我分析的一道笔试题,留言说说你是否看懂了?
昨天的文章:3800 字 Python 流程控制专题总结
今天分析一道题:找到重复值和错误值
1 首先看题目
集合 S 包含从1到 n 的整数。不幸的是,因为数据错误,导致集合里面某一个元素复制了成了集合里面的另外一个元素的值,导致集合丢失了一个整数并且有一个元素重复。
给定一个数组 nums 代表了集合 S 发生错误后的结果。你的任务是首先寻找到重复出现的整数,再找到丢失的整数,将它们以数组的形式返回。
示例 1:
输入: nums = [1,2,2,4]
输出: [2,3]
注意:
给定数组的长度范围是 [2, 10000]。给定的数组是无序的。
链接:https://leetcode-cn.com/problems/set-mismatch
”
2 这是一类很具特色的数组
数组的取值范围:
其中,数组nums长度为n
这类数组特点鲜明,能够支持两种索引方法。
一种我们是熟知的线性访问方法:0到len(nums)-1或者逆序:
nums = [4,2,3,1] # 取值严格控制在:[1,len(nums)]
for i in range(len(nums)):
key = i
print(nums[key],end=" ") # 4 2 3 1
另一种,就是它的特色访问方法,支持通过下面极具特点的方式:
nums = [4,2,3,1]
for i in range(len(nums)):
key = nums[i]-1
print(nums[key],end=" ") # 遍历结果 1 2 3 4
访问数组的key等于元素值减去1
以后遇到满足取值满足 的这类数组,记住要联想到第二种访问方法,很多技巧都是基于这种访问方式。
3 详细分析过程
本题错误数据基于此种索引访问方法,能够精巧的求解,从而得到一个空间复杂度为O(1)的解,这太难能可贵了。
我看有的星友写出的解通过set集合方法,得到重复值,实际上set函数返回一个占用O(n)空间复杂度的对象,它不是更高效节省内存的解法。
下面分析怎么利用以上索引访问方法求解此题,原数组存在一对重复值,其他值都是唯一的。假定nums[i] 是重复值,则键 key 等于 nums[i] - 1 必然只存在一对重复值,其他值都唯一。
nums[key] 被遍历到后,我们乘以-1以此标记被访问到,因为key只有一对重复值,所以当第一次接触到这个key值时,我们标记nums[key]为负,再次接触到这个key值时,唯独nums[key]才能小于0,其他的key都不重复,所以再被标记为负值前都为正值,且以后再也没有机会被遍历到。
结论:满足 nums[key] < 0 时,key就是一对重复键,而key又等于abs(nums[i]) - 1,所以重复值为:abs(nums[i]) + 1.
找到重复值后,也就是我们只解码了一对重复key值的其中一个。
试想如果数组无错误,选用key = nums[i]-1遍历数组时,那么数组中所有元素都会被标记为负值。但是出现一对重复后,就会出现两个相等的key值,从而必然一个元素值无法被标记为负,拿个例子演示下:
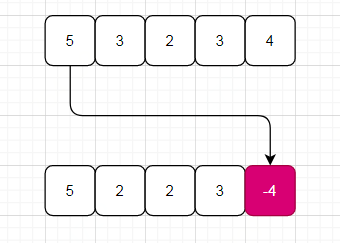
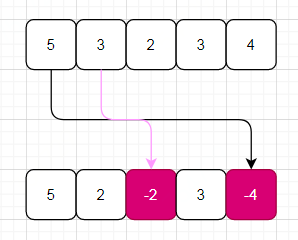
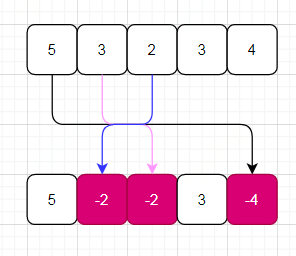
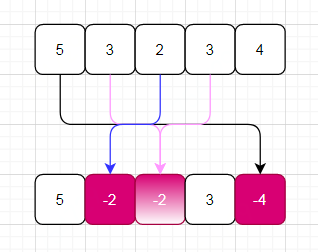 再次被标记,但是不再乘以-1
再次被标记,但是不再乘以-1
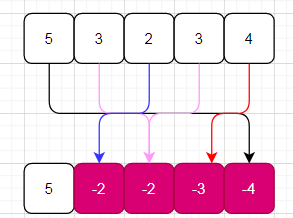
可以看到元素5未被标记,根据key值与元素值的映射关系: key = nums[i]-1, val = nums[key],元素5的key为0,所以nums[i] 等于key+1,即为 1,所以错误被标记的值为1。
再验证下,如果1未被错误标记,则key等于key 等于 1-1,即 nums[0]能被标记为负数,所以验证通过。
4 代码
理解以上后,很自然的就会写出下面的代码:
class Solution(object):
def findErrorNums(self, nums):
r = [0,0]
for i,num in enumerate(nums):
key = abs(num) - 1 # 减1防止越界,同时利用寻找重复值的特点来设计键
val = nums[key]
if val < 0: # 只有找到重复值时,条件才会满足
r[0] = key + 1
else:
nums[key] = -val # 数组取值范围[1,n],用乘以-1标记被访问过
for i,num in enumerate(nums): # 此时nums中只有一个值大于0,就是那个错值
if num > 0:
r[1] = i + 1
return r 《end》
欢迎加入星球,从零学程序员必备算法,每天在星球内记录学习过程、学习星友超赞的回答,还会不定期送精华资料!打卡 300 天,退还除平台收取的其他所有费用。

长按二维码,查看我的星球
原创不易,欢迎三连支持