Lucene之模糊、精确、匹配、范围、多条件查询-yellowcong
Lucene的查询方式很 丰富,对于数值类型的数据,采取TermRangeQuery的方式,对于String类型的,就可以采取TermQuery等,查询方式了,可以通过采取合适的查询方式,检索到数据。Queryparser这个查询方式包含了其他几种查询方式。
查询方式
| 查询方式 | 意义 |
|---|---|
| TermQuery | 精确查询 |
| TermRangeQuery | 查询一个范围 |
| PrefixQuery | 前缀匹配查询 |
| WildcardQuery | 通配符查询 |
| BooleanQuery | 多条件查询 |
| PhraseQuery | 短语查询 |
| FuzzyQuery | 模糊查询 |
| Queryparser | 万能查询(上面的都可以用这个来查询到) |
案例
package com.yellowcong.demo;
import java.io.File;
import java.io.IOException;
import java.util.ArrayList;
import java.util.Date;
import java.util.List;
import org.apache.lucene.analysis.standard.StandardAnalyzer;
import org.apache.lucene.document.Document;
import org.apache.lucene.document.Field;
import org.apache.lucene.document.IntField;
import org.apache.lucene.document.LongField;
import org.apache.lucene.document.StringField;
import org.apache.lucene.document.TextField;
import org.apache.lucene.index.IndexReader;
import org.apache.lucene.index.IndexWriter;
import org.apache.lucene.index.IndexWriterConfig;
import org.apache.lucene.index.Term;
import org.apache.lucene.search.FuzzyQuery;
import org.apache.lucene.search.IndexSearcher;
import org.apache.lucene.search.NumericRangeQuery;
import org.apache.lucene.search.PhraseQuery;
import org.apache.lucene.search.PrefixQuery;
import org.apache.lucene.search.Query;
import org.apache.lucene.search.ScoreDoc;
import org.apache.lucene.search.TermQuery;
import org.apache.lucene.search.TopDocs;
import org.apache.lucene.search.WildcardQuery;
import org.apache.lucene.store.FSDirectory;
import org.apache.lucene.util.Version;
/**
* 创建用户:狂飙的yellowcong
* 创建时间:下午5:27:50
* 创建日期:2017年12月2日
* 机能概要:
*/
public class Demo4 {
private static List psgList = null;
// 写对象
private static IndexWriter writer = null;
public static void main(String[] args) throws Exception {
// 删除 所有索引
deleteAll();
// 建立索引
index();
//精确String 类型查询
getByTermQuery();
//范围查询
getByRange();
//前缀匹配查询
getByPrefix();
//通配符查询
getByWildcard();
//短语查询
getByPhrase();
//模糊查询
getByFuzzy();
}
/**
* 创建用户:狂飙的yellowcong
* 创建日期:2017年12月3日
* 创建时间:下午12:00:43
* 机能概要:精确查询
* @throws Exception
*/
public static void getByTermQuery() {
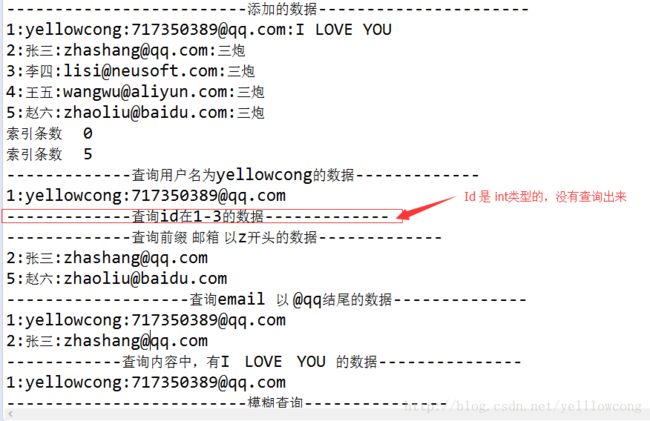
System.out.println("-------------查询用户名为yellowcong的数据-------------");
//精确查询,根据名称来直接
Query query = new TermQuery(new Term("username", "yellowcong"));
//执行查询
excQuery(query);
}
/**
* 创建用户:狂飙的yellowcong
* 创建日期:2017年12月3日
* 创建时间:下午12:25:21
* 机能概要:范围查询
*/
public static void getByRange(){
//精确查询
System.out.println("-------------查询id在1-3的数据-------------");
//查询前三条数据,后面两个true,表示的是是否包含头和尾
Query query = NumericRangeQuery.newIntRange("id", 1, 3, true, true);
//执行查询
excQuery(query);
}
/**
* 创建用户:狂飙的yellowcong
* 创建日期:2017年12月3日
* 创建时间:下午12:25:56
* 机能概要:前缀查询数据
*/
public static void getByPrefix(){
System.out.println("-------------查询前缀 邮箱 以z开头的数据-------------");
//查询前缀 邮箱 以z开头的数据
Query query = new PrefixQuery(new Term("email", "z"));
//执行查询
excQuery(query);
}
/**
* 创建用户:狂飙的yellowcong
* 创建日期:2017年12月3日
* 创建时间:下午12:29:55
* 机能概要:通配符查询数据
*/
public static void getByWildcard(){
//通配符就更简单了,只要知道“*”表示0到多个字符,而使用“?”表示一个字符就行了
System.out.println("-------------------查询email 以 @qq结尾的数据--------------");
//查询email 以 @qq结尾的数据
Query query = new WildcardQuery(new Term("email","*@qq.com"));
//执行查询
excQuery(query);
}
/**
* 创建用户:狂飙的yellowcong
* 创建日期:2017年12月3日
* 创建时间:下午12:43:43
* 机能概要:短语查询,查询中间有几个单词的那种
*/
public static void getByPhrase(){
System.out.println("------------查询内容中,有I LOVE YOU 的数据---------------");
//短语查询,但是对于中文没有太多的用,其中查询的时候还有
PhraseQuery query = new PhraseQuery();
//设定有几跳,表示中间存在一个单词
query.setSlop(1);
//查询
query.add(new Term("content","i"));
//I XX you 就可以被查询出来
query.add(new Term("content","you"));
excQuery(query);
}
/**
* 创建用户:狂飙的yellowcong
* 创建日期:2017年12月3日
* 创建时间:下午12:49:14
* 机能概要:默认提供的模糊查询对中文来说,没有任何用
* @throws Exception
*/
public static void getByFuzzy() throws Exception{
System.out.println("-------------------------模糊查询---------------");
FuzzyQuery query = new FuzzyQuery(new Term("username","zhangsan"));
excQuery(query);
}
/**
* 创建用户:狂飙的yellowcong
* 创建日期:2017年12月3日
* 创建时间:下午12:01:55
* 机能概要:查询Query 将需要查询的条件传递进来
* @param query
*/
public static void excQuery(Query query){
//查询
IndexReader reader = null;
try {
reader = getIndexReader();
//获取查询数据
IndexSearcher searcher = new IndexSearcher(reader);
//检索数据
TopDocs topDocs = searcher.search(query, 100);
for(ScoreDoc scoreDoc : topDocs.scoreDocs){
//湖区偶
Document doc = reader.document(scoreDoc.doc);
System.out.println(doc.get("id")+":"+doc.get("username")+":"+doc.get("email"));
}
} catch (Exception e) {
e.printStackTrace();
}finally{
coloseReader(reader);
}
}
/**
* 创建用户:狂飙的yellowcong
* 创建日期:2017年12月3日
* 创建时间:上午11:52:52
* 机能概要:关闭IndexReader
* @param reader
*/
private static void coloseReader(IndexReader reader) {
try {
if (reader != null) {
reader.close();
}
} catch (IOException e) {
e.printStackTrace();
}
}
static {
psgList = new ArrayList();
// 产生一堆数据
psgList.add(new Passage(1, "yellowcong" ,
"[email protected]", "逗比", 23 , "I LOVE YOU ", new Date()));
psgList.add(new Passage(2, "张三" ,
"[email protected]", "逗比", 23, "三炮", new Date()));
psgList.add(new Passage(3, "李四" ,
"[email protected]", "逗比", 23, "三炮", new Date()));
psgList.add(new Passage(4, "王五" ,
"[email protected]", "逗比", 23, "三炮", new Date()));
psgList.add(new Passage(5, "赵六" ,
"[email protected]", "逗比", 23, "三炮", new Date()));
System.out.println("-------------------------添加的数据----------------------");
for(Passage psg:psgList){
System.out.println(psg.getId()+":"+psg.getUsername()+":"+psg.getEmail()+":"+psg.getContent());
}
}
/**
* 创建用户:狂飙的yellowcong
* 创建日期:2017年12月2日
* 创建时间:下午5:43:57
* 机能概要:获取IndexWriter 同一时间 ,只能打开一个 IndexWriter,独占写锁 。内建线程安全机制。
*
* @return
* @throws Exception
*/
@SuppressWarnings("static-access")
public static IndexWriter getIndexWriter() throws Exception {
// 创建IdnexWriter
String path = getIndexPath();
FSDirectory fs = FSDirectory.open(new File(path));
// 判断资源是否占用
if (writer == null || !writer.isLocked(fs)) {
synchronized (Demo3.class) {
if (writer == null || !writer.isLocked(fs)) {
// 创建writer对象
writer = new IndexWriter(fs,
new IndexWriterConfig(Version.LUCENE_45, new StandardAnalyzer(Version.LUCENE_45)));
}
}
}
return writer;
}
/**
* 创建用户:狂飙的yellowcong
* 创建日期:2017年12月2日
* 创建时间:下午5:46:36
* 机能概要:获取到IndexReader 任意多个IndexReaders可同时打开,可以跨JVM。
*
* @return
* @throws Exception
*/
public static IndexReader getIndexReader() throws Exception {
// 创建IdnexWriter
String path = getIndexPath();
FSDirectory fs = FSDirectory.open(new File(path));
// 获取到读
return IndexReader.open(fs);
}
/**
* 创建用户:狂飙的yellowcong
* 创建日期:2017年12月2日
* 创建时间:下午7:57:04
* 机能概要:删除所有的索引
*/
public static void deleteAll() {
IndexWriter writer = null;
try {
// 获取IndexWriter
writer = getIndexWriter();
// 删除所有的数据
writer.deleteAll();
int cnt = writer.numDocs();
System.out.println("索引条数\t" + cnt);
// 提交事物
writer.commit();
} catch (Exception e) {
e.printStackTrace();
} finally {
coloseWriter(writer);
}
}
/**
* 创建用户:狂飙的yellowcong
* 创建日期:2017年12月2日
* 创建时间:下午5:37:22
* 机能概要:获取索引目录
*
* @return 目录
*/
private static String getIndexPath() {
// 获取索引的目录
String path = Demo3.class.getClassLoader().getResource("index").getPath();
// 不存在就创建目录
File file = new File(path);
if (!file.exists()) {
file.mkdirs();
}
return path;
}
/**
* 创建用户:狂飙的yellowcong
* 创建日期:2017年12月2日
* 创建时间:下午8:24:16
* 机能概要:关闭IndexWriter
*/
private static void coloseWriter(IndexWriter writer) {
try {
if (writer != null) {
writer.close();
}
} catch (IOException e) {
e.printStackTrace();
}
}
/**
* 创建用户:狂飙的yellowcong
* 创建日期:2017年12月2日
* 创建时间:下午8:26:15
* 机能概要:关闭IndexReader
*
* @param reader
*/
public static void closerReader(IndexReader reader) {
try {
if (reader != null) {
reader.close();
}
} catch (IOException e) {
e.printStackTrace();
}
}
/**
* 创建用户:狂飙的yellowcong
* 创建日期:2017年12月2日
* 创建时间:下午8:10:01
* 机能概要: 查询数据
*
* @param key
* 查询范围
* @param val
* 值
*/
public static void search(String key, Object val) {
IndexReader reader = null;
try {
reader = getIndexReader();
IndexSearcher searcher = new IndexSearcher(reader);
// 精确查询
Query query = null;
// 定义查询条件
if (val instanceof Integer) {
// 后面的两个true 表示的是 是否包含 上下的数据
query = NumericRangeQuery.newIntRange(key, Integer.parseInt(val.toString()),
Integer.parseInt(val.toString()), true, true);
} else {
query = new TermQuery(new Term(key, val.toString()));
}
// QueryParser paraser = new QueryParser(Version.LUCENE_45, key, new
// StandardAnalyzer(Version.LUCENE_45));
// Query query = paraser.parse(val);
// 获取查询到的Docuemnt
TopDocs topDocs = searcher.search(query, 500);
// 总共命中的条数
System.out.println(topDocs.totalHits);
for (ScoreDoc score : topDocs.scoreDocs) {
//
Document doc = searcher.doc(score.doc);
// 查询到的结果
String username = doc.get("username");
System.out.println(username);
}
} catch (Exception e) {
e.printStackTrace();
} finally {
closerReader(reader);
}
}
/**
* 创建用户:狂飙的yellowcong
* 创建日期:2017年12月2日
* 创建时间:下午6:03:33
* 机能概要:建立索引
*/
public static void index() {
IndexWriter writer = null;
try {
// 1、获取IndexWriter
writer = getIndexWriter();
// 2、建立索引
for (Passage psg : psgList) {
Document doc = new Document();
// IntField 不能直接检索到,需要结合
doc.add(new IntField("id", psg.getId(), Field.Store.YES));
// 用户String类型的字段的存储,StringField是只索引不分词
doc.add(new TextField("username", psg.getUsername(), Field.Store.YES));
// 主要对int类型的字段进行存储,需要注意的是如果需要对InfField进行排序使用SortField.Type.INT来比较,如果进范围查询或过滤,需要采用NumericRangeQuery.newIntRange()
doc.add(new IntField("age", psg.getAge(), Field.Store.YES));
// 对String类型的字段进行存储,TextField和StringField的不同是TextField既索引又分词
doc.add(new TextField("content", psg.getContent(), Field.Store.NO));
doc.add(new StringField("keyword", psg.getKeyword(), Field.Store.YES));
doc.add(new StringField("email", psg.getEmail(), Field.Store.YES));
// 日期数据添加索引
doc.add(new LongField("addDate", psg.getAddDate().getTime(), Field.Store.YES));
// 3、添加文档
writer.addDocument(doc);
}
// 索引条数
int cnt = writer.numDocs();
System.out.println("索引条数\t" + cnt);
// 提交事物
writer.commit();
} catch (Exception e) {
e.printStackTrace();
} finally {
coloseWriter(writer);
}
}
static class Passage {
private int id;
private String username;
private String email;
private String keyword;
private int age;
// 这个模拟的是文章
private String content;
private Date addDate;
public Passage(int id, String username, String email, String keyword, int age, String content, Date addDate) {
super();
this.id = id;
this.username = username;
this.email = email;
this.keyword = keyword;
this.age = age;
this.content = content;
this.addDate = addDate;
}
public int getId() {
return id;
}
public void setId(int id) {
this.id = id;
}
public String getUsername() {
return username;
}
public void setUsername(String username) {
this.username = username;
}
public String getEmail() {
return email;
}
public void setEmail(String email) {
this.email = email;
}
public String getKeyword() {
return keyword;
}
public void setKeyword(String keyword) {
this.keyword = keyword;
}
public int getAge() {
return age;
}
public void setAge(int age) {
this.age = age;
}
public String getContent() {
return content;
}
public void setContent(String content) {
this.content = content;
}
public Date getAddDate() {
return addDate;
}
public void setAddDate(Date addDate) {
this.addDate = addDate;
}
}
}
运行结果
Queryparser
通过Queryparaser直接就可以将上面的方法都包揽了
常用匹配
@Test
public void searchByQueryPhase() throws ParseException{
IndexUtils utls = new IndexUtils();
//设定默认搜索域,将默认搜索域 设定在Content
QueryParser parse = new QueryParser(Version.LUCENE_35, "content",new StandardAnalyzer(Version.LUCENE_35));
// parse.setDefaultOperator(Operator.AND);//将空格默认 定义为AND
parse.setAllowLeadingWildcard(true);//设定第一个* 可以匹配
Query query = parse.parse("yellow");
//其中空格默认就是OR
query = parse.parse("yellow cong");
//改变搜索域,搜索域 为 name
query = parse.parse("name:yellow1");
//使用通配符 , 设定查询类容为 以 y 开头的数据
query = parse.parse("name:y*"); //其中* 不可以放在字符串的首位
//将字符串放在首位,默认情况下回报错
query = parse.parse("email:*@yellow.com"); //其中我们可以更改 第一个通配值得功能
//其中 + - 表示有 和没有 其中需要有空格 ,而且第一个+ 或者 - 需要放在第一个位置
query = parse.parse("- content: cong + i "); //这个表示的是content 中不含有 cong ,但是含有i
//匹配区间, 其中TO 必须是大写的,还有有空格
query = parse.parse("id:[1 TO 4]"); //设定查询的Id为 1-4
//开区间匹配
query = parse.parse("id:(1 TO 4)");
//匹配连起来的String
query = parse.parse("\"I like yellow cong\""); //这个是查询的一个一个词 ,匹配String
//匹配一个或者多个数据
query = parse.parse("\"I cong\"~2"); //表示中间含有一个单词
//模糊查询
query = parse.parse("name:yellow~");
//匹配数字,这个方法中没有字符类容,所以需要自定义了
IndexReaderHelper.searchByQueryPhase(query, 10);
}案例
package com.yellowcong.demo;
import java.io.File;
import java.io.IOException;
import java.util.ArrayList;
import java.util.Date;
import java.util.List;
import org.apache.lucene.analysis.standard.StandardAnalyzer;
import org.apache.lucene.document.Document;
import org.apache.lucene.document.Field;
import org.apache.lucene.document.IntField;
import org.apache.lucene.document.LongField;
import org.apache.lucene.document.StringField;
import org.apache.lucene.document.TextField;
import org.apache.lucene.index.IndexReader;
import org.apache.lucene.index.IndexWriter;
import org.apache.lucene.index.IndexWriterConfig;
import org.apache.lucene.index.Term;
import org.apache.lucene.queryparser.classic.QueryParser;
import org.apache.lucene.search.FuzzyQuery;
import org.apache.lucene.search.IndexSearcher;
import org.apache.lucene.search.NumericRangeQuery;
import org.apache.lucene.search.PhraseQuery;
import org.apache.lucene.search.PrefixQuery;
import org.apache.lucene.search.Query;
import org.apache.lucene.search.ScoreDoc;
import org.apache.lucene.search.TermQuery;
import org.apache.lucene.search.TopDocs;
import org.apache.lucene.search.WildcardQuery;
import org.apache.lucene.store.FSDirectory;
import org.apache.lucene.util.Version;
/**
* 创建用户:狂飙的yellowcong
* 创建时间:下午5:27:50
* 创建日期:2017年12月2日
* 机能概要:
*/
public class Demo5 {
private static List psgList = null;
// 写对象
private static IndexWriter writer = null;
public static void main(String[] args) throws Exception {
// 删除 所有索引
deleteAll();
// 建立索引
index();
QueryParser parser = getQueryParser();
//将空格默认 定义为AND
// parse.setDefaultOperator(Operator.AND);
//设定第一个* 可以匹配
parser.setAllowLeadingWildcard(true);
//精确String 类型查询
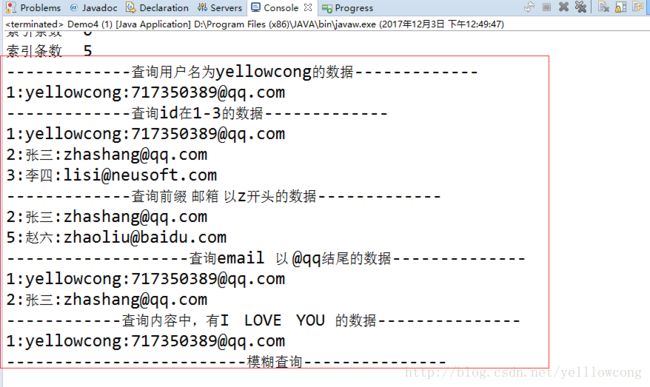
System.out.println("-------------查询用户名为yellowcong的数据-------------");
//精确查询,根据名称来直接
Query query = parser.parse("username:yellowcong");
//执行查询
excQuery(query);
//范围查询
System.out.println("-------------查询id在1-3的数据-------------");
//查询前三条数据,后面两个true,表示的是是否包含头和尾
//匹配区间, 其中TO 必须是大写的,还有有空格
query = parser.parse("id:[1 TO 3]"); //设定查询的Id为 1-4
//执行查询
excQuery(query);
//前缀匹配查询
System.out.println("-------------查询前缀 邮箱 以z开头的数据-------------");
//查询前缀 邮箱 以z开头的数据
query = parser.parse("email:z*");
excQuery(query);
//通配符查询
//通配符就更简单了,只要知道“*”表示0到多个字符,而使用“?”表示一个字符就行了
System.out.println("-------------------查询email 以 @qq结尾的数据--------------");
//查询email 以 @qq结尾的数据
//需要设定 * 可以放在前面 QueryParser.setAllowLeadingWildcard(true);
//将字符串放在首位,默认情况下回报错
query = parser.parse("email:*@qq.com");
excQuery(query);
//短语查询
System.out.println("------------查询内容中,有I LOVE YOU 的数据---------------");
//短语查询,但是对于中文没有太多的用,其中查询的时候还有
query =parser.parse("\"i you\"~2"); //表示中间含有一个单词
excQuery(query);
//模糊查询
System.out.println("-------------------------模糊查询---------------");
query = parser.parse("username:zhangsan~");
excQuery(query);
}
private static QueryParser getQueryParser(){
QueryParser parser =new QueryParser(Version.LUCENE_45,"content", new StandardAnalyzer(Version.LUCENE_45));
return parser;
}
/**
* 创建用户:狂飙的yellowcong
* 创建日期:2017年12月3日
* 创建时间:下午12:01:55
* 机能概要:查询Query 将需要查询的条件传递进来
* @param query
*/
public static void excQuery(Query query){
//查询
IndexReader reader = null;
try {
reader = getIndexReader();
//获取查询数据
IndexSearcher searcher = new IndexSearcher(reader);
//检索数据
TopDocs topDocs = searcher.search(query, 100);
for(ScoreDoc scoreDoc : topDocs.scoreDocs){
//湖区偶
Document doc = reader.document(scoreDoc.doc);
System.out.println(doc.get("id")+":"+doc.get("username")+":"+doc.get("email"));
}
} catch (Exception e) {
e.printStackTrace();
}finally{
coloseReader(reader);
}
}
/**
* 创建用户:狂飙的yellowcong
* 创建日期:2017年12月3日
* 创建时间:上午11:52:52
* 机能概要:关闭IndexReader
* @param reader
*/
private static void coloseReader(IndexReader reader) {
try {
if (reader != null) {
reader.close();
}
} catch (IOException e) {
e.printStackTrace();
}
}
static {
psgList = new ArrayList();
// 产生一堆数据
psgList.add(new Passage(1, "yellowcong" ,
"[email protected]", "逗比", 23 , "I LOVE YOU ", new Date()));
psgList.add(new Passage(2, "张三" ,
"[email protected]", "逗比", 23, "三炮", new Date()));
psgList.add(new Passage(3, "李四" ,
"[email protected]", "逗比", 23, "三炮", new Date()));
psgList.add(new Passage(4, "王五" ,
"[email protected]", "逗比", 23, "三炮", new Date()));
psgList.add(new Passage(5, "赵六" ,
"[email protected]", "逗比", 23, "三炮", new Date()));
System.out.println("-------------------------添加的数据----------------------");
for(Passage psg:psgList){
System.out.println(psg.getId()+":"+psg.getUsername()+":"+psg.getEmail()+":"+psg.getContent());
}
}
/**
* 创建用户:狂飙的yellowcong
* 创建日期:2017年12月2日
* 创建时间:下午5:43:57
* 机能概要:获取IndexWriter 同一时间 ,只能打开一个 IndexWriter,独占写锁 。内建线程安全机制。
*
* @return
* @throws Exception
*/
@SuppressWarnings("static-access")
public static IndexWriter getIndexWriter() throws Exception {
// 创建IdnexWriter
String path = getIndexPath();
FSDirectory fs = FSDirectory.open(new File(path));
// 判断资源是否占用
if (writer == null || !writer.isLocked(fs)) {
synchronized (Demo3.class) {
if (writer == null || !writer.isLocked(fs)) {
// 创建writer对象
writer = new IndexWriter(fs,
new IndexWriterConfig(Version.LUCENE_45, new StandardAnalyzer(Version.LUCENE_45)));
}
}
}
return writer;
}
/**
* 创建用户:狂飙的yellowcong
* 创建日期:2017年12月2日
* 创建时间:下午5:46:36
* 机能概要:获取到IndexReader 任意多个IndexReaders可同时打开,可以跨JVM。
*
* @return
* @throws Exception
*/
public static IndexReader getIndexReader() throws Exception {
// 创建IdnexWriter
String path = getIndexPath();
FSDirectory fs = FSDirectory.open(new File(path));
// 获取到读
return IndexReader.open(fs);
}
/**
* 创建用户:狂飙的yellowcong
* 创建日期:2017年12月2日
* 创建时间:下午7:57:04
* 机能概要:删除所有的索引
*/
public static void deleteAll() {
IndexWriter writer = null;
try {
// 获取IndexWriter
writer = getIndexWriter();
// 删除所有的数据
writer.deleteAll();
int cnt = writer.numDocs();
System.out.println("索引条数\t" + cnt);
// 提交事物
writer.commit();
} catch (Exception e) {
e.printStackTrace();
} finally {
coloseWriter(writer);
}
}
/**
* 创建用户:狂飙的yellowcong
* 创建日期:2017年12月2日
* 创建时间:下午5:37:22
* 机能概要:获取索引目录
*
* @return 目录
*/
private static String getIndexPath() {
// 获取索引的目录
String path = Demo3.class.getClassLoader().getResource("index").getPath();
// 不存在就创建目录
File file = new File(path);
if (!file.exists()) {
file.mkdirs();
}
return path;
}
/**
* 创建用户:狂飙的yellowcong
* 创建日期:2017年12月2日
* 创建时间:下午8:24:16
* 机能概要:关闭IndexWriter
*/
private static void coloseWriter(IndexWriter writer) {
try {
if (writer != null) {
writer.close();
}
} catch (IOException e) {
e.printStackTrace();
}
}
/**
* 创建用户:狂飙的yellowcong
* 创建日期:2017年12月2日
* 创建时间:下午8:26:15
* 机能概要:关闭IndexReader
*
* @param reader
*/
public static void closerReader(IndexReader reader) {
try {
if (reader != null) {
reader.close();
}
} catch (IOException e) {
e.printStackTrace();
}
}
/**
* 创建用户:狂飙的yellowcong
* 创建日期:2017年12月2日
* 创建时间:下午8:10:01
* 机能概要: 查询数据
*
* @param key
* 查询范围
* @param val
* 值
*/
public static void search(String key, Object val) {
IndexReader reader = null;
try {
reader = getIndexReader();
IndexSearcher searcher = new IndexSearcher(reader);
// 精确查询
Query query = null;
// 定义查询条件
if (val instanceof Integer) {
// 后面的两个true 表示的是 是否包含 上下的数据
query = NumericRangeQuery.newIntRange(key, Integer.parseInt(val.toString()),
Integer.parseInt(val.toString()), true, true);
} else {
query = new TermQuery(new Term(key, val.toString()));
}
// QueryParser paraser = new QueryParser(Version.LUCENE_45, key, new
// StandardAnalyzer(Version.LUCENE_45));
// Query query = paraser.parse(val);
// 获取查询到的Docuemnt
TopDocs topDocs = searcher.search(query, 500);
// 总共命中的条数
System.out.println(topDocs.totalHits);
for (ScoreDoc score : topDocs.scoreDocs) {
//
Document doc = searcher.doc(score.doc);
// 查询到的结果
String username = doc.get("username");
System.out.println(username);
}
} catch (Exception e) {
e.printStackTrace();
} finally {
closerReader(reader);
}
}
/**
* 创建用户:狂飙的yellowcong
* 创建日期:2017年12月2日
* 创建时间:下午6:03:33
* 机能概要:建立索引
*/
public static void index() {
IndexWriter writer = null;
try {
// 1、获取IndexWriter
writer = getIndexWriter();
// 2、建立索引
for (Passage psg : psgList) {
Document doc = new Document();
// IntField 不能直接检索到,需要结合
doc.add(new IntField("id", psg.getId(), Field.Store.YES));
// 用户String类型的字段的存储,StringField是只索引不分词
doc.add(new TextField("username", psg.getUsername(), Field.Store.YES));
// 主要对int类型的字段进行存储,需要注意的是如果需要对InfField进行排序使用SortField.Type.INT来比较,如果进范围查询或过滤,需要采用NumericRangeQuery.newIntRange()
doc.add(new IntField("age", psg.getAge(), Field.Store.YES));
// 对String类型的字段进行存储,TextField和StringField的不同是TextField既索引又分词
doc.add(new TextField("content", psg.getContent(), Field.Store.NO));
doc.add(new StringField("keyword", psg.getKeyword(), Field.Store.YES));
doc.add(new StringField("email", psg.getEmail(), Field.Store.YES));
// 日期数据添加索引
doc.add(new LongField("addDate", psg.getAddDate().getTime(), Field.Store.YES));
// 3、添加文档
writer.addDocument(doc);
}
// 索引条数
int cnt = writer.numDocs();
System.out.println("索引条数\t" + cnt);
// 提交事物
writer.commit();
} catch (Exception e) {
e.printStackTrace();
} finally {
coloseWriter(writer);
}
}
static class Passage {
private int id;
private String username;
private String email;
private String keyword;
private int age;
// 这个模拟的是文章
private String content;
private Date addDate;
public Passage(int id, String username, String email, String keyword, int age, String content, Date addDate) {
super();
this.id = id;
this.username = username;
this.email = email;
this.keyword = keyword;
this.age = age;
this.content = content;
this.addDate = addDate;
}
public int getId() {
return id;
}
public void setId(int id) {
this.id = id;
}
public String getUsername() {
return username;
}
public void setUsername(String username) {
this.username = username;
}
public String getEmail() {
return email;
}
public void setEmail(String email) {
this.email = email;
}
public String getKeyword() {
return keyword;
}
public void setKeyword(String keyword) {
this.keyword = keyword;
}
public int getAge() {
return age;
}
public void setAge(int age) {
this.age = age;
}
public String getContent() {
return content;
}
public void setContent(String content) {
this.content = content;
}
public Date getAddDate() {
return addDate;
}
public void setAddDate(Date addDate) {
this.addDate = addDate;
}
}
}