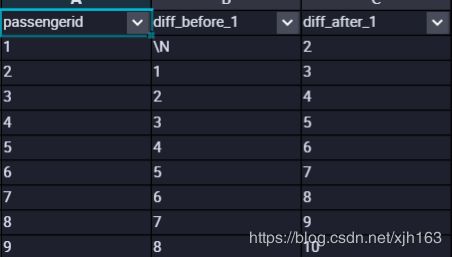
每个passengerid的前一个,后一个passengerid 各是多少
SELECT passengerid
,LAG(passengerid,1)OVER(ORDER BY passengerid ASC ) AS diff_before_1
,lead(passengerid,1)OVER(ORDER BY passengerid ASC ) AS diff_after_1
FROM train;
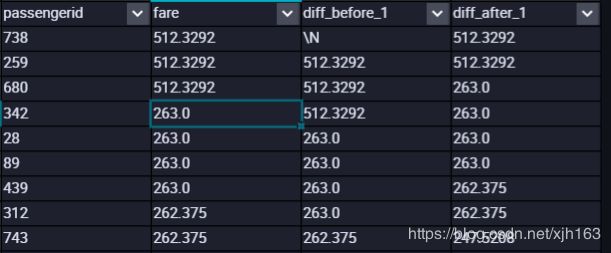
将fare 从高到低排序,看其前后各一位的fare是多少
SELECT passengerid
,fare
,LAG(fare,1)OVER(ORDER BY fare DESC ) AS diff_before_1
,lead(fare,1)OVER(ORDER BY fare DESC ) AS diff_after_1
FROM train
;
5.头尾函数

每种性别下 最大最小fare对应的passengerid
SELECT passengerid
,sex
,fare
,first_value(passengerid)OVER(PARTITION BY sex ORDER BY fare ASC) AS passengerid
,first_value(passengerid)OVER(PARTITION BY sex ORDER BY fare desc) AS passengerid
FROM train
WHERE survived = 1
;
6.其他函数

- nth_value
查询每个pclass中,每个fare 与该pclass中最高的fare的对比
SELECT passengerid
,pclass
,fare
,nth_value(fare,1)OVER(PARTITION BY pclass ORDER BY fare DESC) AS fare
FROM train
;
- NTILE
NTILE 函数将有序数据集划分为 expr 指示的若干桶,并为每一行分配适当的桶号。桶编号为 1 到 expr。 对于每个分区,expr 值必须解析为正常数。如果 expr 是一个非整数常量,则 OceanBase 将该值截断为整数。 返回值为 NUMBER。
根据fare分成三个等级
SELECT passengerid
,fare
,pclass
,ntile(3) OVER (ORDER BY fare DESC) AS self_class
FROM train
;
参考资料:
https://help.aliyun.com/document_detail/158535.html?spm=a2c4g.11186623.6.752.6a596dacVdBPWy