ORACLE逗号分割的字符串转多行
分割单行数据
我们需要使用REGEXP_SUBSTR和REGEXP_COUNT两个ORACLE函数
function REGEXP_SUBSTR(string, pattern, position, occurrence, modifier)
string:需要进行正则处理的字符串
pattern:进行匹配的正则表达式
position:起始位置,从第几个字符开始正则表达式匹配(默认为1)
occurrence:标识第几个匹配组,默认为1
modifier:模式(‘i’不区分大小写进行检索;‘c’区分大小写进行检索。默认为’c’)
function REGEXP_COUNT ( string, pattern [, position [, match_param]])
返回pattern 在string串中出现的次数。如果未找到匹配,则函数返回0。position 变量告诉Oracle 在源串的什么位置开始搜索。在开始位置之后每出现一次模式,都会使计数结果增加1。
SELECT REGEXP_SUBSTR('B00053,D00058,D00094', '[^,]+', 1, LEVEL) VALUE
FROM DUAL
CONNECT BY LEVEL <= REGEXP_COUNT('B00053,D00058,D00094', '[^,]+')
分割后结果如下:
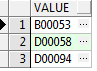
分割多行数据
我们有三行初始数据
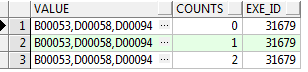
WITH TEMP AS
(SELECT T.VALUE, T.COUNTS, T.EXE_ID
FROM SC_MONIT_EXERESULT T
INNER JOIN SYS_TASK_EXECUTE A
ON T.EXE_ID = A.EXEC_ID
WHERE FIELD_CODE = 'fundList'
AND A.BUSIDATE = '20180604'
AND VALUE = 'B00053,D00058,D00094')
SELECT REGEXP_SUBSTR(VALUE, '[^,]+', 1, LEVEL) VALUE,
COUNTS,
EXE_ID
FROM TEMP
CONNECT BY LEVEL <= REGEXP_COUNT(VALUE, '[^,]+')
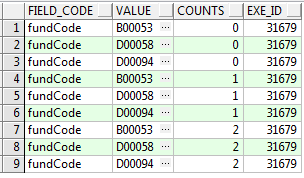
分割后数据变成了39行而不是9行!
问题出在使用connect by时,没有类似 id=prior pid的条件,而是 connect by rownum
F ( N , l ) = F ( N , l − 1 ) ∗ N + N F(N,l) = F(N,l-1)*N+N F(N,l)=F(N,l−1)∗N+N
l e v e l < = 3 level<=3 level<=3 时,递归查询到的树状结构:
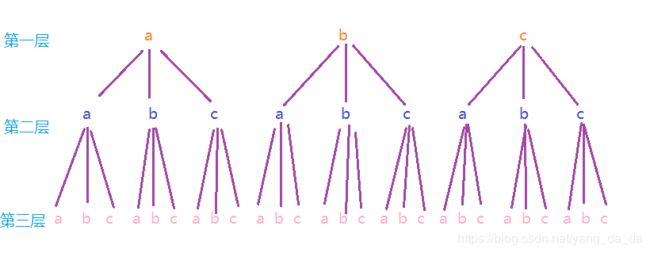
参考文章:深入理解connect by level
我们需要给树加上父子关系,用rownum作为PK列
WITH TEMP AS
(SELECT T.VALUE, T.COUNTS, T.EXE_ID, ROWNUM ROWNUM1
FROM SC_MONIT_EXERESULT T
INNER JOIN SYS_TASK_EXECUTE A
ON T.EXE_ID = A.EXEC_ID
WHERE FIELD_CODE = 'fundList'
AND A.BUSIDATE = '20180604'
AND VALUE = 'B00053,D00058,D00094')
SELECT 'fundCode' FIELD_CODE,
REGEXP_SUBSTR(VALUE, '[^,]+', 1, LEVEL) VALUE,
COUNTS,
EXE_ID
FROM TEMP
CONNECT BY PRIOR ROWNUM1 = ROWNUM1
AND LEVEL <= REGEXP_COUNT(VALUE, '[^,]+')
AND PRIOR DBMS_RANDOM.VALUE() IS NOT NULL
PRIOR DBMS_RANDOM.VALUE() IS NOT NULL告诉ORACLE每次循环是不一样的,不然会报connect by死循环
最后得到的结果: