Golang原理之goroutine与channel
常见并发编程模型分类
并发编程模型,顾名思义就是为了解决高并发充分利用多核特性减少CPU等待提高吞吐量而提出的相关的编程范式。目前为止,我觉得比较常见的并发编程模型大致可以分为两类:
- 基于消息(事件)的活动对象
- 基于CSP模型的协程的实现
其中基于消息(事件)的活动对象的并发模型,最典型的代表就是Akka的actor。actor的并发模型是把一个个计算序列按抽象为一个一个Actor对象,每一个Actor之间通过异步的消息传递机制来进行通讯。这样一来,本来顺序阻塞的计算序列,就被分散到了一个一个Actor中。我们在Actor中的操作应该尽量保证非阻塞性。当然,在akka中actor是根据具体的Dispatcher来决定如何处理某一个actor的消息,默认的dispatcher是ForkJoinExecutor,只适合用来处理非阻塞非CPU密集型的消息;akka中还有另外一些Dispatcher可以用于处理阻塞或者CPU密集型的消息,具体的底层实现用到CachedThreadPool。这两种Dispatcher结合起来,我们便能在jvm上建立完整的并发模型。
基于协程的实现,这里主要的代表就是goroutine。Golang的runtime实现了goroutine和OS thread的M:N模型,因此实际的goroutine是基于线程的更加轻量级的实现,我们便可以在Golang中大量创建goroutine而不用担心昂贵的context swtich所带来的开销。goroutine之间,我们可以通过channel来进行交互。由于go已将将所有system call都wrap到了标准库中,在针对这些systemcall进行调用时会主动标记goroutine为阻塞状态并保存现场,交由scheduler执行。所以在golang中,在大部分情况下我们可以非常安心地在goroutine中使用阻塞操作而不用担心并发性受到影响。
goroutine的这种并发模型有一个非常明显的优势,我们可以简单地使用人见人爱的阻塞编程方式来抒发异步的情怀,只要能合理运用go关键字。相比较于akka的actor而言,goroutine的程序可读性更强且更好定位错误。
goroutine特点
goroutine的并发模型定义为以下几个要点:
- 基于Thread的轻量级协程
- 通过channel来进行协程间的消息传递
- 只暴露协程,屏蔽线程操作的接口
goroutine原理
在操作系统的OS Thread和编程语言的User Thread之间,实际上存在3中线程对应模型,也就是:1:1,1:N,M:N。
N:1是说,多个(N)用户线程始终在一个内核线程上跑,context上下文切换确实很快,但是无法真正的利用多核。
1:1是说,一个用户线程就只在一个内核线程上跑,这时可以利用多核,但是上下文switch很慢,频繁切换效率很低。
M:N是说, 多个goroutine在多个内核线程上跑,这个看似可以集齐上面两者的优势,但是无疑增加了调度的难度。
goroutine google runtime默认的实现为M:N的模型,于是这样可以根据具体的操作类型(操作系统阻塞或非阻塞操作)调整goroutine和OS Thread的映射情况,显得更加的灵活。
在goroutine实现中,有三个最重要的数据结构,分别为G M P:
- G:代表一个goroutine
- M:代表 一个OS Thread
- P:一个P和一个M进行绑定,代表在这个OS Thread上的调度器
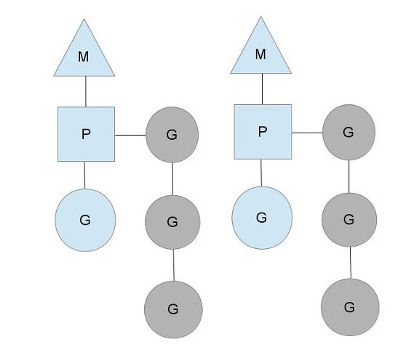
如上图所示,我们可以看到图中有两个M,即两个OS Thread线程,分别对应一个P,每一个P有负责调度多个G。如此一来,就组成的goroutine运行时的基本结构。
P的数量可以通过GOMAXPROCS()来设置,它其实也就代表了真正的并发度,即有多少个goroutine可以同时运行。
图中灰色的那些goroutine并没有运行,而是出于ready的就绪态,正在等待被调度。
P维护着这个队列(称之为runqueue),Go语言里,启动一个goroutine很容易:go function 就行,所以每有一个go语句被执行,runqueue队列就在其末尾加入一个goroutine,在下一个调度点,就从runqueue中取出(如何决定取哪个goroutine?)一个goroutine执行。
为何要维护多个上下文P?因为当一个OS线程被阻塞时,P可以转而投奔另一个OS线程!图中看到,当一个OS线程M0陷入阻塞时,P转而在OS线程M1上运行。调度器保证有足够的线程来运行所以的context P。
当MO返回时,它必须尝试取得一个context P来运行goroutine,一般情况下,它会从其他的OS线程那里steal偷一个context过来,如果没有偷到的话,它就把goroutine放在一个global runqueue里,然后自己就去睡大觉了(放入线程缓存里)。Contexts们也会周期性的检查global runqueue,否则global runqueue上的goroutine永远无法执行。
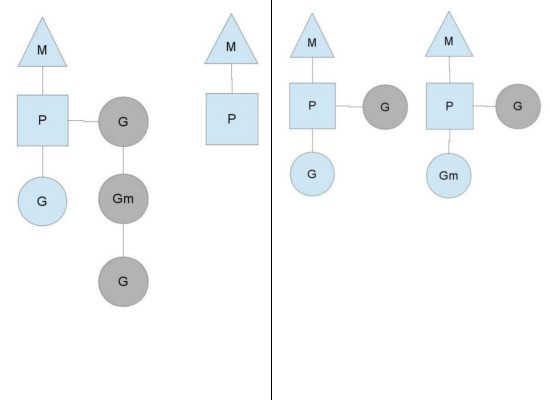
另一种情况是P所分配的任务G很快就执行完了(分配不均),这就导致了一个上下文P闲着没事儿干而系统却任然忙碌。但是如果global runqueue没有任务G了,那么P就不得不从其他的上下文P那里拿一些G来执行。一般来说,如果上下文P从其他的上下文P那里要偷一个任务的话,一般就‘偷’run queue的一半,这就确保了每个OS线程都能充分的使用。
下面我们对G M P的具体代码进行分析
struct G
{
uintptr stackguard0;// 用于栈保护,但可以设置为StackPreempt,用于实现抢占式调度
uintptr stackbase; // 栈顶
Gobuf sched; // 执行上下文,G的暂停执行和恢复执行,都依靠它
uintptr stackguard; // 跟stackguard0一样,但它不会被设置为StackPreempt
uintptr stack0; // 栈底
uintptr stacksize; // 栈的大小
int16 status; // G的六个状态
int64 goid; // G的标识id
int8* waitreason; // 当status==Gwaiting有用,等待的原因,可能是调用time.Sleep之类
G* schedlink; // 指向链表的下一个G
uintptr gopc; // 创建此goroutine的Go语句的程序计数器PC,通过PC可以获得具体的函数和代码行数
};
struct P
{
Lock; // plan9 C的扩展语法,相当于Lock lock;
int32 id; // P的标识id
uint32 status; // P的四个状态
P* link; // 指向链表的下一个P
M* m; // 它当前绑定的M,Pidle状态下,该值为nil
MCache* mcache; // 内存池
// Grunnable状态的G队列
uint32 runqhead;
uint32 runqtail;
G* runq[256];
// Gdead状态的G链表(通过G的schedlink)
// gfreecnt是链表上节点的个数
G* gfree;
int32 gfreecnt;
};
struct M
{
G* g0; // M默认执行G
void (*mstartfn)(void); // OS线程执行的函数指针
G* curg; // 当前运行的G
P* p; // 当前关联的P,要是当前不执行G,可以为nil
P* nextp; // 即将要关联的P
int32 id; // M的标识id
M* alllink; // 加到allm,使其不被垃圾回收(GC)
M* schedlink; // 指向链表的下一个M
};这里,G最重要的三个状态为Grunnable Grunning Gwaiting。具体的状态迁移为Grunnable -> Grunning -> Gwaiting -> Grunnable。goroutine在状态发生转变时,会对栈的上下文进行保存和恢复。下面让我们来开一下G中的Gobuf的定义
struct Gobuf
{
uintptr sp; // 栈指针
uintptr pc; // 程序计数器PC
G* g; // 关联的G
};当具体要保存栈上下文时,最重要的就是保存这个Gobuf结构中的内容。goroutine具体是通过void gosave(Gobuf*)以及void gogo(Gobuf*)这两个函数来实现栈上下文的保存和恢复的,具体的底层实现为汇编代码,因此goroutine的context swtich会非常快。
接下来,我们来具体看一下goroutine scheduler在几个主要场景下的调度策略。
goroutine将scheduler的执行交给具体的M,即OS Thread。每一个M就执行一个函数,即void schedule(void)。这个函数具体做得事情就是从各个运行队列中选择合适的goroutine然后执行goroutine中对应的func。
具体的schedule函数如下:
// 调度的一个回合:找到可以运行的G,执行
// 从不返回
static void schedule(void)
{
G *gp;
uint32 tick;
top:
gp = nil;
// 时不时检查全局的可运行队列,确保公平性
// 否则两个goroutine不断地互相重生,完全占用本地的可运行队列
tick = m->p->schedtick;
// 优化技巧,其实就是tick%61 == 0
if(tick - (((uint64)tick*0x4325c53fu)>>36)*61 == 0 && runtime·sched.runqsize > 0) {
runtime·lock(&runtime·sched);
gp = globrunqget(m->p, 1); // 从全局可运行队列获得可用的G
runtime·unlock(&runtime·sched);
if(gp)
resetspinning();
}
if(gp == nil) {
gp = runqget(m->p); // 如果全局队列里没找到,就在P的本地可运行队列里找
if(gp && m->spinning)
runtime·throw("schedule: spinning with local work");
}
if(gp == nil) {
gp = findrunnable(); // 阻塞住,直到找到可用的G
resetspinning();
}
// 是否启用指定某M来执行该G
if(gp->lockedm) {
// 把P给指定的m,然后阻塞等新的P
startlockedm(gp);
goto top;
}
execute(gp); // 执行G
}于是这里抛出几个问题:
- 当M发现分配给自己的goroutine链表已经执行完毕时怎么办?
- 当goroutine陷入系统调用阻塞后,M是否也一起阻塞?
- 当某个gorouine长时间占用CPU怎么办?
首先第一个问题,当M发现在P中的gorouine链表已经全部执行完毕时,将会从其他的P中偷取goroutine然后执行,其策略就是一个工作密取的机制。当其他的P也没有可执行的goroutine时,就会从全局等待队列中寻找runnable的goroutine进行执行,如果还找不到,则M让出CPU调度。
第二个问题,例如阻塞IO读取本地文件,此时调用会systemcall会陷入内核,不可避免地会使得调用线程阻塞,因此这里goroutine的做法是将所有可能阻塞的系统调用均封装为gorouine友好的接口。具体做法为,在每次进行系统调用之前,从一个线程池从获取一个OS Thread并执行该系统调用,而本来运行的gorouine则将自己的状态改为Gwaiting,并将控制权交给scheduler继续调度,系统调用的返回通过channel进行同步即可。因此,这里其实goroutine也没有办法做到完全的协程化,因为系统调用总会阻塞线程。具体可以参考stackoverflow上的讨论:链接
第三个问题,go支持简单的抢占式调度,在goruntime中有一个sysmon线程,负责检测goruntime的各种状态。sysmon其中一项职责就是检测是否有长时间占用CPU的goroutine,如果发现了就将其抢占过来。
其他语言协程库
- C libco-腾讯
- C++ libgo-魅族
- C tbox-国内开发者
- PHP Swoole coroutine
- Rust coroutine-rs-国内开发者
- C++ boost coroutine2
- C libtask
- C libmill
- 几种协程库性能比较
参考:
并发语法使用的技巧
goroutine原理讲解
goroutine是如何实现的
go-scheduler